|
|
| |
LABORATORIO DI SISTEMI
OGGETTO: La gestione dello stack: scrivere un programma in Assembly e commentarlo, per una CPU Intel 8086, che effettui il push di due valori nello stack, definito in precedenza, ed il pop dell'ultimo valore inserito nello stack stesso
ALGORITMO
INIZIO
![]()
DICHIARA VARIABILI DA UTILIZZARE (VAR)
![]()
INIZIALIZZA VAR = 1111
![]()
DEFINISCI STACK DI 40 LOCAZIONI
![]()
SETTA REGISTRI
![]()
AX = 3BC2
![]()
PUSH AX
![]()
PUSH VAR
![]()
POP BX
![]()
FINE
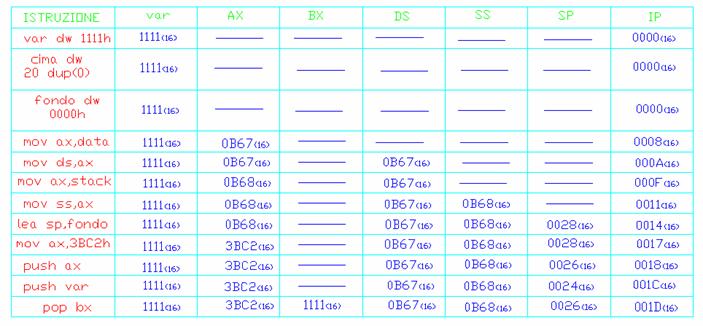
FILE SORGENTE
AUTHOR Claudio Fratto
; DATE 07-01-2008
; FILE Lifo.ASM
#MAKE_EXE#
DSEG SEGMENT 'DATA ' ; definizione ed inizio del segmento dati
var dw 1111 h ; dichiaro una variabile a 16 bit e la inizializzo
; con il numero 0x1111
DSEG ENDS fine del segmento dati
stack segment ; inizio del segmento dello stack
cima dw 20 dup(0) ; definizione della lunghezza dello stack.
; ognuna delle 40 locazioni viene riempita con 0000
fondo dw 0000 h ; definizione di un etichetta utile per fare un corretto
; riferimento alle locazioni utilizzate nello stack
stack ends ; fine del segmento dello stack
CSEG SEGMENT 'CODE ' ; definizione ed inizio del segmento del codice
START PROC FAR
PUSH DS
MOV AX
PUSH AX
; inizio settaggio registri
; inizio settaggio registro DS
MOV AX , DSEG
MOV DS AX
; fine settaggio registro DS
MOV ES AX
; inizio settaggio registro SS
MOV ax , stack
MOV SS ax
; fine settaggio registro SS
; fine settaggio registri
lea sp , fondo ; caricamento del'indirizzo effettivo, della locazione con
; indice più alto del nostro stack, nel registro SP
mov ax , 3BC 2h ; caricamento del valore 3BC2 nel registro ax, utilizzando
; un indirizzamento immediato
push ax ; caricamento, nella prima locazione libero dello stack, del
; valore contenuto nel registro ax
push var ; caricamento, nella prima locazione libero dello stack, del
; valore contenuto nella locazione che fa riferimento
; all'etichetta var
pop bx ; caricamento nel registro bx del valore contenuto nell'ultima
; locazione occupata dello stack
RET
START ENDP
CSEG ENDS ; fine del segmento del codice
END START
TRACE TABLE
RELAZIONE
L'esperienza effettuata in laboratorio si è articolata in due fasi:
la prima fase consisteva nel creare l'algoritmo del problema da risolvere esposto nell'oggetto, per poi creare il file sorgente corrispondente, scritto in linguaggio Assembly;
la seconda fase consisteva nel compilare e simulare il programma sorgente attraverso l'ambiente di simulazione (compilatore ed emulatore) Emu8086.
CENNI TEORICI SULLO STACK (PILA)
Con il termine stack, in informatica, si identificano molteplici funzioni a seconda dei diversi contesti in cui viene adoperato.
Significato generale dello stack
Nel contesto più generale esso sta a rappresentare una struttura di dati dinamica gestita attraverso l'utilizzo della modalità LIFO (Last In First Out). Questa struttura di dati viene comunemente chiamata pila.
In una pila sono consentite soltanto due operazioni: l'operazione di inserimento (push) e l'operazione di estrazione (pop). La caratteristica principale della struttura è che sia l'inserimento che l'estrazione possono avvenire soltanto da una estremità. Conseguenza di ciò è che:
si può inserire un singolo elemento per volta ed ogni elemento che si inserisce deve essere posto sopra gli elementi già presenti nella struttura dati;
si può estrarre un singolo elemento per volta ed ogni elemento che si estrae deve essere quello posto nella parte superiore della struttura: in altre parole l'elemento che si estrae è l'ultimo elemento inserito.
L'impiego della pila è finalizzato soprattutto ad un immagazzinamento temporaneo di informazioni che possono essere recuperate in ordine inverso rispetto a quello con cui erano stati inseriti.

Lo stack nell'architettura dei microprocessori
Nell'architettura dei più moderni microprocessori, lo stack consiste in una porzione di memoria riservata, la cui dimensione dipende dalla dimensione della memoria centrale, il cui scopo è quello di memorizzare, in maniera temporanea, dei dati per facilitare l'implementazione dei sottoprogrammi. Ciò è possibile poiché esso è una zona di memoria visibile a tutto il programma.
Essendo lo stack una zona di memoria con dimensioni finite, si può andare incontro ad una situazione di stack overflow. Questa situazione si verifica quando viene caricato nello stack un numero di elementi superiore al numero massimo di elementi che lo stack può contenere. Gli elementi in eccedenza sono memorizzati sovrascrivendo le informazioni del programma. L'utilizzo, in maniera adeguata, dell' overflow è alla base dell'intrusione di utenti mal intenzionati nei computer con l'intento di far eseguire proprie porzioni di codice che si vanno a sostituire a quelle del programma in esecuzione.
Nei moderni microprocessori Intel, all'esecuzione di un processo è assegnata una memoria divisa in segmenti. Generalmente ogni processo viene diviso in quattro segmenti:
Il segmento dei dati (Data Segment);
Il segmento del codice (Code Segment);
Il segmento extra (Extra Segment);
Il segmento dello stack (Stack Segment).
Ognuno di questi quattro segmenti corrisponde ad una registro a 16 bit, contente un indirizzo, che però non può essere diviso in due parti da 8 come ad esempio i registri accumulatori.
La segmentazione della memoria utilizzata in un processo è dovuta al fatto che i registri presenti nel microprocessore (i processori Intel sono composti da registri a 16 bit) non riescono a contenere un indirizzo valido per un corretto indirizzamento (un indirizzo valido è composto da 20 bit). Attraverso la segmentazione è possibile proporre un indirizzo completo (indirizzo fisico) grazie all'impiego di due registri a 16 bit: il registro di segmento (DS - CS - EX - SS) e il registro offset ( BX - DI - SI - BP - SP - IP). L'indirizzo fisico è quindi fornito da un indirizzo logico Segmento:Offset che è uguale a: Segmento*16+Offset.
Analisi dei segmenti della memoria
Il Data Segment
Il segmento dei dati è quel segmento che viene utilizzato, in maniera implicita, da parte di un'istruzione, per accedere a i dati contenuti in memoria. L'indirizzo fisico è dato da: DS*16 + Offset_dato.
Il Code Segment
Il segmento del codice è quel segmento che viene utilizzato dal microprocessore, in maniera implicita, in coppia con l'Instruction Pointer, per prelevare la prossima istruzione da eseguire. L'indirizzo fisico è dato da: CS*16 + Offset.
L'Extra Segment
Il segmento extra è un'estensione del registro dei dati poiché esso, a volte, non ha una dimensione sufficiente.
Lo Stack Segment
 Il segmento dello stack, coadiuvato dallo Stack Pointer, viene utilizzato per
gestire lo stack.
Il segmento dello stack, coadiuvato dallo Stack Pointer, viene utilizzato per
gestire lo stack.
La gestione dello stack è completamente affidata alla CPU ed è proprio per questo motivo che questo tipo di memorizzazione dei dati è molto più veloce rispetto alla memorizzazione degli stessi in variabili.
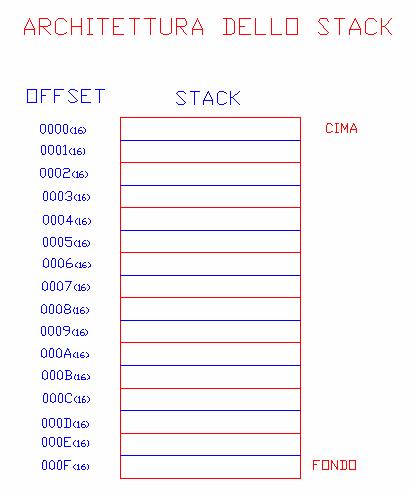
Per poter accedere allo stack, o per caricare o prelevare un valore, bisogna sapere l'indirizzo fisico della locazione alla quale si vuole avere accesso: la prima locazione libera se si vuole caricare un valore; l'ultima locazione occupata se lo si vuole prelevare.
L'indirizzo fisico è fornito dall'indirizzo logico SS:SP dove:
a) in SS è contenuto l'indirizzo della prima locazione di memoria che compone lo stack moltiplicato per 16;
b) in SP è contenuto l'offset della locazione di memoria alla quale si può avere accesso. Generalmente, all'inizio di ogni processo, lo SP contiene l'offset della locazione di memoria, con indirizzo più alto, contenuta nello stack.
Nel caso dell'Intel 8086, ogni dato che viene caricato nello stack occupa due locazioni di memoria. Ciò implica che il dato che deve essere caricato sia un dato a 16 bit i quali verranno poi divisi in due gruppi da 8 e memorizzati nelle due locazioni occupate (i bit più significativi verranno posti nella locazione più bassa, mentre quelli meno significativi in quella più alta).
Venendo occupate due locazioni per ciascun dato, l'offset della locazione alla quale si deve accedere diminuisce di 2 ad ogni operazione di push, mentre aumenta di 2 ad ogni operazione di pop.
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2026