|
|
| |
DEFINIZIONI DI BASE
v Elaborazione: studio, progettazione, fabbricazione ed impiego degli elaboratori.
v Elaboratore: macchina elettronica automatica per il trattamento delle informazioni.
v Informazione: come riduzione di incertezza su una determinata configurazione come scelta tra possibili alternative (almeno 2).
v Unità elementare d'informazione (bit): quantità d'informazione che si ottiene selezionando da un insieme che ne contiene almeno due (esempio risposta si/no ad una domanda).
v Dato: informazione codificata in modo tale da poter essere elaborata rappresentazione di un'informazione.
v Informazioni: istruzioni che costituiscono i programmi e i dati che vengono elaborati mediante tali programmi.
Dal punto di vista dell'informatica, i dati in se non hanno alcun significato non interessa il significato di ciò che è rappresentato; una configurazione può portare informazione a colui che la osserva pur non significando nulla (accezione sintattica del concetto di informazione). L'interpretazione dei dati è un'attività dell'uomo, non dell'elaboratore.
Per l'elaborazione di un'informazione:
si parte da un problema;
si ottengono entità di informazione rilevanti in tale problema;
si effettua l'elaborazione il risultato è interpretabile in termini di proprietà delle cose: è ottenuto attraverso regole, generali ed indipendenti dalla natura delle cose.
L'elaborazione automatica si riferisce a:
problemi complessi, grandi masse di dati;
esigenza di rapidità nell'elaborazione.
In particolare problemi di:
videoscrittura;
gestione di basi dati;
elaborazione statistica dei dati.
Definizione di elaboratore: un elaboratore è una macchina che, sotto il controllo di un programma memorizzato, accetta ed elabora automaticamente dei dati e fornisce i risultati di tale elaborazione.
Questa definizione contiene tutte le caratteristiche dell'elaboratore, che sono:
hardware: insieme di componenti fisici dell'elaboratore;
software: insieme di programmi che controllano il funzionamento dell'elaboratore;
dispositivi di input: (tastiera, mouse, lettori ottici, ecc.) immissioni delle informazioni;
processore: componente dedicata all'esecuzione dei programmi ed al coordinamento di tute le altre componenti;
memoria: luogo in cui il processore trova i programmi ed i dati quando sta svolgendo una determinata operazione; nella memoria sono conservate tutte le informazioni (programmi e dati) su cui si sta lavorando;
dispositivi di output: (video, stampanti, dischetti, ecc.) scrittura dei risultati dell'elaborazione.
SCHEMA CONCETTUALE DELL'ARCHITETTURA DI UN ELABORATORE
Schema di Von Neumann.
Sistema
costituito da 3 sottosistemi connessi.
|
|
|
Il sottosistema di memoria può contenere indifferentemente istruzioni e dati; il sottosistema di elaborazione (unità centrale di elaborazione CPU) opera in modo sequenziale (per superare l'impostazione sequenziale, si sta sviluppando un sistema di elaborazione parallela che aumenta la velocità). Il sottosistema di elaborazione lavora leggendo dalla memoria un'istruzione e gli eventuali dati su cui lavorare, esegue l'istruzione e poi procede analogamente per le istruzioni successive. Le istruzioni non sono codificate nella struttura fisica del sistema, ma sono "caricate" nella memoria (attraverso l'interfaccia) il programma non fa parte dei componenti hardware del sistema ma è software.
L'interfaccia legge i dati dell'utente e restituisce le informazioni dopo le elaborazioni.
Dati e istruzioni sono software e non hardware, quindi ogni macchina può risolvere un problema se ha un determinato programma, non è quindi necessaria una macchina diversa per ogni problema diverso.
I dati possono essere:
dati digitali: ogni informazione è rappresentata in quantità discrete, tramite un opportuno codice numerico (codice binario presenza 1 assenza 0 di un campo elettrico);
dati analogici: ogni informazione è rappresentata tramite il valore di una grandezza fisica che varia in modo continuo (entità del segnale elettrico).
Il sistema di codifica più utilizzato è quello digitale; si parla ifatti di elaboratori digitali. I dati e le informazioni possono essere codificati in formato digitale, così che uno stesso dispositivo può memorizzare entrambi.
Un altro elemento importante della diffusione dell'elaboratore è la facilità d'uso, che si traduce nell'interfaccia.
In base ai caratteri ed alle prestazioni i sistemi inforamtici si dividono in:
Personal computer (PC): sono calcolatori dedicati all'uso personale (un solo utente). Basso costo ed elevata potenzialità hanno favorito la sua grande diffusione. La sua architettura è di tipo modulare, fa si che il PC sia facile da assemblare, inoltre consente di aggiungere altri moduli per migliorarne le prestazioni. L'aerchitettura modulare prevede una versione base (prestazioni necessarie a soddisfare un utente medio) con alcuni moduli che ne migliorano le prestazioni o che lo specializzano. L'elevata potenzialità di sviluppo, anche futuro, è favorita dalla rapidità nell'evoluzione e dalla riduzione dei costi. I PC possono essere da tavolo (desktop/tower) o portatili (notebook).
I suoi impieghi sono molteplici ed in rapida estensione (in corrispondenza all'aumento delle potenzialità del PC); ad esempio:
a) attività di segretariato e catalogazione documenti;
b) attività gestionale e di gestione della contabilità aziendale;
c) edizione testi (anche a livello professionale);
d) gestione di banche dati;
e) elaborazioni statistiche (di routine e di ricerca scientifica).
Con il collegamento il rete, è possibile sfruttare risorse comuni (dati e programmi). Il collegamento può essere:
alla pari: tutti i PC hanno le medesime funzionalità (esempio 2 PC ed una stampante);
client/server: si ha un PC principale, detto server, mentre gli altri PC, detti client, sono solo dei terminali remoti del server.
Stazioni di lavori (work station): sono calcolatori dedicati all'uso personale o di pochi utenti, per le applicazioni scientifiche o professionali che richiedono elevate capacità, risoluzione grafica e velocità di calcolo (ad esempio progettazione ingegneristica, elaborazione statistica, simulazione di sistemi di medie dimensioni). Prestazioni e costi sono superiori al PC, ma tenderanno a sparire data l'evoluzione di questi.
Minicalcolatori: si differenziano
dalle stazioni di lavoro soprattutto nel numero di utenti previsti, questi
infatti sono calcolatori orientati a servire contemporaneamente un numero di
utenti elevato. Impieghi: situazioni in cui è necessario condividere programmi
e dati comuni ( ad esempio filiali di una banca, settore amministrativo di
un'impresa di medie dimensioni).
Mainframe: calcolatori di grandi dimensioni con prestazioni notevoli soprattutto per quanto riguarda la possibilità di gestire un elevato numero di terminali (video + tastiera), ed il mantenimento di archivi di grandi dimensioni (tramite dischi). Sono usati per la gestione di grandi sistemi aziendali, che coinvolgono enormi basi dati (ad esempio aggiornamenti archivi bancari, gestione delle prenotazioni dei voli aerei).
Supercalcolatori: sono calcolatori progettati per massimizzare il numero
di operazioni di calcolo svolte nell'unità di tempo, si ha l'elaborazione
parallela di più operazioni. Hanno un elevato contenuto tecnologico e
necessitano di programmi particolari ed altamente specializzati. Sono molto
elevati i costi e gli oneri di gestione. Impieghi: elaborazione di modelli matematici,
fisici e statistici molto complessi. Tipicamente, questi calcolatori, sono
acquistati da centri di calcolo esterni che gestiscono il sistema e forniscono
i servizi alle aziende/università interessate (ad esempio elaboratore CRAY
presso il CINECA di Bologna).
Sistemi multiprocessore: si tratta di architetture di elaborazione che permettono la reale esecuzione di più attività in parallelo a livello di dispositivi fisici. Obiettivo: il tempo necessario per l'esecuzione deve essere pari al tempo impiegato per eseguire l'attività più lenta e non la somma dei tempi necessari per eseguire tutte le attività in serie (tecnica della "pipeline": catena di montaggio). Tecnologia più diffusa: connettere tra loro molti piccoli calcolatori sistemi multiprocesso in cui le funzioni da svolgere sono distribuite tra i diversi elaboratori. Le prestazioni sono molto elevate ed i costi sono inferiori rispetto a quelli dei supercalcolatori. Il problema principale è la suddivisione ottimale delle funzioni da svolgere tra le diverse unità, cioè minimizzare le interazioni.
Il nostro studio sarà riferito ai Personal Computer. Le fasi principali del funzionamento di queste macchine sono:
Fase di trasferimento dei dati dall'utente al calcolatore e pi da calcolatore all'utente (input/output);
Fase di elaborazione calcolo;
Fase di memorizzazione, che può essere:
di breve periodo;
di lungo periodo.
Esiste anche una quarta fase che coordina e controlla le altre.
Il calcolatore è un dispositivo polivalente che garantisce:
flessibilità nel calcolo: capacità di svolgere compiti diversi;
modularità dell'architettura: ogni componente (modulo) svolge una funzione specifica del sistema complessivo (Plug & Play standard);
scalabilità dei componenti: ogni componente può essere sostituito da uno funzionalmente equivalente ma in grado di fornire prestazioni più elevate;
standardizzazione dei componenti: prodotti su larga scala;
semplicità d'installazione e disponibilità di applicazioni a basso costo.
L'hardware è l'architettura elettronica e meccanica che costituisce il PC più gli accessori; sono i componenti fisici necessari allo svolgimento delle funzioni del calcolatore.
All'interno del calcolatore è presente una superficie di materiale plastico, detta scheda madre, su cui sono montati:
il processore CPU;
la memoria centrale;
alcune interfaccia di input/output (tastiera e mouse).
Altri dispositivi di interfaccia non presenti sulla scheda madre, sono realizzati su schede separate, più piccole, che vengono inserite in appositi alloggiamenti, detti connettori, montati sulla scheda madre. Sulla scheda madre si trova anche il bus: linea a cui sono contemporaneamente connesse le unità del calcolatore e che consente il trasferimento dei dati tra tali unità. La CPU gestisce l'intero sistema e l'accesso al bus (master); mentre l'attività delle periferiche è coordinata dalla CPU.
Componenti hardware di base:
dispositivi di input (tastiera, mouse, scanner, lettori ottici, Cd ROM, ecc.);
dispositivi di output (video, stampanti);
dispositivi di memorizza 737i86h zione temporaneo o permanente, che consentono di caricare e salvare dati e programmi;
processore;
un bus o una serie di bus che collegano il processore alla memoria e agli adattatori e che consentono di comunicare con gli altri dispositivi attraverso apposite porte, o slot, di espansione. Il bus può essere suddiviso, in base alle funzioni svolte, in tre componenti:
bus dati;
bus indirizzi (contiene gli indirizzi delle celle di memoria);
bus di controllo.
I principali tipi di bus sono: ISA (standard) e PCI (ad alta velocità);
una serie di adattatori, circuiti hardware che consentono al processore di comunicare con i dispositivi di input/output: sono ponti tra il bus del PC ed il dispositivo collegato al PC;
una serie di porte, interfacce hardware presenti sugli adattatori che supportano il collegamento dei dispositivi di input/output;
una serie di slot di espansione: connettori che accolgono gli adattatori collegati ai bus del PC e che consentono, in modo semplice e rapido, di installare nel computer ulteriori dispositivi. L'aggiornamento del sistema avviene tramite il collegamento di nuovi dispositivi di input/output e di memoria addizionale;
dispositivi di memorizza 737i86h zione a bassa velocità, per la registrazione permanente di dati e programmi (dischi fissi, CD ROM, dischetti).
In particolare:
Visualizza i comandi dell'utente al calcolatore ed i risultati dell'elaborazione. Nei computer da tavolo, il video è costituito da un tubo di raggi catodici (CRT); c'è analogia con la televisione ma, nei PC, si ha maggiore risoluzione e velocità di visualizzazione di dati. Lo schermo è costituito da una matrice di dati elementari detti pixel (picture elements): maggiore è il numero dei pixel, maggiore è la risoluzione e maggiore è la definizione delle immagini. Gli standard attuali sono:
1024 * 768 pixel (768 linee orizzontali con 1024 punti);
1280*1024 pixel (1024 linee orizzontali con 1280 punti).
Uno schermo, ad esempio, 4096*4096 è definito ad alta risoluzione ma i costi sono molto elevati.
La dimensione di un pixel è definita dot pich ed è solitamente espressa in millimetri; gli attuali standard sono 0.39 e 0.22 mm., a valori più piccoli corrispondono costi più elevati.
Nei PC portatili il video utilizza tecnologie basate sui cristalli liquidi (LCD). Le caratteristiche sono basso peso ed ingombro, limitato consumo di energia, ma minore qualità dell'immagine rispetto ai video CRT. Un tipo particolare di video è quello LCD a matrice attiva: sono più costosi ed hanno un maggiore consumo di potenza, ma i colori sono più brillanti e si ha un migliore angolo visuale e una bassa persistenza delle immagini sullo schermo.
La dimensione dello schermo è rappresentata dalla lunghezza della diagonale (in pollici) tra due angoli opposti (ad esempio 14, 15, 17 pollici).
Sono i dispostiti attraverso i quali l'utente fornisce i comandi all'elaboratore. L'impiego del mouse è legato all'avvento dell'interfaccia utente di tipo grafico, la quale visualizza sullo schermo dei riferimenti (menù, icone) ai comandi che possono essere eseguiti.
Nei PC da tavolo il mouse è una piccola scatola di plastica esterna al calcolatore, il cui movimento sul piano d'appoggio determina quello del puntatore (tipicamente una freccia) sullo schermo. Nella parte superiore del mouse ci sono 1, 2 o 3 tasti utilizzati per selezionare i comandi.
Nei PC portatili, sono implementati dispositivi di puntamento equivalenti al mouse. Si può avere il "track ball" che è una sorta di mouse rovesciato il cui si muove direttamente la pallina che genera il movimento; il "touchpad" che è una piccola superficie accanto alla tastiera in cui in cui una matrice di sensori rileva il movimento del polpastrello.
Le stampanti possono essere:
ad aghi: si ha lo scorrimenti, lungo la linea di stampa, di una testina di scrittura i cui aghi premono sulla carta un nastro d'inchiostro. I caratteri sono ottenuti tramite opportune configurazioni di punti sulla carta. Queste stampanti sono economiche ma tecnologicamente obsolete, lente, rumorose e la qualità di stampa non è eccelsa. Gli impieghi attuali sono: stampa su carta a modulo continuo e stampa contemporanea di più moduli attraverso ricalco.
a getto di inchiostro: anch'esse stampano caratteri composti da configurazioni di separati punti, che trasferiscono sulla carta delle gocce di inchiostro tramite gli ugelli della testina di scrittura. Queste stampanti sono economiche, silenzionse, la qualità di stampa è disceta inoltre permettono la stampa a colori a costi bassi. Sono lente e non adatte all'uso professionale.
laser: l'immagine delle pagine da stampare è impressa, da un raggio laser, su un rullo di materiale fotosensibile; le zone raggiunte dal laser sono caricate con una tensione di circa 100 volt, queste zone attirano le particelle di inchiostro in polvere (toner) che sono fissate sulla carta tramite riscaldamento (analogia con le fotocopiatrici). Le dimensioni del fascio emesso dal raggio laser sono molto ridotte, questo permette elevata risoluzione e qualità di stampa. Queste stampanti sono dotate di un proprio processore e di una propria memoria per generare una mappa di caratteri che rappresentano l'immagine da stampare. Le caratteristiche sono: alta qualità (anche per uso professionale), buona velocità, costi non eccessivi, ma richiedono una manutenzione più frequente e costosa rispetto alle altre stampanti.
Modem(modulatore/demodulatore): è il dispositivo che permette di trasferire dati tra elaboratori, utilizzando la linea telefonica tradizionale. Le sue funzioni sono:
trasformare i segnali digitali del computer in segnali analogici (modulazione del segnale) ed inviarli alla linea telefonica; operazione effettuata dal modem del PC che trasmette i dati;
ricevere i segnali analogici dalla linea telefonica e ritrasformarli nei corrispondenti segnali digitali (demodulazione del segnale); operazione effettuata dal modem del PC che riceve i dati.
Le prestazioni del modem sono misurate in base alla velocità di trasmissione (bit al secondo). Il modem può essere esterno (dispositivo autonomo da connettere al PC) od interno al PC.
Porte ed adattatori: sono dispositivi che permettono al processore di comunicare con i dispositivi di input ed output. Possono essere:
porte seriali: i dati sono inviati attraverso il cavo uno alla volta (flusso seriale), ad esmpio la porta del mouse;
porte parallele: i dati sono inviati 8 bit alla volta (su fili paralleli) il trasferimento è più veloce, ad esempio la porta della stampante.
Processore: è l'unità centrale del PC, svolge tutte le fasi necessarie all'elaborazione dei dati. È l'unica componente del PC che è in grado di distinguere le istruzioni dai dati (i dati e le istruzioni sono memorizzati assieme -in codice binario- senza distinzione). Il processore opera ciclicamente, fino all'esecuzione dell'ultima istruzione. Le operazioni di base sono:
lettura (fetch): acquisizione dalla memoria di un'istruzione del programma;
decodifica (decode): identificazione del tipo d'istruzione;
esecuzione (execute): esecuzione delle operazioni corrispondenti all'istruzione, compreso l'eventuale recupero dei dati dalla memoria.
Il linguaggio adottato dal processore è il linguaggio macchina; è molto rudimentale, sono possibili istruzioni molto elementari. È un linguaggio incomprensibile all'uomo in quanto è totalmente orientato alla macchina. In questo linguaggio sono scritte le istruzioni che controllano il funzionamento del processore. Lo svantaggio è che è specifico di ogni macchina.
![]()
![]()
![]()
![]()
![]() Schema di un
processore:
Schema di un
processore:
Bus interno di indirizzi e dati Unità di memoria Unità di Input/Output
![]()
Unità
di controllo
![]()
![]()
![]()
![]()
![]()
In questo schema ci sono tre componenti funzionali:
bus dati: trasferisce i dati dalla memoria alla CPU e viceversa;
bus indirizzi: identifica la posizione della cella di memoria in cui la CPU deve andare a leggere/scrivere;
bus di controllo: coordina il sistema, attraverso segnali di controllo (esempio quale operazione svolgere, quale unità sorgente/destinazione).
Sottosistemi principali nella struttura di un processore
Unità aritmetico- logica ALU: effettua le operazioni di tipo aritmetico (somma, sottrazioni) e di tipo logico (and, or). Esegue un certo insieme di operazioni selezionabili tramite comandi dall'esterno.
Unità di controllo: coordina le varie unità nell'esecuzione dei programmi (lettura dalla memoria, decodifica ed esecuzione delle istruzioni).
Registri: celle di memoria interne al processore che memorizzano gli operandi delle operazioni logico aritmetiche e le informazioni di controllo sulle operazioni eseguite. Sono variabili come numero e come denominazione. In particolare, sono sempre presenti i registri:
contatore: può essere di programma o delle istruzioni; indica qual è la prossima istruzione da eseguire.
delle istruzioni IR: contiene una copia dell'istruzione da eseguire.
di indirizzo di memoria MAR: contiene l'indirizzo di memoria del dato da leggere o scrivere.
dati di memoria MDR: contiene una copia del dato effettivo.
parola di stato del processore PSW: da indicazioni sulle modalità di funzionamento del processore.
Per maggiori dettagli testo pag. 67-69
Oltre al processore, può essere presente un coprocessore matematico, che è un processore ausiliario, dedicato allo svolgimento delle operazioni di tipo matematico. In realtà è utile nell'esecuzione di qualunque programma, infatti è ormai installato automaticamente su tutti i PC in quanto migliora le prestazioni del processore principale. Oltre ai coprocessori matematici, ci sono anche quelli grafici.
Tipi di processori:
Processori X86: famiglia di processori Intel, a partire da processore 8086 alla fine del 1970.
Pentium: processore Intel 586 (3.1 milioni di transistor in uno spazio di 2 cm2).
Pentium II: 7.5 milioni di transistor in uno spazio di 2 cm2.
Processori RISC: sono diversi dai pentium e di solito sono montati sulle workstation.
Misurazione delle prestazioni di un processore
Queste sono misurate dai seguenti indicatori:
Elapsed time: tempo complessivo dell'elaborazione;
Tempo di CPU: tempo effettivo di elaborazione, esclusi i tempi di attesa dovuti alle operazioni di Input/Output, o all'esecuzione di altri processi;
Cicli di clock: impulsi elettrici ad intervalli regolari molto ravvicinati nel tempo; determinano il funzionamento e la velocità del processore (clock è l'orologio che fornisce la cadenza temporale in base al quale le attività elementari sono sincronizzate).
Frequenza di clock: è misurata in Mhz (milioni di cicli di clok al secondo), rappresenta il numero di cicli di clock necessari per il compimento del processo, diviso il tempo di CPU del processo stesso; rappresenta il numero di attivià elementari eseguite nell'unità di tempo. Quantifica le prestazioni di un processore: tanto maggiore è la frequenza di cicli di clock e tanto più elevata è la velocità di trasmissione delle informazioni (a parità di altre condizioni); tale frequenza dipende anche dalla tecnologia dei circuiti e dell'architettura del processore (ad esempio l'attuale Pentium III 500 Mhz).
Memoria centrale: contiene i programmi in esecuzione ed i relativi dati, è il contenitore dove sono conservate le informazioni mentre sono in atto altre operazioni. È suddivisa in un certo numero di posizioni (celle) identificate da un indirizzo. Ogni posizione (unità minima indirizzabile) memorizza una "parola" di memoria. La capacità della memoria (in Mbyte) identifica la quantità di informazioni che possono essere memorizzate (1byte = 8 bit che rappresenta l'informazione elementare).
L'accesso alla memoria avviene tramite i registri MAR e MDR più i segnali dei bus di controllo che specificano l'operazione richiesta, che può essere:
lettura: si rende disponibile sul bus dati (e quindi sul registro MDR) la parola presente nella cella selezionata;
scrittura: si modifica la parola contenuta nella cella selezionata, ponendola uguale a quella del registro MDR. (Vedi testo pag. 74)
La velocità di accesso alla memoria è molto importante per le prestazioni di un PC. Alcuni tipi di memoria sono:
memoria ad accesso casuale (RAM): permette l'accesso ad una cella senza la lettura delle celle precedenti (ogni parola di memoria è selezionata indipendentemente dalle altre). Il tempo di accesso è indipendente dalla posizione ed è uguale per tutte le celle.
memoria volatile: mantiene l'informazione solo finchè il PC è acceso, è alimentata tramite corrente elettrica.
memoria ROM (Read Only Memory - memoria a sola lettura): contiene tipicamente progrrammi di inizializzazione del PC (ROM BIOS: Basic Input/Output System), ad esempio caricamento del sistema operativo del disco di avvio ed esecuzione test dei componenti hardware al momento dell'accensione.
La memoria RAM volatile può essere:
dinamica (DRAM): ogni dato deve essere riscritto costantemente nella memoria (refresh);
statica (SRAM): chip speciali conservano i dati senza bisogno di refresh, è una memoria più veloce ma più costosa.
Le prestazioni della memoria sono misurate in:
tempo di accesso;
ciclo di memoria: numero di accesi nell'unità di tempo;
velocità di trasferimento (misurata in byte/secondo).
Abitualmente la memoria è organizzata come una combinazione di una memoria piccola e veloce (costosa) con una memoria più grande e lenta (economica). I dati sono organizzati in blocchi di dimensioni prefissate, alcuni dei quali sono trasferiti dalla memoria lenta a quella veloce: se la parola cercata è in tali blocchi, l'accesso è molto rapido.
Memoria cache: è una memoria secondaria, piccola e molto veloce, situata tra il processore e la memoria centrale. Consente di aumentare la velocità di accesso del processore alla memoria: le celle contigue al dato e all'istruzione elaborata al momento, sono caricate in questa memoria, da cui il processore li legge. Le informazioni usate più di recente e quelle ad esse contigue, hanno un'alta probabilità di essere riutilizzate in breve tempo. Questo meccanismo è molto utile poiché l'accesso alla memoria è una delle attività più lente del processore. L'accesso associativo è più veloce di quello casuale. (Pag. 75).
Memoria estesa: è una memoria addizionale, ottenuta aggiungendo i chip (SIMM: Small In line Memory Model) corrispondenti sulla scheda madre, per multipli di 64 K. Il sistema operativo trasferisce blocchi di dati dalla memoria principale a quella estesa; i programmi che la utilizzano possono disporre si più memoria.
Se il bus indirizzi trasferisce informazioni di 16 k, il numero massimo di indirizzi è 216 = 65.536KB (dove 1Kb = 210 = 1024). In realtà, i PC utilizzano una procedura (detta di indirizzamento segmentato) che consente di indirizzare fino a 1.048.576 parole (byte) di memoria: approssimativamente si hanno 1.000.000 di byte di memoria potenzialmente disponibili. Lo spazio di memoria (1.048.576 indirizzi possibili) è organizzato in 16 blocchi numerati (sistema esadecimale), di 64 K, di cui:
10 blocchi (640 K) per l'utente: esecuzione programmi, memoria convenzionale;
6 blocchi (384 K) riservati: memoria video, memoria ROM, programmi BIOS.
Memoria di massa: contiene grandi quantità di dati che non sono utilizzati frequentemente, ma che devono essere memorizzati in modo permanente. Le sue caratteristiche sono:
grande capacità;
costo limitato;
tempo di accesso elevato;
memoria non volatile (tecnologie magnetiche, ottiche).
I dispositivi delle memorie di massa sono:
nastri magnetici: accesso sequenziale, l'accesso ad un'informazione comporta la lettura di tutte quelle precedenti (necessità di avvolgere/riavvolgere il nastro). Il costo è basso, ma i tempi di lettura/scrittura sono molto lunghi. (Pagg. 79-80)
dischi magnetici (disco fisso, floppy disc): le informazioni sono memorizzate in cerchi concentrici (tracce) suddivisi in settori, ciascuno dei quali ospita un blocco di dati (record). Questi supporti hanno la necessità di essere formattati, cioè di identificare le posizioni di ogni settore in ogni traccia tramite dati di controllo memorizzate sui dischi. (Pag. 82). Per le operazioni di input ed output, la testina si posiziona sulla traccia indicata, il disco ruota e l'operazione è attivata quando il settore cercato si posiziona sotto la testina; l'accesso è misto.
dischi ottici: hanno una capacità molto superiore a quella dei floppy, pussono memorizzare una grande quantità di dati (enciclopedie, manuali). Sono simili ai compact disc audio e solitamente non sono riscrivibili (CD ROM). La memorizzazione avviene rendendo opache (0) e lucide (1) zone microscopiche di una pellicola di alluminio, all'interno di un supporto plastico circolare. I dati sono organizzati su di un percorso a spirale (anziché in tracce e settori) che va dal centro alla periferia del disco. La lettura è effettuata tramite un raggio laser che identifica i valori 0 e1 in base alla riflessione del fascio luminoso. L'accesso è di tipo sequenziale, ma con tempi molto ridotti. Alcuni CD sono registrabili: l'utente può memorizzare delle informazioni che non sono più cancellabili.
Gerarchia di memoria

SRAM DRAM

![]()

![]()

Scendendo nella gerarchia si ha:
aumetano le dimensioni delle memorie (sono più grandi);
diminuiscono i costi;
diminuiscono le prestazioni;
aumenta il tempo di accesso;
diminuisce la velocità di trasmissione.
SOFTWARE
Si tratta di:
Programmi applicativi che risolvono problemi specifici (Word, Excel, Access, Spss).
Linguaggi di programmazione che consentono all'utente la creazione di propri programmi applicativi (Fortran, Gauss).
Sistema operativo: insieme di programmi che consentono il funzionamento dell'hardware (funzioni di gestione e controllo delle risorse, gestione dei dispositivi di input output, protezione dagli errori, interfaccia con l'utente ed i programmi applicativi). I principali sistemi operativi sono:
DOS
Windows
Unix
Linux
I sistemi operativi sono classificati in base a:
Interfaccia, che può essere:
A caratteri: visualizza sul video solo caratteri alfabetici e numerici (25 righe e 80 colonne), l'interazione tra l'utente ed il sistema operativo avviene tramite rigidi comandi (esempio DOS, Unix).
Grafica: suddivide il video in pixel colorati che consentono di visualizzare qualsiasi forma; le informazioni relative ai comandi sono visualizzate tramite finestre (esempio Windows).
Modalità di funzionamento:
Single task: è in grado di svolgere una sola funzione per volta.
Multi task: coordina l'hardware in modo tale che ogni componente può dedicarsi alternativamente a compiti diversi per tempi molto brevi. Si ha l'esecuzione contemporanea di più operazioni, si evita il sotto utilizzo della CPU: si ha uno pseudo parallelismo.
RICHIAMI DI LOGICA DELL'ELABORAZIONE DELLE INFORMAZIONI
I passi principali sono tre:
problema dell'acquisizione dei dati;
elaborazione dei dati;
conclusione che si applica al problema.
La soluzione ad un problema di elaborazione, è una procedura (algoritmo) che, se eseguita, genera un risultato a partire dai dati iniziali. Conoscere la soluzione non significa essere in grado di risolvere il problema. La soluzione che si vuole ottenere deve quindi:
essere scritta in un linguaggio che il calcolatore è in grado di capire (il calcolatore è un esecutore di una soluzione ottenuta dall'uomo);
seguire precise regole formali;
essere costituita da istruzioni che il calcolatore è in grado di eseguire: ogni istruzione specifica un'operazione elementare rispetto alle capacità del calcolatore.
Algoritmo è l'insieme di regole (o istruzioni) che, operando su dati iniziali, consentono di ottenere i risultati che costituiscono la soluzione del problema. Tali regole devono inoltre soddisfare alcuni requisiti, in particolare, un algoritmo deve:
essere finito: deve concludersi dopo un numero finito di operazioni;
essere definito e preciso: ogni istruzione deve essere specificata in modo non ambiguo;
precisare il campo di applicazione degli eventuali dati di ingresso (dati numerici, caratteri o altro);
fornire almeno un risultato, soluzione del problema;
essere eseguibile: tutte le operazioni devono poter essere eseguite esattamente, in un tempo finito, da un uomo che utilizzi mezzi manuali, fornendo sempre gli stessi risultati.
Quando l'esecutore è una macchina, l'algoritmo è definito programma e il linguaggio formale usato nella descrizione delle operazioni è il linguaggio macchina.
Il processo di sviluppo di un programma si divide in diverse fasi, alcune delle quali sono proprie dell'uomo, altre della macchina; le fasi sono:
analisi del problema ed identificazione della soluzione (uomo);
formalizzazione della soluzione e delineazione dell'algoritmo corrispondente (uomo);
programmazione: scrittura del programma nel linguaggio ad "alto livello" orientato ai problemi ed indipendente dalla macchina (uomo);
traduzione del programma nel linguaggio che il calcolatore è in grado di comprendere ("linguaggio macchina"); fase svolta automaticamente tramite opportuni strumenti software (compilatori o interpreti) (calcolatore);
esecuzione del programma tradotto in linguaggio macchina (calcolatore).
Le regole che costituiscono l'algoritmo, sono determinate tramite scomposizione iterativa del problema iniziale in sottoproblemi elementari detti passi (step) dell'algoritmo; si ha una soluzione per ciascun sottoproblema. (Pag. 19,20)
Con la dichiarazione del tipo di dati si stabilisce, all'inizio dell'algoritmo, l'esistenza di un certo insieme di dati (numeri - reali o interi - caratteri o altro) sui quali sono definite determinate regole di calcolo. I dati numerici possono essere:
costanti: dati il cui valore rimane fisso tutte le volte che l'algoritmo è eseguito e per tutta la durata dell'esecuzione;
variabili: dati il cui valore può variare durante l'esecuzione dell'algoritmo (è un contenitore di valori). Con l'assegnazione ad una variabile di un valore o del risultato di un'operazione, la stessa assume temporaneamente (fino all'assegnazione successiva) il valore indicato.
Costanti e variabili sono identificabili tramite un nome.
Strutture elementari di un algoritmo
Sono definite strutture elementari le strutture di base che, combinate, formano un algoritmo complesso, e sono:
istruzioni (permettono l'esecuzione di un problema terminale elementare);
sequenze di istruzioni;
strutture condizionali;
strutture iterative.
Nelle strutture condizionali, l'algoritmo richiede di fare una scelta sulla base del verificarsi o meno di una determinata condizione logica (detta predicato); si introduce un controllo su una condizione relativa al risultato di un calcolo numerico (o di una operazione logica): in relazione al verificarsi o meno della condizione, si scegli tra soluzioni mutualmente esclusive. Generalizzazione: scelta tra k possibili alternative. Esempio: ricerca del numero maggiore fra due numeri interi.
Condizione relativa al risultato
a - b. Questo algoritmo non è completo in quanto manca la condizione x = 0.
Dati:
a, b, : interi
x = a - b
Se (x > 0) allora max = a
![]() altrimenti max = b
altrimenti max = b
Risultato max
Nelle strutture iterative (loop), l'algoritmo permette di ripetere più volte (finché non si verifica una condizione di arresto) una sequenza di istruzioni. L'iterazione elementare (detta passo dell'iterazione) è una sequenza di istruzioni elementari che deve essere ripetuta ciclicamente. La struttura iterativa può essere:
enumerativa: la condizione di arresto è di tipo numerico (ad esempio ripetere 10 cicli);
non enumerativa: la condizione di arresto è legata al verificarsi di un evento stabilito (ad esempio ripetere fino a che X è falso).
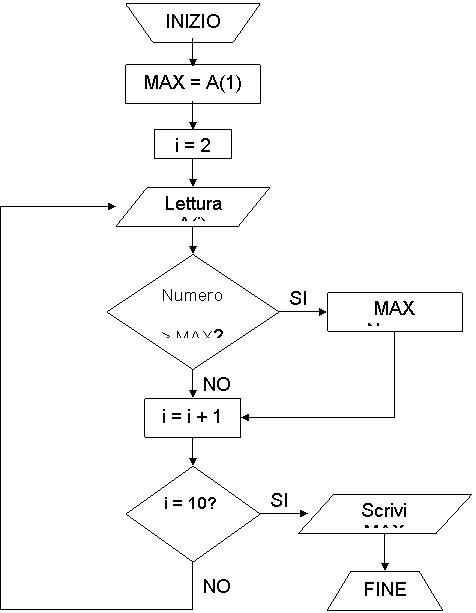
Esempio: ricerca del numero maggiore fra 10 numeri interi; è la sequenza di istruzioni del problema terminale: "trovare il maggiore di due numeri". Si ha:
trova il maggiore fra i primi i due numeri
trova il maggiore fra il 3° numero e quello ottenuto al passo precedente
trova il maggiore fra il 10° e quello che hai ottenuto al passo precedente
Totale 9 passi.
Struttra iterativa
trova il maggiore tra i primi due numeri
trova il maggiore tra il 1° numero non ancora esaminato e quello ottenuto al passo precedente
ripeti il passo 2 finché ci sono numeri da esaminare.
Esempio n° 1.
Dati: A1, A2, ., A10 vettore (array) di 10 elementi
max = (A1)
Ripeti per i =2, ., 10
x = A(i) - max
se (x > 0) allora max = A(i)
Fine iterazione
Risultato max
Avendo inizializzato max, possiamo omettere gli altri casi del se.
Esmpio n° 2.
Dati: A1, A2, ., A10 vettore (array) di 10 elementi
max = A(1)
i = 2
Ripeti
x = A(i) - max
se (x > 0) allora max = A(i)
i = i + 1
Finché i
Risultato max
Programma che fa 10 iterazioni
Diagrammi di flusso
Un diagramma di flusso è un linguaggio formale grafico che descrive un algoritmo, composto da blocchi che rappresentano le azioni e che hanno forme diverse secondo il tipo di azione:
trapezio: inizio/fine programma;
romboide: trasferimento dati, operazioni di input/output;
rombo: decisione;
rettangolo: singola azione o successione di azioni;
rettangolo con lati verticali raddoppiati: sotto programma, programma associato ad un sotto problema;
frecce: connettono tra loro i blocchi; la loro direzione indica la successione delle azioni corrispondenti.
SCHEMA DI UN ALGORITMO
CODIFICA DEI DATI
L'algoritmo è un insieme di azioni (sequenza di istruzioni, strutture condizionali ed iterative, ecc.) e di dati. Affinché un algoritmo sia effettivamente utilizzabile da un elaboratore, è necessario che azioni e dati siano rappresentati in un formato adatto alla loro memorizzazione ed elaborazione : che siano codificati. Gli elementi principali della codifca dei dati sono:
alfabeto: insieme di simboli che formalizzano i dati (numeri e lettere);
regole di composizione: definiscono le successioni di simboli dell'alfabeto che consentono di identificare i dati;
codice: relazione che associa ad ogni successione "ben formata" di simboli dell'alfabeto, il codice corrispondente.
In particolare, l'alfabeto binario è un codice basto su due caratteri (0 e 1). Tutti i dicposittivi di elaborazione e di memorizzazione hanno due stati, presenza o assenza di impulsi elettrici, magnetizzazione, ecc. L'alfabeto binario presenta semplicità e minore necessità di precisione, inoltre è necessario conoscere lo stato (0/1) del dispositivo anziché l'intensità precisa del segnale. L'unità elementare è il Bit (Binary digit): cifra binaria, elemento che assume un valore binario (0/1). Il Byte è una successione di 8 bit, successione di 8 cifre binarie; con un byte si possono rappresentare 28 = 256 dati diversi (sono le disposizioni con ripetizione di classe 8 di 2 elementi).
I multipli di un byte, definti tramite potenze di 2, sono:
|
Kbyte |
Kilo byte |
|
= 1.024 byte ..... |
1000 byte |
|
Mbyte |
Mega byte |
|
= 10.24 Kbyte |
|
|
|
|
|
= 1.048.576 byte ... |
1.000.000 byte |
|
Gbyte |
Giga byte |
|
= 1.024 Mbyte |
|
|
|
|
|
= 1.073.741.824 byte |
1.000.000.000 byte |
È definita parola, il gruppo di bit di maggiori dimensioni (ad esempio 16, 32, 64) che può essere memorizzato dal calcolatore; è la dimensione di una cella di memoria.
Nella codifica dei dati, il calcolatore ragiona in termini di valore posizionale: il valore di una cifra dipende dalla sua posizione nella successione dei simboli che rappresentano il numero, una stessa cifra corrisponde a valori diversi. Ad esempio la rappresentazione del numero decimale 344 3 * 102 + 4 * 101 + 4 *100 nel sistema di numerazione a base 10.
In generale, la rappresentazione decimale di un numero naturale di n cifre (compreso tra 0 e 9, alfabeto di 10 cifre) è: Cn-1*10n-1+Cn-2+10n-2+.+C1+101+C0*100.
Le cifre più significative sono associate ai pesi maggiori:
se il numero è, in modulo, > 1 le cifre più significative sono quelle più a sinistra;
se il numero è, in modulo, < 1 le cifre più significative sono le prime cifre diverse da 0 che si incontrano da sinistra a destra dopo il separatore decimale (virgola o punto).
Nella codifica binaria, l'alfabeto è di 2 cifre (0 e 1), il sitema di memorizzazione è a base 2 (Cn-1Cn-2.C1C0)2 = Cn-1*2n-1+Cn-2*2n-2+.+C1*21+C0*20 (C C
Conversione di un numero binario in decimale
Con una successione di n bit si rappresentano 2n numeri naturali (da 0 a 2n-1). Ad esempio se n=4 si possono rappresentare i numeri da 0 a 15. Nei linguaggi di programmazione si utilizzano abitualmente successioni di 32 bit, 4 byte, per i numeri naturali/interi (aritmetica intera a 32 bit); è così possibile esprimere i numeri naturali compresi tra 0 e 232-1 = 4.294.967.295 = 4+109 (se un numero è maggiore si ha l'overflow).
Conversione di un numero decimale in binario
= 3*100+4*10+4*1

 = (11)2*(1100100)2+(100)2*(1010)2+(100)2*(1)2
= (11)2*(1100100)2+(100)2*(1010)2+(100)2*(1)2
=(100101100)2+(101000)2+(100)2
(Metodo alternativo Pag. 32 33)
Soluzione alle moltiplicazioni.
Nel sistema decimale 10*10=100
Nel sistema binario (1010)2*(1010)2=(1100100)2
(1010)2*
(1010)
1010 -
0000 -
1010 -
Analogamente: nel sistema decimale si ha: 100*3=300
Nel sistema binario: (1100100)2*(11)2=(100101100)2
(1100100)2*
(11)
1100100
1100100 -
Un tipo di codice è il BCD (Binary Coded Decimal) in cui ogni cifra decimale è codificata separatamente in binario. L'inconveniente del codice binario (utilizzato dall'elaboratore) è l'alfabeto di due soli simboli, il che produce numeri molto lunghi rispetto agli equivalenti decimali. Sono stati allora elaborati altri codici tra cui quello ottale: alfabeto di 8 caratteri; numerazione a base 8=23. Il codice più utilizzato è quello esadecimale: alfabeto di 16 simboli , sistema a base 16. Le sue caratteristiche sono
rappresentazione più sintetica dei numeri manipolati dall'elaboratore;
conversione molto semplice da binario in esadecimale; infatti ogni cifra esadecimale corrispoinde ad un gruppo di 4 cife binarie (poiché 16=24).
![]()
![]() Ad esempio. 344=(101011000)2=0001 0101 1000=(158)16
Ad esempio. 344=(101011000)2=0001 0101 1000=(158)16
![]()
=1*162+5*161+8*160
CODIFICA BINARIA DI NUMERI INTERI (positivi e negativi)
La codifica può essere:
codifica con segno e grandezza: si ha una rappresentazione separata del segno (1 bit: 0= positivo, 1= negativo) e del modulo (n-1 bit in codice binario) del numero. Con n bit si disegnano i numeri interi da - (2n-1-1) a (2n-1-1) (il -1 serve per rappresentare lo 0). Svantaggio: rappresentazione non univoca dello 0, infatti questo può essere, con 4 bit, (0000)2, ma anche (1000)2, quindi con 4 bit si riescono a rappresentare effettivamente 15 numeri e non 16;
rappresentazione in complemento a 2: sono usati i valori posizionali binari, ma il bit più significativo (1° bit a sinistra, al quale è associato il peso maggiore) rappresenta una quantità negativa. Ad esempio:
- con 4 bit:
(C3, C2, C1, C0)2= - C3*23 + C2*22 + C1*21 + C0*20
- con 6 bit:
Vantaggi:
il numero 0 ha una rappresentazione univoca quindi, dati n bit, si rappresentano gli interi da -2n-1 a 2n-1-1, ad esempio, con 32 bit, da -2.147.483.648 (231) fino a 2.147.483.647;
è molto semplice cambiare di segno ad un numero si invertono tutti gli 0 in 1 e tutti gli 1 in 0, poi si aggiunge 1; ad esempio:
consente di effettuare sottrazione tra numeri, infatti x - y = x + (-y);
inoltre, dati n bit, la rappresentazione di x è equivalente a quella di 2n+x (dopo aver rimosso il bit più significativo). Ad esempio ( 4 bit):
- 5
Per tali ragioni, la rappresentazione in complemento a 2 è la più utilizzata per codificare i numeri interi.
CODIFICA BINARIA DI NUMERI NON INTERI
Si tratta della rappresentazione dei numeri reali e razionali (cioè quei numeri che possono essere ricondotti ad una frazione generatrice). Nella codifica di questi numeri, c'è un problema di approssimazione tramite numeri razionali che abbiano un numero di cifre ridotto (compatibile con la capacità di approssimazione della macchina): si ha il cosiddetto errore di troncamento. Ad esempio:
errore 1/3 - 333/1000 = 1/3000
Per la codifica di questi numeri, ci sono 2 tipi di rappresentazioni:
in virgola fissa: la codifica è analoga a quella dei numeri interi (con segno e grandezza oppure in complemento a 2), ma con riferimento a potenze di ½ anziché di 2. Ad esempio (codifica con segno e grandezza):
- 3/8 = - 0.375 = [(1/4) + (1/8)] = 1*[0*(1/2)1 + 1*(1/2)2 + 1*(1/2)3] =(1 011)2 segno grandezza
![]()
![]()
![]()
![]()
![]()
![]() Svantaggio: limitato
campo di variazione dei numeri rappresentabili.
Svantaggio: limitato
campo di variazione dei numeri rappresentabili.
in virgola mobile: è simile alla notazione scientifica ma con numerazione a base 2.
Notazione scientifica:
numero reale = m * 10e ( ad esempio 9 miliardi = 9 * 109)
i componenti principali di questa notazione sono:
segno (+/-);
mantissa: parte frazionaria (m), in particolare si adotta la convenzione di inserire il separatore decimale (virgola o punto) dopo al prima cifra di m: m= C0, C1..Cn-1 se C0 > 0 allora si ha la rappresentazione normalizzata, in cui n rappresenta il numero di cifre significative di m: è la precisione del numero;
base (10);
esponente (e) che determina la dimensione del numero; ad esempio:
I valori rappresentabili in tale forma, dipendono dalla base adottata, dal numero di cifre significative (n) e dal campo di variazione dei possibili esponenti (emin e emax).
Se un numero è al di fuori del campo dei numeri rappresentabili si ha un overflow; viceversa, se un numero (diverso da 0) è minore del più piccolo numero rappresentabile si ha un underflow. Molti elaboratori pongono questo numero pari a 0. Quale entità simbolica si ha NaN = Not a Number risultato di una operazione non valida (ad esempio una divisione per 0).
Nella notazione scientifica, la virgola si sposta verso destra (si ha allora un numero < 1) oppure verso sinistra (si ha allora un numero > 1), è mobile.
Tornando alla codifica binaria, si ha (considerando la notazione scientifica): m * 2e. In particolare: la mantissa (m), la base (2) e l'esponente (e) sono tutti rappresentati in base 2. Ad esempio:
= (1 + 1/4 + 1/16) * 28 =
![]() = (1,0101)2 * (10)2(1000)2
= (1,0101)2 * (10)2(1000)2
0 * 1/2 + 1 * 1/4 + 0 * 1/8 + 1 * 1/16
In realtà si preferisce che la mantissa sia un numero compreso tra ½ e 1 (normalizzazione) il bit a destra del separatore decimale (virgola) è un 1. Ciò garantisce che la parte frazionaria del numero sia memorizzata con il massimo numero di bit disponibili. In questo modo lo zero e la virgola non sono considerati ed il calcolatore sa già che si tratta di (0,), si evita si sprecare dei bit. Il primo bit è di sicuro 1. Pertanto (vedi esempio precedente):
= (0 + 1/2 + 1/8 + 1/32) * 29
= (0,10101)2 * (10)2(1001)2
Esempi.
![]() rappresentazione non normalizzata
rappresentazione non normalizzata
![]() = (1/2 + 1/4) * 2-2 = (0,11)2
* (10)2 - (10)2
= (1/2 + 1/4) * 2-2 = (0,11)2
* (10)2 - (10)2
rappresentazione normalizzata
= (2-1 + 2-2 + 2-4 + 2-5) * 23 = (0,11011)2 * (10)2(11)2
In realtà, nella rappresentazione in virgola mobile:
lo 0 prima della virgola;
la virgola;
le parentesi e l'eventuale segno;
la base.
segno
NON si rappresentano si ha
una sequenza di 0 e di 1 corrispondenti a m ed a e, il significato del numero dipende
dal numero di bit assegnati alla mantissa e all'esponente ed al sistema si
codifica utilizzato. Ad esempio: rappresentazione del numero 0,1875 con 16 bit,
utilizzando 11 bit per la mantissa e 5 per l'esponente ed una codifica segno e
grandezza per entrambi:
![]()
![]()
esponenete mantissa m =11 bit
![]()
![]() 1
0010)2
1
0010)2
Solitamente alla mantissa si assegna un numero di bit maggiore rispetto all'esponenete in quanto è la dimensione della mantissa che determina l'errore si troncamento. Ad esempio:
S di infiniti termini
dall'analisi matematica, la S n=dispari xn = x / (1-x2) se x < 1
se x = ½ allora x / 1-x2 = 2/3 = S (1/2)n
Se sono disponibili 6 bit per m (codifica sengo e grandezza):
0,65625 (errore
Se sono invece disponobili 12 bit (codifica segno e grandezza):
0,66650 (errore
Nell'aritmetica a 32 bit (mantissa 24 bit, esponente 8 bit) si possono rappresentare (approssimativamente) i numeri reali compresi tra:
da - 3,4028235 *10+38 a - 1.1754944*10 -38
da+1,1754944 *10 -38 a+ 3,4028235 *10+38
il numero 0.
In tale rappresetazione, le cifre decimali oltre la 6a, non sono significative perché sono casuali e derivano da errori di troncamento.
Nell'aritmetica a 64 bit (8 byte aritmetica in doppia precisione), con 53 bit per la mantissa e 11 per l'esponente, il range di numeri reali approssimabili è molto più ampio ( ), la precisione è fra le 15 / 16 cifre significative.
Importante è la dichiarazione del tipo di dati perché da questo dipende il sistema di memorizzazioone e di codifica utilizzati dal calcolatore.
CODIFICA DI CARATTERI DI TIPO ALFABETICO
Si tratta di caratteri alfanumerici e speciali anch'essi trasformati in numeri (dicimali, binari, esadecimali). La codifica più utilizzata è quella ASCII: è un codice a 7 bit che consente du rappresentare 27=128 caratteri numerati da 0 a 127 nel sistema decimale. I primi 31 caratteri rappresentano funzioni di controllo; quelli dal 32 in poi idenficano i normali caratteri alfanumerici e speciali (cosiddetti stampabili). (Pag 38 del testo). Per caratteri particolari (lettere accentate e greche) si utilizza una codifica estesa: a 8 bit. Ciascun carattere è codificato separatamente, come una successione di cifre binarie. Ad esempio:
A= 65; io = 105 11
Durante l'elaborazione i dati alfabetici restano in codice di carattere mentre quelli numerici sono convertiti (binario/esadecimale).
ESERCIZI SULLA RAPPRESENTAZIONE BINARIA DEI NUMERI DECIMALI
Si scriva in binario (rappresentazione in virgola fissa) il numero +101 utilizzandi una codifica in complemento a 2, con il minor numero di bit possibile.
Si effettui in binario la sottrazione (55 - 101), rappresentando i numeri interi in virgola fissa e con una codifica in complemento a 2. Si dica inoltre se la precedente operazione può essere svolta tra i corrispondenti numeri rappresentati nel codice ASCII.
Si rappresentino in virgola mobile i numeri -25 e 3/128, utilizzando 8 bit per la mantissa e 4 bit per l'esponente e con una codifica segno e grandezza per entrambi.
Si dica qual è il numero minimo di bit assegnabili alla mantissa (codifica segno e grandezza) per rappresentare in virgola mobile il numero 0.4 con un errore di troncamento non superiore a |0.0002|.
CORREZIONE DEGLI ESERCIZI
Con 8 bit si rappresentano, in complemento a 2, i numeri da - 128 a + 128, per cui si ha: x = 101 = 2n + x = 28 +101 = 357
utilizzando la codifica dei numeri naturali, si ha:
Quindi:
(100101100)2 + (110010)2 + (111)2
(101100101)2 9 bit, si rimuove il bit più significativo:
La rappresentazione di - 101 può essere fatta invertendo i bit di + 101 e poi aggiungendo 1:
In alternativa:
Oppure:
codifica dei numeri naturali = -101 con la codifica in complemento a 2.
Per cui la sottrazione 55 - 101 = 55 + (-101):
![]()
![]() - 128 + 64 + 16 + 2 = -
46
- 128 + 64 + 16 + 2 = -
46
La stessa operazione non può essere svolta con i corrispondenti numeri rappresentanti il codice ASCII, in quanto questo è un codice di caratteri con i quali non è possibile effettuare calcoli numerici.
Assegnando 8 bit alla mantissa e 4 bit all'esponente, si ha:
Assegnando 8 bit alla mantissa e 4 bit all'esponente, si ha:
Se per l'esponente fossero disponibli 6 bit si avrebbe: 100101 perché sono potenze di 2; alla mantissa gli zeri si mettono dopo perché si tratta di potenze di ½.
0.4 = 0.8 * 2-1 = x x
Quello che noi dobbiamo rappresentare con il minor numero di bit possibile è la mantissa, cioè 0.8.
Dall'analisi matematica si ha:
1- x2 + x4 - x6 + x8 - x10 +.= 1/1+x2 se |x|<1
se x = 1/2 1/1+x2 = 0.8
coniderando i termini fino a - (½ )10:
soddisfatta la condizione iniziale: x = 0.799804 * 2-1 = 0.399902
Rappresentazione in binario:
- (1/2)2 = 1/2 + (1/2 - 1/4) = 1/2 + ¼
Pertanto:
x = [1/2 + (1/2)2 + (1/2)5 + (1/2)6 + (1/2)9 + (1/2)10] * 2-1
0.399902 con un errore di circa - 0.0001
In binario, codifica segno e grandezza, la mantissa diventa:
11 bit
In pratica, dobbiamo avvicinarci il più possibile a 0.7998 o a 0.8002, quindi:
|
|
|
0.5 SI |
|
|
|
0.5 + .025 = 0.75 SI |
|
|
|
0.75 + 0.125 = 0.875 NO |
|
|
|
NO |
|
|
|
0.75 + 0.03125 = 0.78125 SI |
|
|
|
0.78125 + 0.015625 = 0.796875 SI |
|
Ecc. |
|
|
INPUT DEI DATI
È la fase preliminare di ogni elaborazione statistica, che può essere eseguita con due diverse procedure:
immissione manuale;
impiego di dati già memorizzati.
Immissione manuale: si rende necessaria quando i dati non sono disponibili in altra forma, ad esempio:
dati rilevati per l'elaborazione in esame;
dati rilevati e pubblicati in tempi non recenti, quindi non menorizzati su supporti magnetici o ottici;
dati reperibili su supporti magnetici (ad esempio dati pubblicati recentemente) ma solo con tempi o costi elevati: la scelta dipende anche dalla dimensione del data set.
L'imput manuale può avvenire :
v con immissione diretta, tramite tastiera, dei dati all'interno del programma applicativo (EXCEL, SPSS, GAUS), occorre aver già scelto quale programma utilizzare, solitamente l'immissione diretta si ha nel caso di:
data set di dimensioni ridotte, se si utilizza un pacchetto statistico, o se si hanno problemi di spazio sul disco;
uso non ripetuto dei dati;
v tramite programmi appositi (editor) e successiva memorizzazione (su floppy o disco fisso) in un formato universale, questo tipo di immssione di ha nel caso di:
data set di grandi dimensioni;
uso ripetuto dei dati con programmi applicativi diversi (si evitano problemi di conversione);
semplicità di trasporto dei dati su differenti macchime o per differenti utenti.
Uno svantaggi nell'utilizzo dell'editor è che il file che si ottiene è molto scarno. Il file ASCII (ad esempio) è un file di soli dati e richiede una certa accortezza nella lettura. Ad esempio (vedi esercitazioni):
editor del DOS comando edit (tasto F1 = help in linea; ALT + comandi menù a tendina);
blocco note, per piccoli file, oppure Word Pad di Windows 95, salvataggio in formato solo testo; formato universale sol testo, solitamente con estensione .txt file ASCII.
Una possibile eccezione ai precedenti criteri è Excel, un programma applicativo molto versatile.
Impiego di dati già memorizzati: si rende opportuno nel caso di:
grandi masse di dati disponibili su supporti magnetici o ottici;
tempi/costi di accesso limitati.
Questo impiego ha avuto una grande diffuzione con l'avvento di Internet. In ambito statistico, questo impiego consiste nell'accesso ai dati prodotti da fonti statistiche ufficiali (ISTAT, EUROSTAT, OCSE, .). I problemi relativi all'utilizzo di questi dati sono:
per i file di grandi dimensione sono possibili delle difficoltà di gestione;
spesso i file sono compressi per ridurre le loro dimensioni, si rende allora necessario decomprimerli tramite appositi programmi;
il formato dei dati è specificato dal produttore degli stessi, l'utente non ha la possibilità di scelta, possono allora sorgere delle difficoltà di lettura da parte del programma applicativo o di conversione in altri formati.
RAPPRESENTAZIONE DEI DATI
La struttura utilizzata per la rappresentazione è la matrice dei dati che è costituita da n righe, che rappresentano le unità statistiche (record) e da k colonne che rappresentano le variabili/fenomeni (campi); questo è lo schema più utilizzato. I possibili criteri/formati di memorizzazione di un record sono:
formato fisso (fixed format). In questo formato ciascuna variabile occupa un numero prefissato di caratteri su ogni riga. Ad esempio unità statistica = studenti iscritti alla Facoltà di Economia di Parma al 1/01/98, i campi sono:
nome 12 caratteri
cognome 12 caratteri
matricola 6 caratteri
anno di corso 2 caratteri
|
|
|
G |
I |
A |
N |
F |
R |
A |
N |
C |
O |
|
|
|
|
|
F |
E |
R |
R |
A |
R |
I |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A |
L |
D |
O |
|
|
|
|
|
|
|
R |
O |
S |
S |
I |
|
|
|
|
|
|
F |
C |
Vantaggi:
struttura rigida , tipica matrice di dati, è preferibilie per analisi statistiche successive;
è immediato (anche visivamente) individuare a quale variabile si riferiscono i valori.
Svantaggio: la dimensione di un campo è il massimo di caratteri che richiede la variabile corrispondente, si ha uno spreco di spazio.
formato variabile (libero). In questo formato i dati riferiti a variabili diverse sono separati da un particolare carattere (specificato a priori), che può essere:
spazio (carattere vuoto);
virgola (se il separatore decimale è il punto);
punto e virgola;
tabulazione.
Se si sceglie lo spazio, con gli stessi dati dell'esempio di prima, si ha:
GIANFRANCO FERRARI 108300 3
ALDO ROSSI 74051 FC
Vantaggi e svantaggi:
ogni variabile occupa il numero di caratteri della corrispondente modalità, anziché il massimo possibile, ne deriva un minore spazio (vedi riga 2: 19 caratteri anziché 30);
il numero totale di caratteri puà variare da riga a riga, da ciò deriva la necessità di maggiore attenzione nelle fasi di lettura dei dati all'interno dei programmi applicativi.
BANCHE DATI
Una banca dati (data base) è una collezione di file memorizzati su disco che contengono dati logicamente collegati tra loro in modo da formare un unico insieme; è una raccolta di dati memorizzati che possono essere utulizzati per tutte le applicazioni da parte di un'azienda (ente pubblico o ente di ricerca). Ad esempio:
banca dati degli studenti iscritti all'Università; sono raccolti i dati anagrafici, anno di corso, i piani di studio, il pagamento delle tasse di iscrizione, ecc.;
banca dati di un'azienda pubblica che gestisce l'erogazione dell'acqua potabile; sono raccolti i dati relativi alla qualità dell'acqua (numerosi parametri fisico - chimici) modalità di controllo, luogo e tempo del controllo, ecc.
banca dati di immagini.
Prima della diffusione delle BD, i sistemi informatici erano basati sull'uso di più archivi separati: ogni applicazione accedeva alle informazioni memorizzare negli archivi. I vantaggi rispetto all'uso di archivi separati sono:
efficienza nella gestione dei dati (eliminazione delle duplicazioni) in quanto c'è una sola copia di ogni dato; per ciascun argomento esiste un unico file nella BD anziché un file per ogni applicazione;
concordanza dei dati: l'aggiornamento di un dato è immediatamente disponibile a tutti gli utenti, senza rischi di errori/omissioni dovuti alla presenza dei dati in file differenti;
maggiore facilità d'installazione di nuove applicazioni, in quanto molti dei dati sono già presenti nella BD;
maggiore controllo della privatezza e della sicurezza dei dati in quanto tutti gli accessi avvengono attraverso un sistema centralizzato che gestisce i permessi di accesso ai vari insiemi di dati, ad esempio, dati protetti accessibili sono ad utenti autorizzati;
possibilità di garantire l'integrità dei dati (consitenza rispetto ai vincoli stabiliti a priori): esistono delle regole che specificano come e quando è possibile aggiornare la BD, il software del sistema verifica automaticamente tali vincoli e impedisce l'esecuzione di programmi che li violino;
disciplina degli accessi simultanei: lo stesso dato non può essere modificato simultameamente da più utenti;
dati distribuiti, anziché centralizzati: i dati sono disponibili direttamente dal PC, non occorre interrogare il mainframe.
Gli svantaggi sono:
necessità di software complessi ed elaboratori potenti (problema oggi meno rilevante);
rischio di blocco dell'attività nel caso di problemi (guasti, interruzzione del sistema), si avverte la necessità di archivi di bakup ( ad esempio CD ROM, archivio cartaceo) e di funzioni di controllo.
MODELLO DEI DATI
Il modello dei dati è la descrizione della realtà che si vuole rappresentare tramite la BD (in particolare le caratteristiche che interessano per le decisioni) espressa in un linguaggio formale. Ad esempio, modello dei dati relativo all'iscrizione degli studenti ad un appello di esame; sono raccolte le informazioni relative a:
studenti e loro piano di studio;
corsi attivati, in particolare date degli appelli;
propedeuticità.
Il modello dei dati deve essere scritto in un linguaggio formale, testuale o grafico; le frasi che costituiscono le definizioni non devono essere ambigue, così come le relative regole di composizione. Ad esempio, una frase che contiene il termine SE, deve essere seguita, nell'ordine, da:
una condizione;
un termine ALLORA;
una azione.
La struttura logica dei dati (modello centrale dei dati e modelli - applicazione scientifica - dei dati dell'utenza da esso derivati) deve essere indipendente dai mezzi fisici di registrazione: se si cambia un mezzo di registrazione occorre solo cambiare una parte del software del sistema; si parla di interfaccia fra modelli e rappresentazione fisica dei dati. In termini astratti un modello dei dati è costituito da:
v entità, organizzate in insieme di entità. Ad esempio, ALDO ROSSI = entità, "studenti" = insieme di entità; TECNICHE DI RICERCA E DI ELABORAZIONE DEI DATI = entità, "esami" = insieme di entità. In termini statistici le entità rappresentano le unità statistiche, mentre l'insieme di entità rappresenta la popolazione.
v attributi valutabili sulle entità di un insieme e caratterizzati da un insieme di valori. Ad esempio, "iscritto regolarmente" = attributo valutabile sull'insieme delle entità studenti, valori = (vero / falso). In termini statistici gli attributi rappresentano le variabili (nell'esempio dicotomica).
Tipi di modelli dei dati
Modello relazionale; diffuso nel DBMS a partire dagli anni '80, oggi è il più utilizzato. I dati sono strutturati sotto forma di tabelle, ciascuna delle quali rappresenta una relazione tra due o più aspetti di interesse in ogni riga (record) sono memorizzati i dati relativi ad una entità e in ogni colonna (campo) i valori assunti dagli attributi nell'insieme delle entità (analogia con una matrice dei dati). Le tabelle sono in relazione tra loro attraverso il DBMS; si riduce al minimo la duplicazione dei dati, inoltre il modello può essere trasformato mediante una eventuale voce di dati comune a più tabelle. Ad esempio DB studenti:
tabelle di relazione: dati anagrafici/matricola/corso di laurea;
tabelle di relazione: matricola/anno di corso/dati esami sostenuti.
La ricerca dei dati avviene attraverso l'estrazione, da un insieme, di dati che soddisfano una condizione definita a priori (ad esempio nome e cognome dello studente); la ricerca/estrazione è definita Query. La ricerca dei dati viene spesso facilitata da opportuni strumenti del DBMS; ad esempio QBE (Query By Example) = possibilità di specificare i record desiderati tramite un esempio di ricerca semplifica la corretta preparazione delle condizioni di ricerca.
Con la ricerca per parola chiave (full text) si cercano i testi che al loro interno contengono una certa parola chiave o una certa frase.
Modello reticolare; si basa una struttura di dati a reticolo.
Modello ad oggetti, più recente (fine degli anni '80). Estende al DBMS alcuni concetti dei linguaggi di programmazione orientati agli oggetti (ad esempio il linguaggio di programmazione C++). I dati sono rappresentati da oggetti che possono essere manipolati solo dalle funzione ad essi associate.
(esercitazione ACCESS
Esempio di banca dati: Banca Dati Union Camere E.R.: Banca Dati che contiene informazioni su un gran numero di indicatori economici e sociali (oltre 30 fonti) di aggregati al livello regionale o provinciale:
oltre 2500 file aggiornati ogni anno;
informazioni raccolte in tabelle predisposte con il foglio elettronico Lotus file facilmente asportabili e leggibili anche con Excel;
possibilità di ricerca per argomento e per parola;
guida interattiva che illustra il contenuto dei dati selezionati e ne ricostruisce la storia e le fonti;
possibilità di ricerca alternativa "navigazione virtuale" approccio più intuitivo, analogia con una città: prima si sceglie il quartiere, poi un edificio, poi un piano, poi una stanza ed infine il file;
disponibile su CD ROM o presso sito internet.
Conseguenze sull'analisi dei dati: utilizzo di grandi masse di dati (accessibili via Internet o tramite Data Warehouse).
DATA MINING
Si tratta di metodi la cui funzione è quella di estrazione di conoscenza da banche dati di grandi dimensioni tramite l'applicazione di algoritmi che individuano le associazioni "nascoste" tra le informazioni e le rendono visibili. Il data mining è una fase del processo di estrazione della conoscenza, detto Knowledge Discovery in Database (KDD). Le varie fasi di questo sono:
definizione degli obiettivi;
scelta delle fonti;
acquisizione di dati;
file processing;
data mining;
interpretazione e rappresentazione dei risultati.
![]() Con il
termine data mining si intendono le tecniche per l'esplorazione di grandi
quantità di dati per individuare e renderle utilizzabili, a chi prende le decisioni,
le informazioni più singnificative, cioè quelle che fanno riferimentto
all'individuazione di patterns (associazioni, regolarità, sequenze ripetute) nascosti
tra i dati. La metodologia è prevalentemente di tupo ststistico. In particolare:
Con il
termine data mining si intendono le tecniche per l'esplorazione di grandi
quantità di dati per individuare e renderle utilizzabili, a chi prende le decisioni,
le informazioni più singnificative, cioè quelle che fanno riferimentto
all'individuazione di patterns (associazioni, regolarità, sequenze ripetute) nascosti
tra i dati. La metodologia è prevalentemente di tupo ststistico. In particolare:
Cluster analysis obiettivi trovare:
Associazione - gruppi omogenei (segmentazione)
Analisi fattoriale
Reti neurali - relazioni tra modelli
Alberi di decisione
Analisi esplorative - eventuali "anomalie" nei dati
Il data mining risolve il problema dell'analisi di grandi campioni, va incontro all'esigenza di sfruttare il patrimonio informativo contenuto nei grandi archivi di dati (non strutturati), che possono essere:
attività di gestione dell'azienda;
clientela / utenza;
mercato / concorrenza.
Il rischio è la conoscenza limitata di tali dati.
Evoluzione del data mining
anni '60 (raccolta dati) le informazini sono standardizzate, si ha un output predefinito e riassuntivo (ad esempio: quanto si è venduto negli ultimi 3 anni);
anni '80 (accesso ai dati) interrogazioni al database, identificazione di aspetti particolari (ad esempio: quanto ho venduto al Nord lo scorso gennaio);
anni '90 (query al database) interrogazioni in tempo reale (ad esempio selezione di una zona; date le vendite al Nord, seleziona le città);
oggi (data mining) tentativo di scoprire relazioni significative (perché vendiamo di più in alcune città).
I vantaggi del data mining sono:
trattamento di dati quantitativi, qualitativi e testuali;
non richiede ipotesi specifiche da parte del ricercatore;
metodi che elaborano un gran numero di osservazioni/varibili con algoritmi efficienti;
metodi esplorativi assenza di ipotesi sulla forma e distribuzione delle variabili;
semplicità di visualizzazione/interpretazione di risultati.
Le possibili applicazioni del data mining sono:
Segmentazione della clientela (database marketing). Si tratta di tecniche di classificazione per individuare gruppi omogenei in termini di comportamento d'acquisto e di caratteristiche socio demografiche di consumatori. Ciò che consente di effettuare campagne di marketing diretto:
(a) ottenere indicazioni su come modificare la propria offerta (rivolgendosi di volta in volta al target più remunerativo);
(b) monitorare l'evoluzione della clientela e la nascita di una nuova tipologia.
Un'applicazione particolare è il Geomarketing (marketing internazionale) che si occupa del "dove" produrre/distribuire il prodotto, si parla di segmenti geografici, Sistemi Geografici Informativi (GIS).
Analisi delle associazioni (basket analysi) associazioni tra dati di vendita di prodotti diversi, per conoscere quali prodotti sono acquistati congiuntamente; ciò consente di migliorare l'offerta (disposizione sugli scaffali) dei prodotti e di incrementare le vendite congiunte.
Analisi testuale (text mining); si tratta di tecniche di classificazione per individuare gruppi omogenei di documenti in termini di argomento trattato/lessico utilizzato.
Credit Scoring. Classificazione (da parte di una banca) delle aziende che chiedono finanziamenti in base ad indici di bilancio: ciò consente di ridurre i rischi di insolvenza.
Tecnology Watch (monitoraggio tecnologico, competitive, intelligence - monitoraggio della concorrenza). Analisi di banche dati a contenuto tecnico scientifico (ad esempio la banca dati dei brevetti). L'obiettivo è quello di individuare:
l'orientamento del mercato;
le aree tecnologiche emergenti;
quali aziende stanno investendo nelle nuove tecnologie;
quali saranno i concorrenti in futuro;
quali prodotti e quali strategie stanno preparando i concorrenti.
L'analisi è di tipo classificatorio gruppi omogenei di tecnologie; studio dell'andamento temporale del mercato e dei singoli concorrenti.
Esempio di data mining
Segmentazione della clientela. Catena di distribuzione di prodotti non alimentari. Gli obiettivi sono:
fidelizzare i clienti;
migliorare il servizio.
L'analisi dei dati è stata fatta attraverso le "carte fedeltà", quindi:
decine di migliaia di clienti;
per ciascun cliente sono stati raccolti i dati riguardanti:
transazioni effettuate
prodotti acquistati
giorni di acquisto, ecc.
Risultati
Classificazione dei clienti in gruppi omogenei, in base a caratteristiche geografiche e comportamentali d'acquisto.
Individuazione dei settori più visitati ed in quale momento del giorno, settimana, anno.
Legami tra settori.
Presentazione dei risultati
Ovali gruppi omogenei. All'interno di questi si rappresenta:
un numero progressivo in base alla numetosità del gruppo
la numerosità del guppo
gli acquisti più frequenti all'interno del gruppo.
Linee (che collegano due ovali) sono le affinità tra i gruppi corrispondenti (comportamenti simili); lo spessore ed il colore indicano l'intensità del legame.
Ulteriori applicazioni di tecnologie software in azienda
sistema informativo automatizzato (SIA);
sistema di elaborazione dati (EDP);
automazione d'ufficio (OA);
sistemi di supporto alle decisioni
alla produzione
alla progettazione.
(v. Testo par. 7.1,2,4,5).
RETI DI CALCOLATORI
È un insieme di calcolatori autonomi collegati tramite una rete di comunicazione. I calcolatori connessi alla rete hanno un certo grado di indipendenza, gli utenti possono interagire con la rete. Oltre alle reti, esistono i sistemi distribuiti, che sono somili alla rete ma i calcolatori sono privi di autonomia: gli utenti non interagiscono con la rete, ma solo con un terminale; è un sistema utilizzato per applicazioni speciali (esempio: Bancomat); i calcolatori sono dedicati, cioè predisposti ad un solo tipo di operazioni.
Le finalità di una rete sono:
condivisione di risorse (dati, programmi, stampanti, memoria di massa); siamo in presenza di reti di piccole dimensioni;
comunicazioni tra utenti fisicamente distanti (e-mail, scambio/reperimento di file); siamo in presenza di reti di grandi dimensioni;
miglioramento dell'affidabilità del sistema complessivo; sostituibilità tra risorse hardware/software.
Le tipologie di reti di calcolatori, in base all'estensione, si dividono in:
rete locale (LAN: Local Area Network); è una rete di limitata estensione, i dispositivi si trovano nello stesso edificio o in edifici vicini. La struttura di interconnessione può essere di 3 tipi:
a stella. Le caratteristiche sono: nodo centrale (server); connessioni individuali; alte prestazioni; possibilità di sovraccarico e blocco del server; cavi lunghi; connessione non alla pari;
ad anello. Le caratteristiche sono: connessione individuale a struttura circolare; l'informazione è ricevuta a turno e ritrasmessa da ogni stazione; alte prestazioni, scarsa flessibilità ed affidabilità;
bus condiviso. Le caratteristiche sono: trasmissione bidirezionale multipunto (non c'è connessione diretta tra server e computer periferico o tra due computer - negli altri due casi la connessione è di tipo "punto a punto"); semplice, flessibile, affidabile, bassi costi; prestazioni più modeste (unico mezzo di trasmissione). È la connessione più utilizzata.
rete metropolitana/geografica (WAN: Wide Area Network); è una rete di dimensioni superiori alla LAN; i dispositivi si trovano nella stessa area urbana (metropolitana) o in un'area più ampia (geografica);
rete di reti (Internetwork): è il collegamento di reti differenti. I collegamenti sono effettuati da calcolatori:
bridge: dedicati alla connessioni di reti locali;
gateway: dedicati alla connessioni di reti geografiche.
Il risultato finale è un'unica rete che consente ad ogni nodo di comunicare con gli altri.
Esempio aziendale di utilizzo di una rete: riorganizzazione attraverso una riduzione delle dimensioni (downsizing) si è passati da un'organizzazione centrale (mainframe - terminali) ad una distribuzione di informazioni e risorse; ci sono reti locali per le varie sedi, collegate tra loro tramite una rete geografica (evoluzione dal basso della rete aziendale). In questa tipologia di reti si avverte la necessità di integrazione di architetture differenti.
La tipologia di comunicazioni più utilizzata è quella LAN a bus condiviso, in cui si ha:
reti di tipo multi punto (broadcast);
canali di trasmissione condivisi da tutti i calcolatori della rete, anziché connessioni individuali tra coppie di calcolatori;
un identificatore univoco (indirizzo di rete) per ogni calcolatore. Questo comporta che un messaggio inviato in rete raggiunge tutti i calcolatori, ma solo quello destinatario (in base all'indirizzo presente nel messaggio) lo trattiene per l'elaborazione.
Modello semplificato di un modello di trasmissione



Il trasmettitore/ricevitore è un modem; il canale di trasmissione rappresenta i mezzi di trasmissione (cavi, onde radio, ecc.) che sono caratterizzati dallo spettro delle frequenze che sono in grado di trasportare (la frequenza rappresenta il numero di volte con cui un fenomeno periodico si ripete in una unità di tempo).
Esempio:
sorgente/destinatario calcolatore;
dati digitali generati dal calcolatore sorgente (programma di e-mail);
sistema di trasmissione: rete di calcolatori (canale digitale) connessione con dispositivo di input/output; linea telefonica (canale analogico) connessione con un modem;
bit aggiuntivi (di controllo) consentono al ricevitore di verificare l'eventuale presenza di errori;
codifica del messaggio per ottimizzare l'utilizzo del canale di trasmissione;
disturbi/rumori di trasmissione degrado della qualità del segnale (analogico): possibile inversione dei bit.
Altri esempi (segnali analogici) vedi testo pag. 161-162.
MEZZI DI TRASMISSIONE
Rappresentano il supporto fisico del percorso tra trasmettitore e ricevitore. Esistono 2 tipologie:
mezzi guidati, sono le linee fisiche che trasportano il segnale (elettrico o ottico) fino al ricevitore. Ad esempio doppino telefonico, cavo coassiale, fibra ottica;
mezzi non guidati, si ha l'irradiazione di segnali elettromagnetici. Ad esempio spazio trasmissione di onde radio.
Le caratteristiche e qualità della trasmissione sono valutate in base a:
capacità del canale: numero di bit che il canale può trasmettere nell'unità di tempo (bit o Mbit/sec.);
attenuazione del segnale: riduzione dell'energia del segnale al crescere della distanza, può essere migliorata attraverso l'uso di ripetitori che amplificano e ritrasmettono il segnale;
interferenze tra segnali (su cavi adiacenti): distorsioni nella trasmissione sorge la necessità di schermatura dei cavi (i disturbi nella trasmissione comportano degrado della qualità del segnale e quindi possibili inversioni dei bit).
Reti geografiche WAN Possono essere di 2 tipi:
v rete dedicata: la connessione tra calcolatori distanti avviene attraverso mezzi di trasmissione dedicati (ad esempio sedi di un'azienda); è efficiente e sicura ma presenta costi elevati.
v rete commutata a 3 livelli:
rete di trasmissione canali di trasmissione e sistema di instradamento (IMP);
rete di calcolatori (host) collegati agli IMP;
rete degli utenti.
I dati sono immessi sulla rete da un host e vengono instradati alla destinazione passando da un IMP all'altro (ad esempio vedi figura 5.6 del testo a pag. 172). I costi sono modesti, l'efficienza è minore e la sicurezza è scarsa.
Negli ultimi anni si è assistito ad uno sviluppo di sistemi integrati tra i quali la rete ISDN (Interprate Services Digital Network). Le caratteristiche sono: standarizzazione internazionale per rete digitale commutata; ogni utente può collegarsi ed usufruire di tutti i servizi; maggiore automazione delle procedure, maggiore sicurezza. Caratteristiche principali / esempi di applicazioni vedi testo a pag. 178-181.
Reti locali LAN solitamente approccio broadcast (non esistono modi intermedi di commutazione). Vedi testo pag. 182-185.
Data la presenza di diversi tipi di reti, sorge il problema della connessione tra reti eterogenee, della comunicazione tra calcolatori indipendentemente dalla rete a cui sono collegati (pag. 190-195). Si ultilizzno allora i protocolli di comunicazione, i quali sono regole che:
formalizzano la cooperazione tra calcolatori al fine di consentirne la comunicazione;
specificano i formati dei dati, la struttura di pacchetti di dati (di piccole dimensione alcuni kbyte) che sono spediti uno alla volta;
la velocità di trasmissione.
Tra questi, c'è il TCP (Trasmission Control Protocol) che rappresenta l'insieme di protocolli sviluppato per consentire l'interoperabilità tra reti fisiche diverse. È l'insieme di protocolli standard per la rete internet (TCP/IP Internet Protocol) consente di collegare calcolatori in tutto il mondo. In particolare permette:
la realizzazione di applicazioni affidabili in reti geografiche;
la condivisione di informazioni tra varie organizzazioni connesse ad internet;
in particolare è implementato in quasi tutti i sistemi operativi.
Caratteristiche tecniche pag. 204-207.
Internet: è una rete di reti basata sul protocollo TCP/IP. Internet è anche un insieme di informazioni e di servizi disponibili sulla rete; ma è anche una comunità di individui che utilizzano la rete.
Evoluzione storica di Internet:
fine anni '60: ARPANET rete sperimentale di calcolatori del dipartimento della difesa degli USA, progettata per mantenere la proprie funzioni anche nel caso di disattivazione di alcune parti (guerra nucleare). Sono stati sviluppati percorsi alternativi per il trasferimento dei dati, l'instradamento (routing) è gestito automaticamente da ogni calcolatore, quindi l'organizzazione (protocolli TCP) è tale per cui la rete non ha un sistema di controllo e la responsabiltà della comunicazione è affidata ai calcolatori connessi. I messaggi sono organizzati in pacchetti di dati, il cui invio avviene dal calcolatore sorgente ad uno collegato; il calcolatore ricevente instrada nuovamente i dati, ecc., il destinatario finale è in grado di ricostruire il messaggio.
fine anni '70: ampliamento di ARPANET, si ha la connessione di mainframe e di centri di ricerca e Università.
anni '80: diffusione di workstation (con sistema operatico Unix dotato di funzioni di connessione di rete TCP) e di LAN. Si ha la connessione della LAN alla rete globale.
anni '90: consultazione on line di documenti.
I servizi di base, disponibili tramite TCP, sono:
telnet: utilizzo del proprio calcolatore come teminale di un calcolatore remoto, per sfruttare le risorse di quest'ultimo (ad esempio esecuzione remota di un programma, accesso a cataloghi di biblioteche e a banche dati remote, ecc.);
posta elettronica (e-mail): scambio di messaggi tra utenti; gestione di liste di distribuzione dei gruppi di utenti (ad esempio interesse ad un argomento di discussione). I file sono di tipo ASCII ai quali si possono aggiungere immagini;
trasferimento di file (FTP): distribuzione di software di libera diffusione raccolti in calcolatori, che consentono :
accesso anche ad utenti non identificati (anonymous);
consultazione di dati/software e copia sul calcolatore locale (downloading) degli utenti. In particolare:
software freeware: totalmente gratuiti;
software shareware: distribuzione libera, ma l'utilizzo è soggeto al pagamento di una somma all'autore;
software privato: è necessario il codice di accesso.
Ciò che ha reso popolare Internet è stato in nuovo modello di utilizzo: la consultazione on line di documenti, cioè l'accesso diretto al contenuto dei file tramite i servizi di Internet; la fase di downloading è diventata invisibile all'utente; si ha la c.d. biblioteca virtuale. I servizi che hanno resto possibile questo nuovo accesso sono:
v Gopher: servizio di ricerca e di consultazione di documenti testuali (senza grafica) attraverso brevi indici di descrizione dei documenti accessibili; il servizio è a menù, la seleziome di file e di programma (dai siti prescelti) avviene tramite il mouse, l'esplorazione è a cascata. I difetti principali sono:
ricerca di documenti solo testo;
ricerca effettuata solo con parole chiave.
v WAIS (Wide Area Information Server). È il primo tentativo di ridurre i difetti di Gopher; è un servizio che consente di ottenere la lista dei documenti presenti su di un calcolatore nel cui testo si trova un termine specificato dall'utente. È un sistema di indicizzazione basato sul contenuto testuale del documenti (non solo su di una breve descrizione); vi si accede tramite un sito internet che dispone di un programma di interrogazione.
v La vera rivoluzione è stata WWW (World Wide Web): rappresenta il punto di svolta per la diffusione sociale di Internet; è un metodo uniforme per catalogare tutto ciò che si trova sulla rete. Classifiuca le risorse di Internet attraverso la metafora del libro: pagine da sfogliare, con indici, richiami, ecc. Ha sensibilmente migliorato il servizio di Gopher; ha dato il via a:
generazione e visualizzazione di documenti in cui il testo può essere:
formattato (carattere di diverso tipo, dimensione, colore);
completo con immagini statiche o dinamiche (animazioni e filmati) e con suoni si ha multimedialità, cioè combinazione di diversi mezzi di comunicazione (testo, immagini, filmati e suoni);
elevato grado di interattività della consultazione: all'interno di un documento ci sono riferimenti attivi ad altri documenti (selezionando un riferimento, il programma preleva dalla rete il documento corrispondente e lo visualizza). Questo è il c.d. ipertesto: documento la cui struttura di consultazione non è sequenziale, all'interno del documento sono contenuti degli anchor point del documento (cfr. consultazione di una encicopedia non si consulta dalla prima all'ultima pagina, ma si va a ciò che interessa e poi si cercano i collegamenti).
Anchor point: "aree attive" la cui selezione attiva il legame (link) e visualizza il contenuto della parte selezionata.
In un documento multimediale/ipertestuale, si integrano informazioni differenti; ad esempio:
testi
programmi
immagini (programmi di grafica - foto)
suoni
animazioni/filmati (necessità di PC con elevate prestazioni, memoria grafica). Al crescere della risoluzione aumenta il numero di bit utilizzati per la memorizza.
Strategie di compressione dei dati testo pag. 217 - 218 (ad esempio formato JPEG per la compressione). Digitalizzazione di suoni trasformazione di onde sonore in segnali digitali (testo pag. 218).
Un'altra caratteristica che ha favorito la diffusione di Internet è la grande facilità di accesso al servizio, dovuta a programmi di consultazione (browser) basati su un interfaccia grafica, sull'uso del mouse (point and clik) ed interagenti con altri servizi (e-mail, ftp, ecc.). I principali browser sono:
Netscape navigator
Internet explorer.
Le pagine web sono scritte nel linguaggio HTML, che è il principale codice utilizzato per i documenti visualizzati sul WWW (l'estensione dil file è .htm o .html). Un file HTML contiene sia il testo che deve essere visualizzato dal browser, sia le istruzioni (TAG) relative alla formattazione e all'inclusione di oggetti multimediali (immagini, ecc.); questi documenti possono essere convertiti da/in Word. Esempi di istruzioni TAG sono:
<BR> a capo
<P> a capo con salto di linea
<HR> a capo e linea orizzontale
<IMG> visualizza un'immagine memorizzata in un file il cui nome è indicato all'interno dell'istruzione come valore dell'operazione SRC.
 Ad esempio, scrivendo: "Questa <IMG
SRC: image.gif> è una immagine <HR>" sarà visulizzato:
Ad esempio, scrivendo: "Questa <IMG
SRC: image.gif> è una immagine <HR>" sarà visulizzato:
Questa è una immagine
Nella rete, un aspetto importante è l'identificazione delle risorse, cioè stabilire delle regole per assegnare un nome univoco ai singoli calcolatori (nodi) connessi alla rete. In particolare (uso del protocollo TCP/IP); l'indirizzo IP è un indirizzo di 32 bit (4 byte separati da punti, ciascuno in notazione decimale). Ad esempio: 160.78.48.1 è il server che gestisce la posta elettronica presso il Centro di Calcolo Inter Facoltà. Se si considerano i numeri, sorge un problema di ricordo, si passa allora ad un sistema DNS (Demain Name System), il quale associa ad ogni indirizzo IP un indirizzio simbolico; ad esempio 160.78.48.1 diventa: ipruniv.cce.unipr.it. si hanno stringhe alfanumeriche separate da punti che rappresentano i diversi domini:
it: Italia;
unipr: Università di Parma;
cce: Centro di Calcolo di Elaborazione ;
ipruniv: nome del calcolatore.
L'identificazione dei file fa invece riferimento agli URL (Uniform Resorse Locator): identificano ogni file contenuto nel file system di un server; ad esempio: https://www.unipr.it/siti/homepage.htlm identifica la sede dell'Unversità di Parma (h.ttp protocollo per la navigazione.
Gli utenti di un server sono identificati attraverso il proprio nome (user ID) univoco per il server; ad esempio: pippo@server.it.
Aspetti operativi: (testo pag. 236 - 239 ed esericitazioni di Internet)
specificazione di un URL indirizzo della pagina web;
come trovare le informazioni: struttura tipica di un sito;
indici (directory) programmi che catalogano le informazioni su Internet in base algli argomenti;
motori di ricerca (search engine) programmi che ricercano attivamenti le informazioni, esplorando la rete alla ricerca di parole o concetti chiave.
uso della posta elettronica;
come acquisire le informazioni.
Gli aspetti etici del web sono elencati nelle netiquette.
La grande diffusione di Internet è dovuta anche al software impiegato per l'utilizzo dei suoi servizi; infatti tale software può essere utilizzato anche per gestire i servizi di una LAN (posta elettronica, trasferimento file, distribuzione di documenti, ecc.).
Si parla di Intranet per definire le reti locali che impiegano i servizi di Internet; i vantaggi sono:
elevata qualità dei servizi;
standardizzazione;
costi ridotti (i programmi su trovano sulla rete).
La LAN è quindi vista come una versione ridotta di Internet. La connessione Intranet/Internet avviene condividendo le risorse Intranet con tutti gli utenti di Internet. In molti casi questo è un vantaggio, ad esempio:
la pubblicazione di programmi/dati da parte di un ente di ricerca i potenziali lettori sono tutti i lettori di Internet;
informazioni sui corsi di Economia;
possibiltà per iclienti di un'azienda di effettare ordini on line;
In alcuni casi sorge però il problema della sicurezza (testo pag 241 - 242). È allora introdotto il concetto di gestione degli accessi: si individua in unico punto di accesso in entrata/uscita dalla Intranet (fire wall); tale elaborazione effettua controlli sugli accessi, consentendo solo queli degli utenti autorizzati. Si ha quindi:
servizi di Internet tutti gli utenti;
servizi di Intranet solo LAN;
servizi di Extranet anche al di fuori della LAN ma solo ad utenti abilitati (esempio clienti di un'azienda).
![]()
Cos'è Internet?
Come nasce Internet?
Cosa si trova in Internet?
Le regole fondamentali di Internet
World Wide Web
I Browser
Motori di Ricerca
Bibliografia
Cos'è Internet?
Internet è la rete delle reti, nella quale si affacciano laboratori di ricerca, Università, servizi telematici, enti governativi centrali e periferici, banche dati, aziende, strutture scientifiche, scuole di ogni ordine e grado, studenti, professionisti, persone comuni, ecc. Internet nasce poco meno di 30 anni fa come piccola rete delle reti, come una confederazioni di network diversi che si diedero delle regole e dei protocolli comuni per parlare tra di loro attraverso un sistema aperto.
Internet non è un luogo fisico, in quanto è stata pensata senza un centro nevralgico, in quanto alle origini, come vedremo di seguito, era stata strutturata come una rete militare decentrata al fine di evitare il rischio di un black-out a causa di distruzione bellica; in Internet, quindi, una volta inviato un messaggio, questo viaggia nella rete da un nodo all'altro, superando le eventuali interruzioni semplicemente prendendo un'altra strada e girando attorno all'ostacolo. L'avvento di Internet porta anche ad una totale ridefinizione dei concetti di spazio e di tempo; la "vicinanza" o la "lontananza" tra due network è infatti segnata dalla qualità, dalla velocità, dal tasso di errore della connessione e non dalla distanza fisica.
Come nasce Internet?
Possono essere delineate quattro fasi di sviluppo della rete Internet.
Internet nasce nel 1969 (prima fase) con il nome di Arpanet, il network dell'ARPA (Advanced Research Projects Agency), voluta dal Dipartimento della Difesa Americano per creare una rete che collegasse, con le normali vie telefoniche, calcolatori sparsi nel territorio nazionale, e capace di resistere nel caso in cui una guerra avesse intaccato parte della rete: Internet nasce,
quindi, non come un progetto accentrato, ma come una struttura nella quale ogni calcolatore fosse autonomo nella sua comunicazione con gli altri, in quanto in caso di guerra il primo bersaglio militare sarebbe stato il centro di calcolo accentrato.
Internet iniziò collegando tra loro 4 computer: tre in California e uno nello Utah, utilizzando il Network Control Protocol (NCP).
Il rigido controllo militare non si è in realtà mai verificato e quindi il progetto, fin dal suo sorgere, è stato gestito più come risorsa universitaria che non come istituzione militare.
In un secondo momento, tra la fine degli anni '60 e l'inizio degli anni '70 (seconda fase), anche il mondo scientifico iniziò ad utilizzare questa modalità di trasmissione delle informazioni; la crescita della rete Internet è legata alla collaborazione tra ricercatori: lo spirito collaborativo e volontaristico (che rimane anche oggi uno dei tratti caratteristici della rete), lo scambio di posta elettronica, di messaggi e la collaborazione a distanza in ricerche e progetti sono stati i motori che hanno permesso un rapido sviluppo della rete.
Sempre in quegli anni si assiste allo sdoppiamento di Arpanet in Milnet, la rete militare vera e propria, e Internet, la rete scientifica.
Nel 1971 c'erano 23 hosts nel network ma già nel 1980 erano diventati 200, alcuni dei quali al di fuori degli Stati Uniti.
La terza fase dello sviluppo di Internet coincide con gli anni '80. In quel decennio tre erano i maggiori network: BITNET (Because It's Time Network), CSNET (Computer Science Network), NSFnet (National Science Network) che diventerà la principale rete portante di Internet (detta backbone o spina dorsale) prima a 56Kbps, poi portati a 1544 Mbps nel 1989.
Sempre negli anni '80 si assiste all'ingresso in rete di nuovi utenti, estranei alla comunità scientifica. Vengono costruite delle comunità virtuali, non più fondate sul senso di appartenenza territoriale, ma nelle quali i soggetti sono accomunati da etiche di rete e linguaggi condivisi. Paradossalmente Internet, un medium creato in piena guerra fredda, diviene lo strumento privilegiato per la comunicazione delle comunità pacifiste ed ecologiche internazionali.
Negli anni '90 (quarta fase) lo sviluppo di Internet è caratterizzato dal forte sviluppo delle interfaccie grafiche sofisticate, che attirano il mondo degli affari e del commercio, oltre che quello delle pubbliche amministrazioni.
Questi i principali sviluppi di Internet negli anni '90:
viene eliminata la rete Arpanet;
viene creato il Commercial Internet Exchange (CIX) per permettere agli utenti commerciali di evitare il divieto di NSFnet (a sua volta privatizzata) di commercializzare prodotti lungo il suo network;
l'Università del Minnesota introduce Gopher: da allora la rete non sarà più solo utilizzata per la trasmissione di posta elettronica;
1992 il CERN di Ginevra introduce quello che oggi è diventato il programma più utilizzato su Internet: un sistema multimediale ad ipertesto con tecnologia client/server chiamato World Wide Web (WWW);
1992: l'Università dell'Illinois rilascia l'interfaccia utente Mosaic per utilizzare WWW;
a metà del 1994 vi erano nel mondo più di 2,2 milioni di hosts registrati e circa 25 milioni di utenti; nel gennaio del 1996 gli hosts registrati erano già saliti a oltre 9 milioni.
Lo sviluppo odierno della rete nel mondo (dati relativi al gennaio 1997): USA sono il più alto paese a sviluppo telematico con 8,2 milioni di hosts; seguono, a grande distanza, la Gran Bretagna con 570.000, la Germania con 548.000, il Giappone con 6.000, il Canada con 424.000, l'Australia con 397.000, la Finlandia, l'Olanda, la Francia, la Svezia, la Norvegia, e infine l'Italia (in dodicesima posizione con 113.000 hosts).
Lo sviluppo odierno della rete in Italia: la recente ricerca dell'Osservatorio Telematico Alchera stima, al marzo 1997, in 1.400.000 i navigatori italiani di Internet (con questo identikit: sesso maschile, età tra i 14 e 34 anni; istruzione universitaria; impiegato o studente; residente nel Centro-nord; reddito familiare superiore ai 3 milioni mensili). Il 2,9% della popolazione (contro il 1,2% della precedente analisi) è collegato ad Internet.
Come nasce la rete in Italia: il primo ente che si è collegato ad Internet è stato l'Istituto Nazionale di Fisica Nucleare; nel 1988 viene creato il GARR (Gruppo per l'Armonizzazione delle Reti per la Ricerca), che mirava ad organizzare e gestire l'interconnessione delle reti universitarie, formato in maniera cooperativa da grandi consorzi informatici (CINECA, CILEA, CSATA CNR, INFN; ENEA, finanziata dal MURST). La rete GARR presenta una buona architettura, ma con alcuni problemi di distribuzione della velocità di trasmissione, in particolar modo nella connessione con la rete commerciale.
Cosa si trova in Internet?
Dati di qualsiasi tipo, consultabili 24 ore al giorno, sia in formato testuale (Gopher) che attraverso una potente interfaccia grafica (WWW);
files e programmi di più o meno pubblico dominio (versioni freeware o shareware) prelevabili tramite ftp;
E-mail o posta elettronica, che permette di mandare e ricevere messaggi (testo, immagini, suoni, file);
Newsgroup, chat di discussione;
possibilità di teleconferenze.
Le regole fondamentali di Internet
I protocolli di trasmissione: il più utilizzato è il TCP/IP (Transfer Control Protocol/Internet Protocol).
I domini di appartenenza: ogni utente in Internet ha un proprio indirizzo che lo identifica in modo univoco ed ha, nella maggior parte dei casi, la seguente struttura:
<parte locale>@<dominio>
modonesi@spbo.unibo.it
president@whitehouse.gov
parte locale: identifica l'utente, normalmente è il suo account (o login) sulla macchina con la quale si connette alla rete, cioè il nome con il quale il sistema riconosce e lo abilita all'uso della sua parte di disco fisso e di memoria.
si legge "at" e vuol dire "su", "presso".
Dominio: leggendo da destra a sinistra i sottonomi separati da un punto, si ottiene il percorso che porta dalla totalità della rete al nome proprio della singola macchina.
it = Italia
unibo = Università di Bologna
spbo = Facoltà di Scienze Politiche di Bologna.
Negli Stati Uniti, dove Internet è nata, per indicare i domini interni si utilizzano le seguenti sigle che contraddistinguono le diverse tipologie dei siti:
.com = società commerciali;
.edu = enti accademici;
.mil = organizzazioni militari;
.gov = organizzazioni governative;
.org = organizzazioni non-profit;
.net = identifica un network.
Con l'espansione della rete nel mondo i nomi del dominio sono stati standardizzati in due lettere, indicanti la nazione nella quale era installato il server:
.it = Italia;
.fr = Francia;
.ca = Canada;
.jp = Giappone;
.uk = Regno Unito...
World Wide Web
Il WWW o W3 sta per World Wide Web, cioè Ragnatela estesa a tutto il mondo o Mondiale. È un sistema di strutturazione dell'informazione in rete. L'esigenza di condividere le informazioni attraverso la rete ha portato nel 1992 il CERN di Ginevra a sviluppare il progetto WWW, che mirava sia a superare le barriere geografiche che impediscono la collaborazione fra gruppi scientifici, sia ad accelerare lo scambio di informazioni attraverso protocolli standardizzati.
In principio fu utilizzato un interfaccia a caratteri, ma il grande successo commerciale di questa modalità è dovuto alla possibilità di utilizzo di browser con interfaccia grafica che consentono di visualizzare immagini, testi, suoni, video. L'interfaccia Web si basa, infatti, sulla comunicazione ipertestuale multimediale: le informazioni non sono più organizzate in maniera sequenziale, ma in una struttura reticolare che utilizza collegamenti o link (testo evidenziato o sottolineato, icona, immagine, mappa sensibile) a pagine (nodi) contenenti informazioni diverse. Tramite il protocollo HTTP (Hyper Text Transfer Protocol) è infatti possibile la consultazione di testi ipermediali.
I dati (testi, immagini, suoni, video) vengono immessi nella rete dopo essere stati tradotti in un unico formato, o linguaggio, l'HTML (Hyper Text Markup Language), che costituisce lo standard di lettura per i client browser di WWW.
L'architettura del WWW è di tipo client-server: vi è un sistema, un'entità che offre un servizio (il server) ed un'altra (il client-browser) che vi accede usufruendone: collegandosi al server usando il protocollo HTTP l'utente richiede un documento (funzione client) e poi lo visualizza (funzione browser). Il server, in caso di successo della richiesta di collegamento, provvede al trasferimento del documento in formato HTML, altrimenti invia un messaggio di errore, anch'esso in formato HTML. Sarà poi compito del client rielaborare il documento.
L'identificazione dei documenti: l'indirizzo. È necessario un sistema di indirizzamento in grado di individuare i computer collegati in rete, o chiamati in termine tecnico siti. Si tratta di indirizzi composti di numeri intervallati da punti che vengono riconosciuti dal computer, ma che risultano di difficile utilizzo per l'utente in quanto non facilmente memorizzabili. Per rendere il sistema in grado di effettuare una ricerca e una lettura in maniera uniforme si è creato uno standard per l'identificazione univoca dei documenti; questo standard di chiama: URL (Uniform Resource Locator), o indirizzo. Gli URL hanno la seguente sintassi: scheme://host.domain/path/
protocollo://nomesito/percorso/nomefile h
https://spbo.unibo.it/pais/giovgraz/
scheme indica il tipo di protocollo seguito da ://
https:// se ci si deve collegare ad un server;
telnet:// se si deve aprire una connessione con un'altra macchina;
ftp:// se si deve recuperare un file;
file:// se si deve recuperare un file in locale;
mailto: per spedire posta elettronica;
news: se si deve leggere o recuperare una news o un gruppo;
gopher:// se si deve recuperare informazioni su un gopher.
host.domain indica il nodo nel quale risiede il documento (es. spbo.unibo.it = il server della Facoltà di Scienze Politiche dell'Università di Bologna; www.repubblica.it = il server del quotidiano La Repubblica, ecc.);
path indica il cammino per recuperare sul server il documento (es. /pais/giovgraz indica che il documento desiderato si trova nella directory pais e nella subdirectory giovgraz).
I Browser
Viene definito browser l'apposito programma che permette la navigazione nel WWW. Il primo browser grafico sviluppato è stato NCSA Mosaic, e dopo questo ne sono stati sviluppati diversi: attualmente quelli maggiormente utilizzati sono Netscape Navigator e Internet Explorer della Microsoft. Di entrambi è disponibile la versione 3.0. Il browser della NCSA e quello Microsoft sono distribuiti gratuitamente, freeware, mentre Navigator è distribuito gratuitamente per chi non ne fa un uso commerciale. Netscape e Mosaic sono disponibili per tutti i sistemi operativi mentre Explorer è disponibile solamente per Win95, Windows NT e Mac.
Netscape Navigator è fino ad oggi il browser più diffuso nel mondo (alcune statistiche gli attribuiscono il 75% del mercato).
Netscape Communication Corporation è stata la prima azienda a impegnarsi con grandi mezzi finanziari e umani nella progettazione di software per Internet. Diffuso gratuitamente per mesi su Internet. Le nuove versioni 2.0 e 3.0 sono arricchite da programmi per la gestione della posta elettronica e dei Newsgroup direttamente via software di navigazione; inoltre è possibile la suddivisione delle finestre in frames, in sottofinestre indipendenti. Il software supporta applicativi Java (il linguaggio di programmazione proposto da SUN, che permette di produrre programmi indipendente dal sistema operativo usato).
La finestra di Netscape Navigator dispone di un sistema di menù e di una serie di pulsanti ad icona, che permettono di utilizzare pienamente il programma. L'interfaccia è di tipo grafico-gestuale (grafico poiché il puntatore del mouse, in presenza di determinati oggetti quali link, mappe sensibili, ecc assume una forma ben precisa).
Microsoft Internet Explorer 3.0 è la risposta della Microsoft alla Netscape Communication, l'azienda che detiene il controllo della navigazione in Internet. Per contrastare Netscape la Microsoft ha deciso di mettere gratuitamente a disposizione Internet Explorer nel suo ultimo sistema operativo: Microsoft '95. IE è in grado di supportare le funzione elevate del linguaggio HTML: testi scorrevoli, video in formato .avi, suoni, effetti grafici sul testo (trasparenze), applet Java, ecc. Il programma presenta le classiche barre comandi Windows, e riprende l'organizzazione dei pulsanti tipica di Netscape, anche se con qualche piccolo cambiamento.
Motori di Ricerca
La necessità di reperire le informazioni nel mare disorganizzato di Internet ha fatto nascere dei siti appositamente dedicati alla ricerca di informazioni. La loro genesi è stata quasi amatoriale, ma poi si sono imposti sempre più all'attenzione dei navigatori, divenendo dei veri e propri punti di riferimento, trasformandosi la loro natura amatoriale in commerciale. Il loro utilizzo rimane infatti gratuito, ma nel sito sono in vendita spazi pubblicitari. Due sono i siti di questo tipo: i cataloghi (grandi raccolte di URL ordinate per argomento) e i motori di ricerca (o spider, che permettono di inserire chiavi di ricerca in base alle quali viene effettuata un'interrogazione del database di pagine disponibili presso il sito).
Il funzionamento dei motori di ricerca è pressoché identico. Generalmente sotto il logo del sito compare un box di forma rettangolare nel quale è possibile scrivere. Questo box fornisce al programma la parola chiave in base alla quale svolgere la ricerca; per dare inizio alla ricerca è necessario cliccare sopra ad un bottone che porta una scritta del tipo search, go, submit. Per accelerare la ricerca conviene fornire più parole chiave. In questo secondo caso è utile fare ricorso agli operatori booleani AND, OR e NOT che vengono utilizzati dai motori di ricerca per collegare tra loro le parole chiave: and prevede la necessità che siano soddisfatte tutte le opzioni di ricerca (Università and Scienze Politiche = tutte le Università con la facoltà di Scienze Politiche); or richiede che sia soddisfatta almeno una delle due condizioni (Università or Scienze Politiche = tutte le Università o tutte le facoltà di Scienze Politiche); l'operatore not è soddisfatto solo nel caso in cui non esista nessuna delle opzioni che precede (Università not Scienze Politiche = tutte le Università ad esclusione di quelle con la facoltà di Scienze Politiche).
Questo è l'elenco dei principali motori di ricerca:
Yahoo - https://www.yahoo.com/ (server ibrido)
classico catalogo on-line, ideato da due studenti della Stanford University; server ibrido, in quanto esegue ricerche utilizzando chiavi di interrogazione di un database di siti. Accanto ai box di scrittura vi è un elenco di argomenti che fa riferimento alle pagine-indice.
Lycos - https://www.lycos.com/ (motore)
spider storico di Internet; puntatori di indice per argomento.
Altavista - https://altavista.digital.com/ (motore)
nato verso la fine del 1995; si è imposto per la velocità e l'accuratezza delle analisi; svolge ricerche anche all'interno di Newsgroup; consente l'accesso a 16 milioni di pagine indicizzate.
InfoSeek - https://guide.infoseek.com/ (motore)
fornisce gratuitamente solo liste parziali (circa 100 pagine): per avere l'elenco completo delle informazioni bisogna pagare l'abbonamento.
Web Crawler - https://www.webcrawler.com/ (motore)
nato da un progetto dell'Università di Washington; ricerche veloci, complete, ordinate.
Excite - https://www.excite.com/ (motore)
sito multiuso.
Yellow Pages - https://www.yellow.com/ (motore)
pagine gialle specializzate nella ricerca di siti aziendali e commerciali.
The WWW Virtual Library - https://www.w3.org/vl/ (catalogo)
costituita presso il CERN; presenta un catalogo ricco e approfondito che però riflette i gusti della cultura europea.
Siti italiani:
The Italian General Subject Tree - https://www.mi.cnr.it/IGST/
elenco di siti italiani divisi per argomento; gestito dal CNR è il nodo italiano della Virtual Library.
Lista risorse NIR italiane - https://www.cilea.it/WWW-map/NIR-list.html
elenco delle risorse divise per localizzazione geografica o per appartenenza ad enti o associazioni.
Arianna - https://www.arianna.it/
Il primo motore di ricerca italiano.
Bibliografia
Mazzocchi, Tognoli, 1995, Rispieghiamo Internet per chi era assente,
Castelvecchi.
Berretti, Zambardino, 1995, Internet. Avviso ai naviganti, Donzelli.
Pateris, 1996, Internet per chi studia, Apogeo.
Vitale, 1996, Cyberguida, Datanews.
II PARTE: ANALISI STATITISTICHE CON EXCEL E SPSS
RICHIAMI STATISTICI:
Matrice dei dati.
![]()
![]() x11 . x1s . x1p
x11 . x1s . x1p
![]() .
.
X= xi1 . xis . xip
n*p .
xn1 . xns . xnp
L'elemento xis = modalità che nella unità statistica i-esima, presenta il fenomeno s-esimo (tipologia delle unità statistiche; significato dei vettori colonna e dei vettori riga).
Le analisi statistiche saranno:
descrittive (vedi "Analisi dei dati statistici"):
analisi univariata:
indici di posizione;
indici di variablità;
forme di distribuzione.
analisi bivariate:
correlazione;
regressione;
cograduazione.
analis di serie stiriche:
adattamento funzione interpolante;
previsioni/estrapolazioni;
numeri indici.
inferenziali:
campionamenti generazione di numeri aleatori;
distrizuzione gaussiana:
calcolo dei percentili;
verifica di adattamento;
inferenza da un campione:
intervallo di confidenza per m p
verifica di ipotesi su m p
inferenza da due campioni:
verifica di ipotesi m m
verifica di ipotesi p p
Le analisi di statistica II sono facoltative.
1° DATA SET.
Costruiamo la distribuzione di frequenza:
determiniamo il minimo ed il massimo (range)
costruiamo una colonna di reddito in milioni ("B2/1.000.000")
costruimao una colomma estrami (5 classi): 20 23 26 29 32
costruimao una colonna "Classi di reddito":
fino a 20, o da 17 a 20
calcoliamo la distrbuzione di frequenza: Inserisci Funzione Statistica Frequenza, la matrice dei dati è la colonna dei redditi/1.000.000; la matrice delle classi è la colonna degli estremi.
Quando l'output di una formula è un isieme di valori da incollare su diverse celle, si deve usare la "formula sella matrice" dalla finestra di dialogo della formula invece di digitare INVIO si digita: CTRL + SHIFT + INVIO.
Fatta la distribuzione di frequnza possiamo ora fare il grafico (istogrammi). Data la funzione continua gli istogrammi del grafico devono eddere contigui non staccati si selezionano gli istigrammi poi si va nel menù OPZIONI e si seleziona distanza = 0 (vedi Scagni par. 9.2). In caso di densità di frequenza, non è possibile fare il grafico in automtico, ma è necessario farlo manualmente, con la barra degli strumenti grafici.
Possiamo calcolare anche la distribuzione di frequenza dei comuni. In questo caso si tratta di modalità qualitative e non quantitative, risulta necessatua una codifica:
creiamo una colonna di 1 accanto a quella delle modalità;
selezionaiamo le due colonne;
andiamo nel menù DATI consolidamento (funzione che permette di fare alcune semplici operazioni per diversi sottogruppo) somma.
Attraverso la funzione di consolidamenti è anche possibili calcolare le medie parziali: tra le funzioni del consolidamento si sceglie media anziché somma. Le medie così calcolate non son ponderate (sulla popolazione residente). In Excel non c'è un afunzione di media ponderata per cui:
calcoliamo il reddito totale (reddito per popolazione);
incolliao accanto a questa colonna le etichette (M/P/C);
facciamo il consolidametno (somma);
calcoliamo la media ponderata (somma redditi/somma popolazione).
2° DATA SET.
Analisi esplorativa:
media (inserisci formula media)
mediana, due possibilità:
oridiniamo i valori e prendiamo il centro;
funzione mediana.
quartili (funzione quartile, specificare quale quartile);
range (max - min);
s funzione deviazione standard, che può essere:
Deviazione standard nell'inferenza;
Deviazione standard pop. in statistica descrittiva.
varianza funzione varianza (anche qui di 2 tipi, stessa interpretazione);
costruiamo la distribuzione di frequenza:
a. estremi delle classi: 25 50 75 100 125
b. classi (fino a 25; '25 - 50, '50 - 75, '75 - 100, '100 - 125);
c. funzione frequenza (formula della matrice);
d. grafico dal quale si deduce una forte asimmetria;
indice di asimmetria (formula);
indice di curtosi
calcoliamo il box plot che si basa su:
quartili;
differenza interquartile;
punti di troncamento (inf. x25 - DI =max tra questo valore ed il minimo esservato =20; sup. x75 + DI = 68);
cerchiamo tutti i valori anomali (ripsetto a 68) formula conta se > 68: risultano 3 possibili dati anomali.
Cerchima ora le relazioni con le altre variabili (cerchiamo la più esplicativa).
cerchiamo quella più esplicativa attraverso lo studio dei coefficienti di correlazione (n° di imprese manifatturiere;
determiniamo gli indici di derminizione (bontà di adattamenti della retta di regressione = (coefficiente di correlazione)2 = 12);
costruimao la retta di regressione (y = a + bx2):
intercetta (a): funzione intercetta;
coefficiente angolare: funzione pendenza
FARE IL DIAGRAMMA DI DISPERSIONE.
SEMINARIO DELLA PROF.SSA ZILIANI
È un nuovo mezzo di comunicazione. La radio, per raggiungere i suoi primi 50milioni di utenti, ha impiegato 38 anni; la TV ne ha impiegati 18; Internet soltanto 5.
In Internet la comunicazione è:
interattiva;
personalizzata;
persuasiva;
più informativa e documentale;
articolata in diversi percorsi;
più difficele perché nuova e l'utente è attivo;
controllata dall'utente;
misurabile.
Internet non è solo un mezzo di comunicazione, è infatti possibile effettuare, tramite esso, transazioni: è un luogo virtuale di incontro tra domanda e offerta; è un mercato virtuale.
Il mercato Internet è quindi:
virtuale (non c'è nella realtà fisica);
trasparente (c'è abbondante informazione);
senza confini;
senza distanze.
Da questo si evince che Internet è il mercato più simile ai "modelli di mercato" proposti dalla micro e dalla macroeconomia.
Gli effetti economici di Internet
Nel mercato virtuale, l'informazione è più abbondante e disponibile rispetto al mercato fisico.
Calano i costi relativi all'informazione; si riducono i costi di transazione legati all'informazione.
Le imprese ed i settori possono riorganizzare la loro attività.
Le reti di imprese si svilupperanno ulteriormente.
La leadership geografica perde di importanza.
L'attività di coordinamento che svolgono gli intermediari sarà meno costosa e più facile da realizzare perciò, si crea spazio per nuovi intermediari anche dove non esistevano.
In Internet le barriere all'entrata si riducono.
Riorganizzazione dell'attività
La funzione dell'azienda è quella di creare valore per il consumatore. Questo valore è misurato dal prezzo che il consumatore è disposto a pagare per quel prodotto; se il prezzo è maggiore del costo l'impresa ha creato valore, se il prezzo è minore del costo l'impresa non ha creato valore. Il valore immesso sul mercato si condensa in un prodotto/servizio; nel mercato fisico il prodotto è costituito da 3 elementi che sono:
contenuto
contesto
infrastruttura (ciclo logistico che il contenuto deve fare per arrivare al consumatore).
(Esempio del giornale)
Nel mondo fisico il produttore deve occuparsi di questi tre aspetti, nel mondo virtuale questi stessi aspetti possono essere gestiti da soggetti diversi. Esempio l'informazione l'articolo (contenuto) resta il medesimo del mondo fisico; il contesto diventa la pagina Web (Yahoo); l'infrastruttura è il PC. I soggetti economici possono quindi specializzarsi: un'impresa può decidere di fare solo contenuto, un'altra può fare solo contesto; ecc.. La specializzazione porta minori costi e maggiore soddisfazione dei bisogni. Chi produce contenuto ha più sbocchi al mercato; le tre componenti del valore possono essere offerte separatamente.
CASO AZIENDALE
Si tratta di un fornitore di contesto: Virtual Vineyards. L'azienda è nata nel 1994.
Si parla di commercio elettronico in senso stretto intendendo tutte quelle transazioni che hanno origine e che sono concluse in rete; si parla invece di commercio elettronico in senso lato intendendo tutte le transazioni/comunicazioni che avvengono in rete, che abbiano o meno attinenza con l'acquisto e che il pagamento sia o meno fatto via rete.
I prodotti adatti al commercio elettronico sono:
prodotti il cui acquisto è influenzato dalla raccolta di informazioni al momento dell'acquisto;
prodotti con offerta ampia ma non disponibile tutta insieme, perché altrimenti si competerebbe con i prezzi;
prodotti il cui valore può essere aumentato aggiungendovi le informazioni di un esperto;
prodotti i cui fornitori trovino conveniente il ricorso al canale virtuale, ma non direttamente.
L'azienda ha bisogno di (sotto il profilo organizzativo):
tecnologia, il contenuto tecnologico deve essere:
il vantaggio competitivo
facile e accativante
orientato alla vendita ma anche alla cultura
deve dare sensazione di comunità
deve considerare le caratteristiche dei siti Web.
operations:
relazioni con i fornitori (responsabilità del posizionamento);
magazzino e gestione scorte (collegamento con gli ordini);
vendita a prezzi concordati con i fornitori;
confezionamento e spedizione con vettori.
marketing:
segmentazione e targeting;
pubblicità su WWW;
pubblicità su altri media;
maling least elettronica;
costruzione ed analisi data base sui clienti.
COSA CHIEDERSI . PRIMA
Il mio prodotto è adatto al commercio elettronico?
I suoi attributi, possono essere trasferiti nel mercato virtuale?
Posso aumentare il valore per il cliente con l'aggiunta di informazione?
Chi è il mio cliente nel mercato virtuale?
Perché dovrebbe visitare il mio sito?
Come sfruttare la possibilità di brand extension?
Prevale la brand loyalty o la store loyalty?
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2025