|
|
| |
APPUNTI DI SISTEMI DI ELABORAZIONE 1
PARTE QUATTRO
CAPITOLO SETTE: i processori matematici.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j ................
7.1 Introduzione.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .........
7.2 Il processore 8231A.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................
7.2.1 I segnali di controllo e sincronizzazione.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j ..................
7.2.2 Funzionalità.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .......
7.2.3 Interfacciamento.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j
7.2.4 Esempio con DMA e interrupt.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................
CAPITOLO OTTO: i coprocessori matematici INTEL.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................
8.1 Introduzione.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .........
8.2 Il coprocessore 8087.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j ...............
8.3 Il coprocessore 80287.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .............
8.4 Il coprocessore 80387.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j ...........
CAPITOLO NOVE: sistemi multiprocessore.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .............
9.1 Introduzione.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .......
9.2 Sistemi lascamente connessi.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j ...........
9.2.1 L'8255.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j ...............
9.2.2 L'UPI 8042.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .......
9.3 Sistemi strettamente connessi.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .......
9.4 Sistemi a memoria comune.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................
9.4.1 INTEL 8207.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j ......
9.4.2 Memorie Dual Port.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .............
9.5 Sistemi a bus comune.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .........
9.5.1 Struttura generale per interfaccia a bus comune.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .
9.5.2 L'INTEL 8289.................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j .................... 939g67j ..
I processori matematici possono essere divisi in due grandi categorie.
nella prima categoria ricadono quei processori aritmetici che sono visti dalla CPU come dispositivi di I/O. Quindi sono collegati al bus e dialogano con la CPU tramite un serie di comandi specifici. In questi sistemi, la CPU non possiede nel proprio set le istruzioni aritmetiche tipicamente floating point, per cui queste operazioni sono delegate al processore matematico che viene definito APU (Arithmetic Processor Unit).
nella seconda categoria ricadono i coprocessori matematici, detti NPU, i quali comunicano con la CPU tramite una connessione dedicata e separata dal bus; in questi sistemi, la CPU possiede nel proprio set le istruzioni aritmetiche floating point.
Analizziamo in dettaglio un processore aritmetico che ricade nella prima categoria: l'8231A. Le fotocopie disponibili riportano in realtà il processore AM9511, ma i due chip sono praticamente identici.
L'8231A è in grado di gestire:
sia la singola che la doppia precisione, cioè operandi da 16 e 32 bit
il floating point su 32 bit
alcune funzioni trascendenti come quelle trigonometriche, logaritmiche, ecc...
L'interfaccia
presenta i segnali tipici di un dispositivo di I/O. Sono infatti presenti
il Chip Select, i segnali di Read e Write, il segnale Control/Data, il bus
a 8 bit e coppie di segnali per l'interrupt e il DMA.
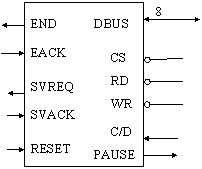
Figura 1: i segnali dell'8231A
Il Chip Select è quel segnale attivo basso che serve a selezionare il dispositivo quando la CPU vuole comunicare con esso. I segnali Read e Write informano l'APU del tipo di operazione che la CPU intende fare. Il segnale Command/Data indica il tipo di trasferimento che avviene sul Data Bus: se è basso, indica che le operazioni di read e write accedono ai dati, se invece è alto, l'operazione di read ritorna lo stato del dispositivo, l'operazione di write invia un comando matematico al dispositivo.
Il segnale Pause attivo basso indica che l'APU è occupato: nessun comando gli può essere inviato, né nessun dato valido è presente sul Data Bus.
Il segnale End attivo basso indica che il dispositivo ha concluso l'operazione aritmetica in corso, ed è resettato dal segnale End Acknowledge, da un segnale di Read/Write o dal Reset. Vedremo più avanti come questi due segnali possano essere utilizzati nell'interfacciamento tramite DMA.
Il processore attiva il segnale SVREQ quando ha completato l'esecuzione di un comando aritmetico per il quale il bit service request è stato settato (vedi più avanti). Viene poi resettato quando arriva il segnale SVACK, da un nuovo comando che non ha quel bit settato, oppure dal Reset. Questo segnale può essere utile nell'interfacciamento mediante interrupt (anche questo lo vediamo più avanti).
Tutti gli APU sono dispositivi stack oriented, cioè tutte le operazioni aritmetiche vengono svolte prelevando i dati dalla cima di uno stack, e riponendo il risultato in cima allo stack. Il tipo di operazione da svolgere è indicata tramite un comando che ha un preciso formato:
![]()
Figura 2: formato del comando
OPCode (5 bit): contiene un codice corrispondente all'operazione aritmetica da svolgere
Data Format (2 bit): contiene un'indicazione sul formato dei dati coinvolti (fixed point, floating point, 16 o 32 bit)
Service Request (1 bit): indica se, al termine dell'istruzione richiesta nell'opcode, il dispositivo deve attivare il segnale SVREQ.
Come abbiamo accennato, l'APU contiene uno stack composto 8 posizioni da 16 bit ciascuna, che può essere configurato per operandi a 32 bit, e quindi diventa di 4 posizioni da 32 bit ciascuna.
Stack da 4 posiz. TOS=Top of Stack NOS=Next of Stack Stack da 8 posiz.
![]()
![]()

Figura 3: configurazioni dello stack
Le celle che compongono lo stack non sono indirizzabili direttamente: tutte le operazioni vengono svolte basandosi sulle prime due celle dello stack, TOS e NOS (come nelle calcolatrici RPN).
Esiste un altro registro, la Status Word, che contiene alcuni flags relativi all'operazione appena completata.
![]()
Figura 4: Status Word
BUSY: indica che l'APU sta svolgendo un calcolo e i dati non sono accessibili
NEG: risultato negativo
ZERO: risultato pari a zero
ERR (2 bit): indica il tipo di errore riscontrato
UF,OF: Underflow, Overflow
C/B: carry o borrow
Nella slide 326 (sez. 7, terzo foglio, retro)sono elencate le varie operazioni matematiche che il dispositivo è in grado di svolgere, ciascuna con il corrispondente Opcode. Nella colonna più a destra sono anche riportati i colpi di clock necessari per completare ciascuna operazione; si nota come alcune operazioni siano particolarmente gravose (fino a 10.000 colpi di clock), specialmente se si tiene conto che questi dispositivi hanno una frequenza di 5-10 Mhz.
L'8231A, come la maggior parte delle APU, offre tre tipi di interfacciamento con un microprocessore.
il microprocessore aspetta finché l'APU non ha completato l'operazione richiesta
il microprocessore interroga periodicamente (polling) l'APU
l'API attiva un interrupt quando ha completato l'operazione
La prima soluzione è la più semplice ma anche la meno efficiente. Probabilmente diventa impraticabile nei sistemi che presentano una memoria dinamica da rinfrescare con una frequenza ben precisa; bloccare la CPU in attesa del completamento dell'operazione matematica comporterebbe la perdita dei dati nella RAM dinamica.
Le altre due sono più efficienti, ma complicano leggermente le cose. Il polling comporta un loop software che legga periodicamente la Status Word dell'APU per vedere se il bit BUSY è settato oppure no. La gestione con interrupt prevede una complicazione circuitale che vediamo nel prossimo paragrafo.
Vediamo un esempio di interfacciamento dell'AM9511 con un microprocessore, utilizzando il DMA per trasferire i comandi aritmetici dalla memoria all'APU, e l'interrupt per segnalare la conclusione di un calcolo.
Immaginiamo di dover calcolare la funzione:
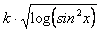
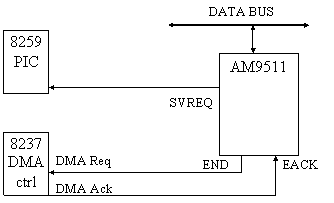
Figura 5: interfacciamento APU
Per calcolare questa funzione, occorre inviare all'AM9511 una serie di comandi aritmetici, oltre naturalmente agli operandi, che nel nostro esempio sono k e x.
Sequenza delle operazioni da svolgere:
|
OPERAZIONE |
SIGNIFICATO |
STATO dei SEGNALI |
|
Caricamento di x nello stack |
|
Write attivo, C/D inattivo |
|
FLTS |
conversione in floating point |
DMA, Write attivo, C/D attivo |
|
SIN |
calcola sin (x) |
DMA, Write attivo, C/D attivo |
|
PTOF |
copia TOS su NOS |
DMA, Write attivo, C/D attivo |
|
FMUL |
calcola TOS NOS |
DMA, Write attivo, C/D attivo |
|
LN |
calcola log(TOS) |
DMA, Write attivo, C/D attivo |
|
SQRT |
calcola sqrt(TOS) |
DMA, Write attivo, C/D attivo |
|
PTOF |
copia TOS su NOS |
DMA, Write attivo, C/D attivo |
|
Caricamento di k in TOS |
|
Write attivo, C/D inattivo |
|
FMUL |
calcola TOS NOS |
bit SR=1, Write attivo, C/D attivo |
Il DMA viene qui utilizzato per trasferire dalla memoria all'APU la maggior parte dei comandi aritmetici necessari per eseguire il calcolo.
Nel DMA
controller sono programmati l'indirizzo di I/O dell'AM9511 e l'indirizzo
della prima cella di memoria da cui iniziare il trasferimento dei comandi
aritmetici.
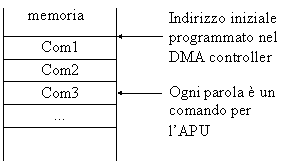
Figura 6: organizzazione comandi in memoria
Il DMA controller viene gestito tramite i segnali END e EACK dell'AM9511. Al termine dell'esecuzione di un comando aritmetico da parte dell'APU, quest'ultimo attiva il segnale END; questo segnale è collegato al pin di DMA Request dell'8237, il quale avvia il trasferimento del prossimo comando dalla memoria al processore aritmetico; subito dopo attiva il segnale EACK. Questa sequenza avviene per tutti i comandi aritmetici elencati nella tabella soprastante che portano la dicitura "DMA" sulla colonna di destra. Nell'ultimo comando il bit Service Request è settato, in modo che, alla conclusione della moltiplicazione, il 9511 attivi il segnale SVREQ; questo segnale scatena un interrupt che segnala alla CPU il termine dell'intero calcolo.
Analizzeremo la gestione del coprocessore matematico 8087, 80287 e 80387, esaminando come tale dispositivi siano cambiati nel corso del tempo.
La gestione del coprocessore matematico è stata completamente cambiata passando dall'8086 al 286 a causa del modo protetto.
L'8087 è un coprocessore nel corretto senso del termine, infatti è collegato, come la CPU, all'Address Bus e al Data Bus, e possiede una coda di istruzioni (coda di prefetch) che viene caricata in parallelo a quella dell'8086.
addr
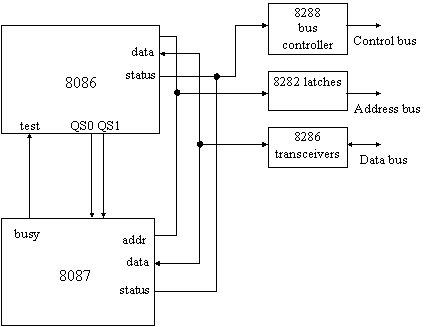
Figura 7: Interfaccia tra 8086 e 8087
La sincronizzazione tra processore e coprocessore avviene tramite due segnali, QS0 e QS1. Ad ogni colpo di clock l'8086 esamina la coda e setta questi due segnali seconda la seguente tabella:
|
QS0 |
QS1 |
OPERAZIONE |
|
|
|
nessuna istruzione è prelevata dalla coda |
|
|
|
il primo byte dell'istruzione corrente è prelevato dalla coda |
|
|
|
la coda è azzerata |
|
|
|
un byte (diverso dal primo) è prelevato dalla coda |
Grazie a questi due segnali, le due code cambiano stato in parallelo e la situazione dei due processori rimane coerente.
Quando giunge un'istruzione aritmetica che compete al coprocessore (quindi non un'operazione aritmetica semplice), l'8086 salta questa istruzione mentre l'8087 la riconosce e disattiva il segnale busy (cioè lo porta a 1), dopodiché inizia ad eseguire l'istruzione; nel frattempo l'8086 preleva ed esegue le istruzioni successive, segnalando questi atti al coprocessore mediante i segnali QS0 e QS1, fino a che non incontra un'istruzione di WAIT; questa istruzione blocca l'8086 fino a che il pin test non riceve un segnale attivo (cioè uno 0). Quando l'8087 ha concluso il calcolo, attiva il segnale di busy (lo porta a 0), comunicando così all'8086 che si può procedere con le successive istruzioni.
Le istruzioni per il coprocessore si riconoscono perché hanno come prefisso un codice ESCAPE:
Operand
![]()
![]()
Per esempio l'istruzione:
FST PIPPO
che converte il top dello stack in uno short real e lo memorizza nella variabile PIPPO, è codificata in questo modo:
![]()
![]()
![]()
PIPPO FST
![]()
![]()
Un problema molto serio che si presenta con questa configurazione è quello degli indirizzi degli operandi. Consideriamo l'esempio precedente: l'istruzione aritmetica deve porre il risultato della conversione nella variabile PIPPO (in memoria). L'8086 è in grado di costruire l'indirizzo fisico di questa variabile perché possiede nei suoi registri l'indirizzo di segmento, per esempio DS, e preleva dall'istruzione l'offset all'interno del segmento. Invece l'8087 non possiede registri di segmento, quindi dall'istruzione matematica può ricavare solo l'offset.
Per risolvere questo spinoso problema, i progettisti hanno adottato una soluzione piuttosto intricata.
Con riferimento all'esempio precedente, la CPU, dopo aver riconosciuto la presenza dell'istruzione aritmetica FST, si accorge che questa prevede una scrittura in memoria (anche la NPU se ne accorge e si prepara). Costruisce quindi l'indirizzo di PIPPO e avvia un ciclo di scrittura in memoria. Il coprocessore matematico, a quel punto, si copia in un registro a 20 bit interno l'indirizzo che passa sull'Address Bus, in modo che, quando dovrà andare a scrivere in memoria il risultato del calcolo, avrà già l'indirizzo fisico. La CPU, concluso questo ciclo, passa alle successive istruzioni. Al termine della conversione, la scrittura in memoria del risultato avviene con la generazione, da parte dell'8287, di un certo numero di cicli di DMA, rubando cicli alla CPU. L'8287 si comporta, tramite i segnali Bus Request e Bus Grant, come una DMA controller.
Analoghe operazioni vengono svolte quando l'8087 deve leggere gli operandi di un'istruzione matematica: è sempre la CPU ad avviare il primo ciclo, poi ci pensa l'8087.
Tra l'altro questo spiega perché l'8086 presenti 2 piedini di DMA invece di uno solo, come tutti i processori successivi.
E spiega anche perché questa architettura sia stata abbandonata con i processori successivi, dove a complicare il tutto interviene la modalità protetta con i descrittori e gli indirizzi logici.
L'80287 è stato progettato secondo una filosofia molto diversa rispetto a quella adottata per l'8087. Infatti, pur mantenendo lo stesso set di istruzioni, l'80287 non è più gestito come un coprocessore ma piuttosto come un dispositivo di I/O. Questo significa che l'80287:
possiede un ben preciso indirizzo di I/O
comunica con la CPU tramite dei cicli di scrittura/lettura con un certo protocollo riservato
non è più collegato all'Address Bus, ma solo al Data Bus
non possiede più una coda di prefetch
non deve più sincronizzarsi con lo stato della CPU, e infatti sono scomparsi i segnali QS0-QS1
i segnali CMD0 e CMD1 specificano la semantica dei dati inviati dalla CPU all'80287
i segnale NPS1 e NPS2 fungono da chip select
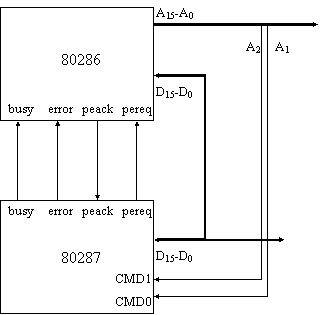
Figura 8: interfaccia tra 80286 e 80287
L'80287 presenta due segnali, PEREQ e PEACK, utili per gestire un protocollo di comunicazione con la CPU, tramite il quale il processore matematico informa l'80286 che è in attesa di dati (operandi), sia istruzioni che operandi, e la CPU notifica all'80287 la ricezione di tale informazione.
Quando la CPU incontra un'istruzione matematica per il coprocessore, la interpreta ed esegue un ciclo di I/O verso l'80287, inviandogli dei codici particolari che indicano quali operazioni dovrà svolgere per completare il calcolo. L'80287 attiva il segnale busy e interpreta i codici che gli sono arrivati; nel caso in cui tale operazione implichi la lettura o scrittura in memoria di operandi, tramite il segnale PEREQ l'80287 comunica alla CPU la necessità di avere gli operandi per eseguire il calcolo oppure la volontà di scrivere il risultato in memoria. Appena possibile, la CPU preleva gli operandi dalla memoria e li invia all'80287,o viceversa li preleva dall'80287 e li scrive in memoria.
Il 387 assomiglia molto al 287, ma occorre citare alcune importanti differenze.
è scomparso il segnale CMD1; il segnale CMD0 è sufficiente per distinguere se interpretare le informazioni arrivate come dati o come comandi; tale segnale coincide con il filo A2 dell'Address Bus
è scomparso il segnale PEACK di acknowledge verso il coprocessore matematico
il bus dati è diventato a 32 bit
l'80387 può ricevere due segnali di clock; il primo è quello della CPU, utile per sincronizzarsi con i cicli di bus, il secondo è un clock che può essere più veloce (1.4 volte) e che fornisce la frequenza per le operazioni matematiche svolte internamente
Il 387 presenta 8 registri da 80 bit ciascuno che formano lo stack, un registro di controllo e un registro di stato, entrambi da 16 bit.
Possiamo dividere i sistemi multiprocessore in due grandi famiglie:
sistemi lascamente connessi
sistemi strettamente connessi
Immaginiamo un sistema composto da un certo numero di "moduli". Questi moduli sono generalmente composti da una CPU, da un po' di RAM ed eventualmente da dispositivi di I/O.
Nei sistemi lascamente connessi i moduli non sono collegati tramite un unico bus, e spesso configurano una gerarchia di tipo master-slave, in cui lo scambio di dati è relativamente scarso. Nei sistemi strettamente connessi, invece, i moduli condividono uno stesso bus di sistema, ed esistono varie filosofie di progetto per la disposizione e la comunicazione di questi moduli.
I sistemi lascamente connessi vengono spesso realizzati collegando i moduli con connessioni di tipo parallelo piuttosto che seriale.
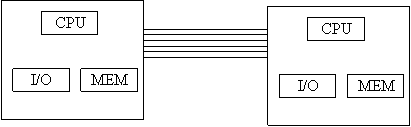
Figura 9: sistema lascamente connesso
Come abbiamo già accennato, la maggior parte di questi sistemi presenta una configurazione master-slave, in cui un modulo assume il ruolo di controllore del sistema. Noi analizzeremo un particolare dispositivo, l'8255, che è in grado di gestire un protocollo master-slave su connessione parallela.
L'8255 è un gestore di porta parallela che presenta 3 porte da 8 bit, convenzionalmente chiamate A,B e C; la porta A è bidirezionale mentre la porta C può essere controllata a livello del singolo bit, e quindi può essere utilizzata per inviare e ricevere segnali di controllo. Questo dispositivo ha diverse modalità di funzionamento, ma a noi interessa il modo 2, perché solo in questa modalità è in grado di gestire la comunicazione in un sistema master-slave.
In fig.10 sono
mostrati i segnali coinvolti nella comunicazione tra master e slave quando
l'8255 lavora in modo 2. Come vedremo
subito dopo, i segnali OBF (output Buffer Full), WR e ACK gestiscono il
trasferimento dati verso dal master allo slave, mentre i segnali IBF (Input
Buffer Full), RD e STB gestiscono il trasferimento dallo slave al master. La porta A,
composta dai segnali PA0-PA7 è bidirezionale, e ha il
compito di trasportare i dati tra master e slave.
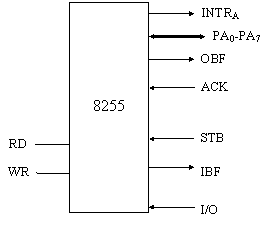
Figura 10: segnali dell'8255 in modo 2
Il sistema che programma l'8255 assume il ruolo di master. In fig. 11 abbiamo una classica configurazione master-slave in cui possiamo analizzare la funzione dei vari segnali citati in precedenza. Il master si trova a sinistra della linea tratteggiata, lo slave a destra.
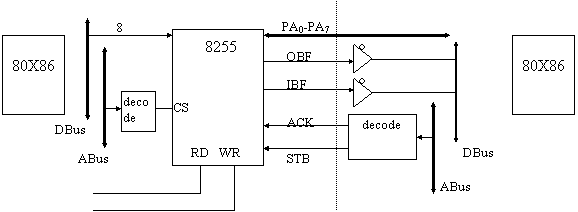
Figura 11: connessione tra due processori tramite 8255
La comunicazione è gestita secondo il seguente protocollo.
Nel momento in cui il master esegue un'istruzione di OUT sull'8255, cioè scrive un dato sull'8255, questo attiva il segnale OBF (attivo basso) e mette a disposizione il dato sulla porta A. Lo slave comunica di aver letto il dato attivando il segnale ACK; tale segnale disattiva automaticamente l'OBF (vedi fig. 12).
Quando lo slave vuole inviare un dato, attiva innanzitutto il segnale STB e pone i dati sulla porta A; tale segnale attiva automaticamente il segnale IBF, informando il master che la porta A deve cambiare direzione e che lo slave ha preparato un dato. La lettura dei dati da parte del master (segnale RD) disattiva automaticamente IBF (vedi fig. 13).

Figura 12: trasferimento da master a slave
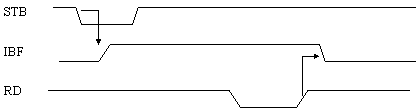
Figura 13: trasferimento da slave a master
La gestione dei segnali appena visti può essere svolta in polling o in interrupt. Nel primo caso, sia nel master che nello slave, ci saranno routine software che controllano costantemente il valore dei segnali OBF e IBF per vedere se è disponibile un dato da leggere; nel secondo caso, questi due segnali possono essere utilizzati per scatenare un interrupt.
Questo è un protocollo di tipo half-duplex: si ha una sola porta bidirezionale e i dati vanno in una direzione oppure nell'altra. Inoltre non comprende una gestione dei conflitti: l'arbitraggio deve essere fatto ad un livello più alto.
In molti casi, una logica come quella dell'8255 è inglobata in controller progettati per operare in sistemi multiprocessore. E' molto comune la situazione in cui una singola CPU deve gestire tutta una serie di dispostivi di I/O, ai quali è collegata tramite un bus. Questi dispositivi sono "intelligenti", nel senso che inglobano una piccola CPU con un po' di memoria, e la logica necessaria per svolgere il ruolo di slave nei confronti del master del sistema.
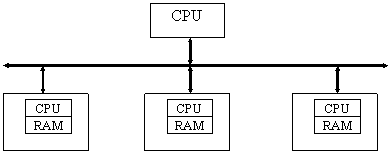
Figura 14: tipica configurazione master slave
L'UPI 8042 (Universal Peripheral Interface) è uno dei più diffusi chip dell'INTEL; si tratta di un microcontroller che presenta una CPU da 8 bit e 12 Mhz, un po' di RAM (256k), di un po' di ROM (2k), una EPROM e alcune porte di I/O. E' stato progettato per svolgere il ruolo di slave, e infatti contiene tutta la logica necessaria per gestire l'interfaccia verso un master; in particolare, replica buona parte della logica e dei segnali già visti nell'8255 (vedi fig.15).
Il master e l'UPI comunicano tramite il registro Data Bus Buffer (DBB) presente all'interno dell'UPI. L'8042 riceve dal master dati e comandi e gli invia dati e stato. Per scrivere/leggere dallo slave, il master utilizza i segnali WR,RD, CS e A0. L'ultimo segnale citato indica all'UPI se il master sta inviando un comando o un dato.
E' presente anche lo Status register, che contiene i seguenti bit:
OBF: è settato
automaticamente quando l'UPI scrive il dato in uscita nel registro DBB; è
azzerato quando il master legge il dato. IBF: è settato quando il
master scrive un dato nel registro DBB; è azzerato quando l'UPI legge il
dato dal registro DBB. F0: è un bit che
può essere settato/resettato dall'UPI via software e può essere utile per
segnalare al master che l'UPI è occupato a scrivere/leggere nel registro
DBB. F1: questo flag
assume il valore del bit A0 quando il master scrive un dato nel
registro DBB. Indica se il dato scritto è da interpretare come un comando
(F1=1) o un dato (F1=0).
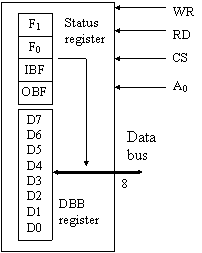
Figura 15: struttura dell'UPI 8042
Il registro DBB è una risorsa condivisa dal master e dallo slave. Nonostante non esista un meccanismo hardware per bloccare in mutua esclusione il registro, è possibile prevedere un protocollo software che si basi sul flag F0.
Possiamo suddividere i sistemi strettamente connessi in due grandi categorie:
sistemi a memoria comune
sistemi a bus comune
Nel primo caso la risorsa condivisa è la memoria, e l'arbitraggio per la gestione dei conflitti è svolta dalla memoria stessa o da una logica apposta; nel secondo caso invece la risorsa condivisa è il bus.
Tra i sistemi a memoria comune possiamo fare un ulteriore distinzione:
sistemi che utilizzano memorie dual port
sistemi che utilizzano memoria RAM normale
Nel primo caso l'arbitraggio è gestito dalla memoria stessa, che integra la logica opportuna; nel secondo caso occorre progettare l'arbitro in logica sparsa oppure utilizzare un chip apposito.
Vediamo in questo paragrafo uno esempio di sistema a memoria comune con arbitro progettato ad hoc.
Nell'esempio di fig. 16 abbiamo due sistemi, ciascuno con la propria CPU Z80, una memoria dinamica privata da 4 Kb e delle porte di I/O, che comunicano tramite una memoria statica condivisa da 1 Kb.
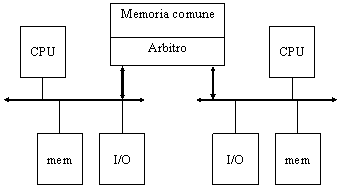
Figura 16: sistema a memoria comune
La strategia di arbitraggio si basa sui seguenti punti:
le due CPU sono gerarchicamente pari
se c'è una sola richiesta, la memoria è assegnata alla CPU richiedente
se ci sono due richieste contemporanee, la memoria è riassegnata alla CPU servita per ultima, mentre un segnale di WAIT è inviato all'altra
nel caso in cui una CPU stia effettuando un'operazione sulla memoria comune e l'altro chieda l'accesso, è generato un segnale di WAIT a quest'ultima
l'assegnazione della memoria comune è relativa ad una sola operazione di lettura o scrittura; in questo modo si evita l'attesa indefinita e una CPU non rimane in WAIT troppo a lungo (deve occuparsi del refresh della propria memoria privata)
non si considera la realizzazione hardware, nel banco di memoria comune, dell'istruzione TEST&SET, che lo Z80 non ha, e che è necessaria per l'implementazione di sistemi operativi multiprocessore
Ra,Rb: segnali di
richiesta di accesso da parte delle CPU WAITa,WAITb: segnale
di attesa in risposta alle CPU Ba,Bb: segnale di
libero accesso in risposta alle CPU
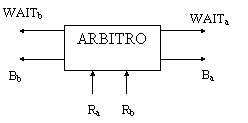
Figura 17: segnali dell'arbitro
Vista la politica di arbitraggio adottata (in particolare il punto 3), l'arbitro non può essere realizzato con un circuito combinatorio, bensì deve essere implementato mediante un circuito sequenziale. Inoltre, per diminuire la probabilità di avere richieste contemporanee, occorre che la risposta dell'arbitro sia molto veloce; questo ci porta a scegliere un circuito sequenziale asincrono, cioè non legato a nessun clock, ma pronto in (quasi) qualunque istante a soddisfare una richiesta.
E' sufficiente che l'arbitro abbia due soli stati interni ai quali si può associare il seguente significato (vedi fig.18):
stato 0: ultimo accesso ottenuto dal microprocessore a
stato 1: ultimo accesso ottenuto dal microprocessore b
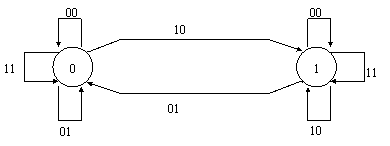
|
STATO |
||
|
Ra Rb |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Figura 18: automa a stati finiti rappresentante l'arbitro
In fig. 19 è raffigurato lo schema di principio del collegamento tra le due CPU e la memoria comune. Siccome le due CPU sono identiche, tutti i segnali sono speculari e tramite una serie di tristate sono collegati alla memoria. L'apertura e chiusura dei tristate è comandata dai segnali Ba e Bb.
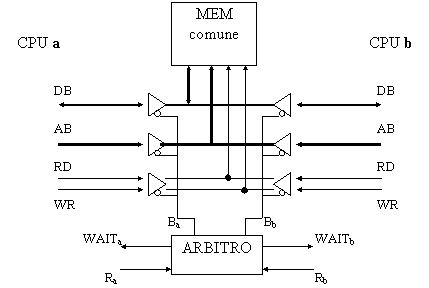
Figura 19: collegamenti tra la memoria e l'arbitro
Nel caso in cui la memoria comune sia dinamica anziché statica, il problema si complica perché occorre gestire anche il rinfresco periodico, il quale ha naturalmente maggiore priorità delle richieste avanzate dalle CPU.
In questo caso però, conviene utilizzare arbitri già realizzati su chip che svolgono anche questa funzione. Un esempio è l'8207 della INTEL, il quale è un controllor di RAM dinamica, in grado però di gestire le richieste di accesso da parte di due CPU concorrenti. In altre parole è come un 8202 (8203) a cui è stata aggiunta la logica necessaria per arbitrare accessi multipli.
Questo controller supporta 4 modi di rinfresco e genera i segnali per pilotare un 8206, cioè un'unità di correzione degli errori.
Abbiamo visto nei paragrafi precedenti due soluzioni per la realizazzione di sistemi a memoria comune:
la sintesi di un arbitro ad hoc per gestire gli accessi a una RAM normale
l'utilizzo di un controller di RAM dinamica con integrata la logica di arbitraggio
Vediamo in questo paragrafo una terza soluzione: utilizzare una memoria Dual port.
Una memoria Dual port è una memoria statica che integra al suo interno la logica necessaria per arbitrare richieste multiple. Tale logica permette di avere letture/scritture contemporanee da parte delle due CPU, ma solo se tali operazioni sono relative a celle differenti. In caso di conflitto, causato da una lettura/scrittura sulle stesse celle, la Dual port genera un segnale di busy verso uno dei due processori.
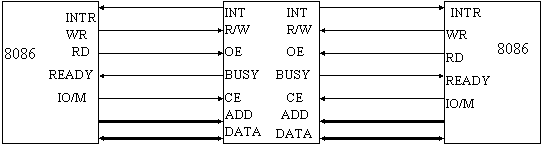
Figura 20: interfacciamento tra 2 CPU e la dual port
Un'altra caratteristica molto utile offerta dalle Dual port, consiste nella possibilità di segnalare ad un processore il fatto che l'altro processore ha eseguito una scrittura o lettura in memoria. Nel momento in cui il processore a compie un'operazione sulla Dual port, questa se ne accorge e genera un segnale di interrupt verso il processore b. Questa caratterisitca facilita la realizzazione di un protocollo di comunicazione tra le due CPU del tipo produttore-consumatore. In effetti le Dual port vengono utilizzare soprattutto per la comunicazione tra processori e per questo motivo non sono molto grandi: solitamente hanno dimensione non superiore a 1 Mbyte.
Se i processori che devono essere messi in comunicazione sono più di due, la soluzione con Dual port è impraticabile; occorre pensare ad un sistema a bus comune.
Esistono tre diverse filosofie di allocazione del bus:
Daisy chain
Polling
Independent request
In tutti e tre i metodi sono coinvolti i seguenti elementi:
un controller del bus comune che svolge funzioni di arbitraggio
una gestione degli indirizzi verso il bus comune
un segnale che indichi lo stato del bus (occupato o disponibile)
un segnale di richiesta del bus (bus request)
un segnale di risposta (bus grant)
Daisy chain
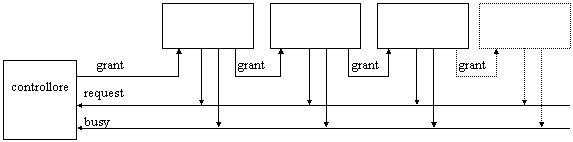
Figura 21: daisy chain
Caratteristiche:
ha una struttura semplice ed economica
il segnale di grant viene passato da un sistema all'altro, fino a quello che ha fatto richiesta, che a quel punto attiva il segnale di busy; questo comporta mediamente un alto tempo di risposta
la priorità di richiesta è fissata al momento del cablaggio
non ha bisogno di un arbitro centralizzato
Polling

Figura 22: polling
Caratteristiche:
ogni sistema è identificato da un indirizzo
il controllore genera in successione i vari indirizzi dei sistemi collegati; quando il sistema richiedente riconosce il proprio indirizzo, attiva il segnale di busy
nel caso peggiore il controllore deve generare tutti gli indirizzi, quindi questa architettura presenta tempi di risposta mediamente alti
il numero di segnali da portare è elevato
Independent request
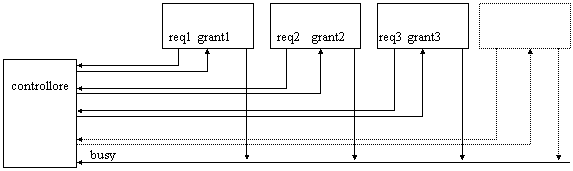
Figura 23: independent request
Caratteristiche:
ogni sistema ha una coppia di segnali request-grant separata
occorre un arbitro per gestire le richieste multiple
la priorità è programmabile
i tempi di risposta sono bassi e indipendenti dalla priorità
In fig.24 è raffigurata la struttura generica di uno dei sistemi che si affacciano sul bus comune.
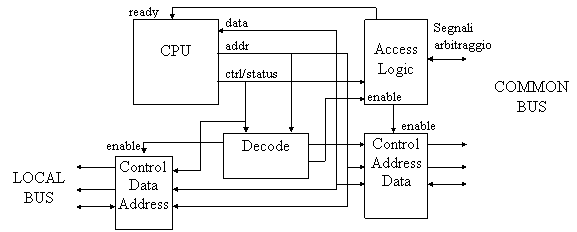
Figura 24: interfaccia tra CPU e bus comune
La logica di accesso (Access Logic) ha il compito di gestire l'arbitraggio del bus comune; per fare questo deve ricevere i segnali di stato dalla CPU, in modo da conoscere quale operazione vuole intraprendere il processore, e deve segnalare alla CPU, tramite il segnale di ready, quando può procedere oppure deve bloccarsi. Quando la CPU ottiene l'accesso al bus comune, la logica di accesso abilita il controllore del bus comune.
Il decodificatore deve analizzare l'Address Bus per capire se l'indirizzo si riferisce al bus locale o al bus comune; a seconda del caso, abilita la logica di accesso al bus locale (a sinistra in fig. 24), oppure la logica di accesso al bus comune (a destra).
Ogni sistema che si affaccia al bus comune deve presentare un dispositivo, l'Access Logic, che gli permette di richiedere e ottenere il bus quando necessario.
BCLK (bus clock) BPRN (bus
priority in) BREQ (bus
request) BPRO (bus
priority out) BUSY
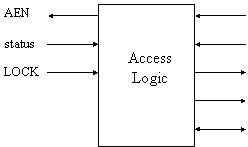
Figura 25: logica di accesso al bus MULTIBUS
In fig. 25 sono riportati in maggior dettaglio i segnali gestiti dalla logica di accesso al bus comune. In particolare, vediamo i segnali necessari per gestire il bus comune MULTIBUS della INTEL.
Siccome il MULTIBUS può essere configurato per funzionare in modalità Daisy chain e Independent request, troviamo tre segnali: BPRN, BREQ e BPRO; BPRN e BPRO possono essere utilizzati in Daisy chain come segnale di ingresso e di uscita della catena del grant; il segnale BREQ può essere utilizzato per inviare una richiesta all'arbitro. Quando il sistema ha ottenuto l'accesso al bus comune, attiva il segnale di BUSY per comunicare all'arbitro di aver occupato la risorsa.
Nota che il segnale di clock che temporizza il dispositivo è quello di arbitraggio (BCLK), non quello del processore.
L'8086/88 non possiede i segnali per richiedere il controllo del bus ad un arbitro (bus request) ed accettarne la risposta (bus grant). E' necessaria la presenza di un dispositivo che svolga funzioni di bus master, cioè che sia in grado di gestire quei segnali di arbitraggio visti nei paragrafi precedenti. L'8289 della INTEL è un bus arbiter progettato appositamente a questo scopo: operando in collaborazione con il controller del bus, l'8289 controlla l'accesso al bus comune degli altri sistemi dotati di 8289 (o analoghi) che si contendono la risorsa; può gestire sia uno schema Daisy chain che uno schema Independent request.
In fig.26 sono mostrati i collegamenti tra l'8289 e l'8086, assumendo che il sistema non possieda un bus locale (altrimenti, vedi fig. 24). Il bus arbiter riceve lo stato dell'8086 (segnali S0-S2) e determina quando richiedere e quando rilasciare il bus. Anche l'8288 riceve gli stessi segnali, perché deve sapere quando e che tipo di ciclo iniziare. All'avvio di un ciclo, se il bus arbiter ha il controllo del bus comune, lo segnala al bus controller (8288) e ai latch (8283) attivando il pin AEN. L'8288, a sua volta, abilita i transceiver (8287) che regolano il passaggio dei dati. Da questo momento in avanti, il ciclo procede nel solito modo sul bus comune.
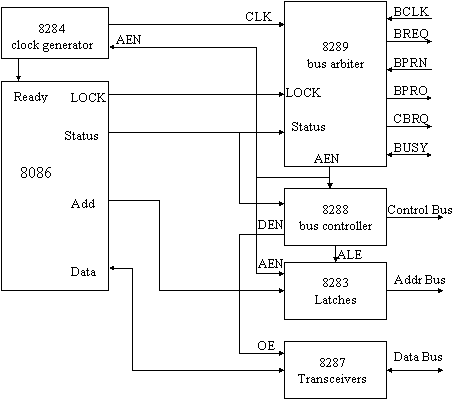
Figura 26: interfacciamento 8086 - 8289
Se invece il bus arbiter non ha il controllo del bus comune, disattiva il segnale AEN, forzando l'8288 e l'8283 a staccarsi dal bus comune; siccome il segnale DEN è controllato da AEN, anche il data transceiver viene disabilitato. Infine, il segnale AEN si propaga fino al clock generator, il quale non attiva il segnale di READY, forzando la CPU ad entrare in WAIT. Una volta che il bus comune è stato ottenuto, il bus arbiter riattiva il segnale AEN, permettendo la conclusione del ciclo.
Se l'8086 attiva il segnale di LOCK, il bus arbiter non rilascia il bus comune alla fine del ciclo; questo può essere utile per eseguire più cicli consecutivi prima di rilasciare il bus.
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2025