|
|
| |
STRATEGIE DI RICERCA
Nell'analisi di problemi in cui, durante la ricerca di soluzioni ottime, non sia possibile valutare l'adeguatezza dei casi precedentemente esaminati, occorre far uso di procedura di ricerca cieca. Come suggerisce la definizione, una procedura di ricerca cieca non tiene conto delle caratteristiche delle soluzioni man mano esaminate nel corso dell'analisi dello spazio problemico, ma convoglia i suoi sforzi in un'analisi iterativamente o ricorsivamente esaustiva nel campo di tutto lo spazio problemico stesso. Occorre specificare che le procedure successivamente esaminate si intendono operanti su di una base di informazioni organizzate in alberi, anche per chiarire meglio il significato di alcune azioni intraprese dagli algoritmi stessi. Qualora lo spazio problemico non sia naturalmente esprimibile o modellabile attraverso l'uso di alberi, grafi o multigrafi, si intende possibile la realizzazione di procedure aggiuntive atte a plasmare il comportamento degli algoritmi per risolvere ugualmente il problema in questione.
Tra le procedure di ricerca cieca disponibili in letteratura, sono degne di nota come rappresentanti di alcune caratteristiche peculiari di questa classe di algoritmi, le seguenti procedure:
L'idea di base dei tre algoritmi è la stessa, con sostanziali differenze nella modalità di conduzione della ricerca. La ricerca in profondità esamina percorsi via via sempre più profondi nello spazio problemico per poi far uso di backtracking e memorizzazione di path per risalire da un nodo ritenuto cieco. Ciò comporta una buona velocità di esecuzione nel caso di problemi piccoli o con molti casi da esaminare raggruppati però con pochi e sostanziali vincoli. Tra gli svantaggi la propensione al loop nel caso in cui il grafo dei problemi non sia aciclico, con conseguente inefficienza e temporale e funzionale. Di intenzioni opposte è la ricerca in ampiezza: come si evince dal nome, infatti, esamina i casi per livello, completando con successo e sempre l'analisi di tutto lo spazio delle soluzioni (se richiesto) per ritrovare il caso ottimo. Non necessita di backtracking e può più agevolmente essere codificata come procedura iterativa anzichè ricorsiva (sebbene in alcuni testi si faccia menzione di un aumento a volte inutile dell'occupazione in memoria dell'algoritmo dovuta alla metodologia di ricerca stessa). Per contro, la velocità soffre della caratteristica dell'algoritmo di esaminare casi tra loro "distanti" nel campo delle soluzioni e quindi non confrontabili per condizionare l'analisi dei casi successivi (questo ultimo dato sancisce una vocazione più spiccatamente brute-force della DFS rispetto alla BFS, che, a volte, viene usata come base anche per procedure di natura euristica). Infine, la ricerca per allargamento iterativo fonde alcuni dei principi ispiratori delle tecniche precedenti per garantire la sicurezza di esecuzione della BFS, usata per generare un sottospazio di casi da esaminare in ampiezza, con un aumento di velocità dovuto all'uso della DFS limitata come algoritmo usato nei passi intermedi.
Ricapitolando, per presentare la pseudocodifica dei suddetti algoritmi assumiamo che:
Di seguito sono presentate due implementazioni in linguaggio C ed operanti su grafi dei due algoritmi DFS e BFS. Sia BFS che DFS e Iterative broadening sono facilmente scalabili su sistemi paralleli e multiprocessore. Nel caso di BFS,infatti la trasposizione su sistemi paralleli diviene immediata associando ad ogni processore un ramo partente dalla radice, eventualmente sfruttando le CPU a cui sono stati associati sottoalberi più piccoli rischedulando periodicamente le assegnazioni. Per la DFS e l'Iterative broadening il discorso è leggermente più complesso, vista l'impossibilità di assegnazione diretta di una fetta di problema ad ogni unità computazionale. Sfruttando, però, opportunamente le interconnessioni presenti nel network parallelo, è possibile associare al pool di processori interi livelli di profondità, eventualmente partizionati, incrementando se necessario il numero di nodi associati all'aumentare del livello di esame dell'albero.
Ricerca in profondità - Implementazione in C
(l'implementazione manca della funzione di test di ottimalità dei nodi in esame)
| dfs.c Letto in input un grafo orientato, rappresentarlo mediante liste di adiacenza. Esegue la visita in profondita' del grafo mediante l'algoritmo DFS (Depth First Search). Pseudo-codifica dell'algoritmo: DFS(G) per ogni vertice u di V(G) ripeti: colore(u) = bianco padre(u) = NULL per ogni vertice u di V(G) ripeti: se colore(u)=bianco allora se (VISITA(G, u)=OK) ritorna u End VISITA(G, u) se (ottimo(u)) ritorna OK colore(u) = grigio per ogni vertice v adiacente ad u ripeti: se colore(v)=bianco allora: padre(v) = u VISITA(G, v) colore(u) = nero End inclusione delle librerie #include <stdlib.h> #include <stdio.h> definizione della costante che indica la massima dimensione del grafo (|V|<MAX). #define MAX 100 definizione della struttura utilizzata per rappresentare i vertici del grafo nelle liste di adiacenza. struct nodo ; Legge in input una sequenza di n interi e li memorizza su una lista. Restituisce il puntatore al primo elemento della lista. struct nodo *leggi_lista(void) return(primo); Legge in input le n liste di adiacenza (una per ogni vertice del grafo G). Restituisce il numero di vertici di cui e' costituito il grafo e l'array di puntatori ai primi elementi di ogni lista di adiacenza. int leggi_grafo(struct nodo *lista[]) return(n); Visita il grafo G a partire dal vertice u, con un algoritmo ricorsivo. void visita(int u, struct nodo *l[], int colore[], int pi[]) p = p->next; return; Funzione principale: innesca la ricorsione chiamando la funzione visita. int main(void) for (i=0; i<n; i++) if (colore[i] == 0) visita(i, lista, colore, pi); printf("La visita ha generato il seguente albero DFS:\n"); for (i=0; i<n; i++) return(1); |
|
|
Ricerca in ampiezza - Implementazione in C
(l'implementazione manca della funzione di test di ottimalità dei nodi in esame)
| bfs.c Implementazione dell'algoritmo BFS (Breadth First Search) per la visita in ampiezza di un grafo. Pseudo-codifica dell'algoritmo: per ogni vertice u di G diverso dalla sorgente s ripeti: colore(u) = bianco d(u) = infinito pi(u) = null end colore(s) = grigio d(s) = 0 pi(s) = null Q = fintanto che la coda Q non e` vuota ripeti: sia u il primo elemento della coda Q per ogni vertice v adiacente ad u ripeti: se colore(v) = bianco allora colore(v) = grigio d(v) = d(u) + 1 pi(v) = u aggiungi v alla coda Q end end elimina il primo elemento (u) dalla coda Q se ottimo(u) ritorna u colore(u) = nero end inclusione delle librerie #include <stdlib.h> #include <stdio.h> definizione della costante che indica la massima dimensione del grafo (|V|<MAX). #define MAX 100 definizione della struttura utilizzata per rappresentare i vertici del grafo nelle liste di adiacenza ed i nodi della coda Q. struct nodo ; Legge in input una sequenza di n interi e li memorizza su una lista. Restituisce il puntatore al primo elemento della lista. struct nodo *leggi_lista(void) return(primo); Legge in input le n liste di adiacenza (una per ogni vertice del grafo G). Restituisce il numero di vertici di cui e' costituito il grafo e l'array di puntatori ai primi elementi di ogni lista di adiacenza. int leggi_grafo(struct nodo *lista[]) return(n); accoda aggiunge un nodo alla coda Q; "primo" punta la primo elemento, "ultimo" punta all'ultimo elemento della coda. void accoda(struct nodo **primo, struct nodo **ultimo, int x) estrai restituisce il primo elemento della coda e lo elimina dalla coda stessa. int estrai(struct nodo **primo, struct nodo **ultimo) else return(r); bfs visita in ampiezza del grafo rappresentato tramite le liste di adiacenza l[0], ..., l[n-1]; la visita parte dal vertice s. void bfs(struct nodo *l[], int n, int d[], int pi[], int s) colore[s] = 1; d[s] = 0; accoda(&primo, &ultimo, s); while (primo != NULL) v = v->next; }colore[u] = 2; } return; Funzione principale. int main(void) return(1); |
|
|
|
|
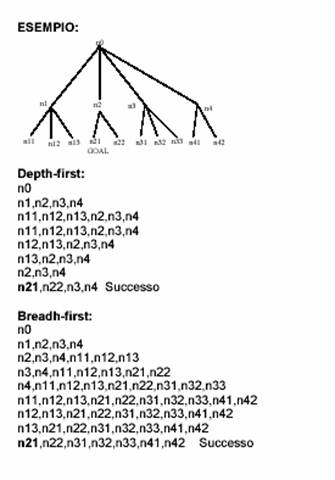
La strategia di ricerca in ampiezza è completa (ossia permette di determinare una soluzione, se esiste) mentre la strategia di ricerca in profondità non è completa in quanto può andare in ciclo su un cammino infinito. Per ovviare a questo problema spesso si associa alla strategia in profondità un limite massimo oltre il quale la ricerca su un cammino non deve essere proseguita. La strategia in ampiezza permette inoltre di determinare sempre la soluzione di lunghezza minima. Di lato si presenta un esempio di applicazione di ricerca BFS e DFS sullo stesso albero. In questo caso, entrambi i metodi forniscono il risultato corretto. |
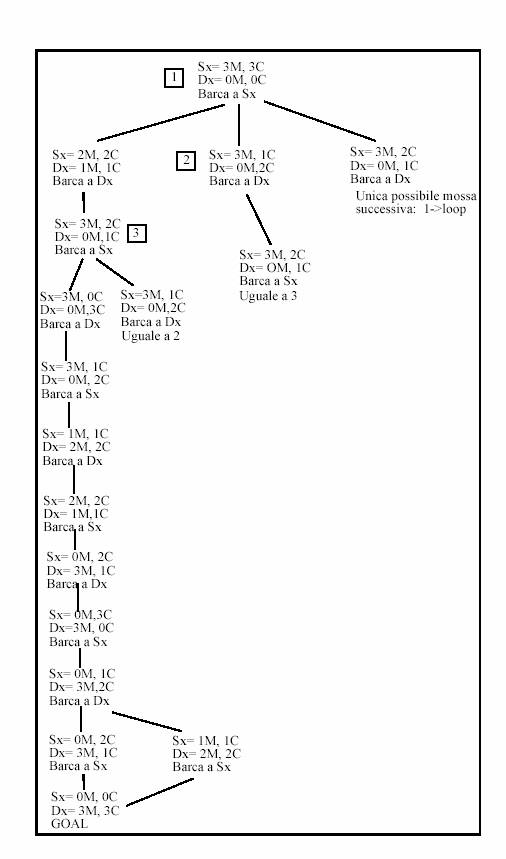
Il problema dei tre missionari e dei tre cannibali consiste nel determinare come essi possano tutti e sei trasferirsi da un lato all'altro di un fiume utilizzando una barca che può portare al massimo due persone evitando che i cannibali mangino i missionari. I cannibali mangiano i missionari ogni volta che li superano in numero.
Si supponga, per semplicità, che non si possa riproporre durante la ricerca uno spazio già presente nell'albero ad un livello precedente (tali stati quindi non devono essere descritti nell'albero di ricerca).
Nel risolvere questo problema come ricerca nello spazio degli stati, è necessario porre attenzione alla descrizione di stato che deve essere completa, ossia deve descrivere tutta l'informazione che caratterizza un nodo.
Descrizione stato:
Sx: Numero Missionari e Cannibali sulla riva Sx
Dx: Numero Missionari e Cannibali sulla riva Dx
Barca: Posizione barca.
Gli stati di fallimento (numero di cannibali maggiore a quello dei missionari su una sponda) non sono stati rappresentati. Potevamo rappresentarli ed etichettarli con fail. Nell'immagine seguente, l'albero di ricerca in profondità generato dall'algoritmo.
Esempio - Il problema dei mucchietti delle monete (fiammiferi)
Si supponga di avere 12 monete ripartite in tre distinte pile. La prima pila è formata da 4 monete, la seconda da 7 e la terza da 1. Lo spostamento delle monete deve avvenire secondo la seguente regola: ogni volta che si spostano delle monete da una pila A ad un'altra B, le monete in B devono raddoppiare di numero. Viene mostrato lo spazio di ricerca con stato iniziale rappresentato dalla tripla <4,7,1> e stato finale dalla tripla <4,4,4> generato in due spostamenti ed esplorato con strategia in ampiezza e profondità.
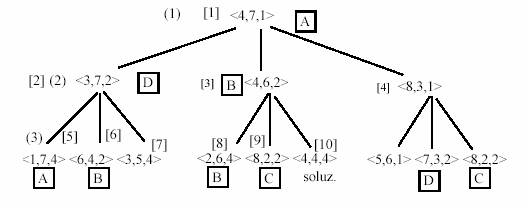
Il depth first (numeri in parentesi tonda) va in loop supponendo di avere un criterio preferenziale che seleziona le mosse come in figura <4,7,1>, <3,7,2>, <1,7,4>, <3,7,2>..... Se invece si suppone di fermarsi a due livelli di esplorazione (senza generare ed esplorare i livelli sottostanti), il depth first trova una soluzione in 9 passi. In breadth first (numeri in parentesi quadra) trova la soluzione in 10 passi.
Un contadino doveva trasportare al di là di un fiume
il suo lupo, la sua capra e una cesta di cavoli, avendo a disposizione una
barca poco capiente che avrebbe potuto trasportare solo lui in compagnia di una
delle due bestie o lui insieme alla sola cesta di cavoli. Ma se avesse lasciato
su una delle due rive del fiume il lupo insieme alla capra, questi l'avrebbe uccisa
per mangiarsela; allo stesso modo non avrebbe potuto lasciare insieme capra e
cavoli perché la bestia li avrebbe sicuramente mangiati. La sua presenza era
importante perché il lupo non nuocesse alla capra e la capra non toccasse i
cavoli.
Come fece ad attraversare il fiume con lupo, capra e cavoli?
RICERCA EURISTICA
Le procedure di ricerca Euristica sono delle tecniche di ricerca che, nella risoluzione di un problema non considerano tutti i possibili cammini dello spazio del problema, ma realizzano una selezione dei cammini, scegliendo di volta in volta quelli che risultano più promettenti.
Queste procedure si applicano dove il problema prevede uno spazio di stati molto ampio, tale da renderne impossibile la ricerca attraverso procedure esaustive.
Il criterio secondo il quale vengono selezionati i cammini è sempre basato su conoscenze di natura generale del problema, i vari criteri possibili prendono il nome di euristiche. E' necessario però specificare che le euristiche non sono né complete, né corrette, tuttavia ci danno risultati migliori rispetto ad operare con una ricerca cieca.
I principali vantaggi sono:
Riduzione drastica del numero di cammini considerati: ci sarà la possibilità di ignorare dei cammini, che secondo la nostra valutazione euristica, non portano alla soluzione;
miglioramento della qualità media di ogni cammino esplorato;
possibilità di ottenere una migliore comprensione del problema: il fallimento di una euristica ci fornisce indicazioni sulla natura del problema, studiando il motivo per cui l'euristica fallisce.
La mancanza di completezza e correttezza della ricerca euristica rappresentano le principali limitazioni di tale tecnica. Infatti rinunciando alla completezza, rinunciamo alla possibilità di avere una soluzione "ottima" accontentandoci di una soluzione "buona". Per quanto riguarda la correttezza invece, ci sono problemi per cui è possibile stabilire un limite superiore sull'errore; in questo caso possiamo sapere quanto perdiamo in accuratezza in cambio di efficienza, tuttavia questo limite non è individuabile per tutte le euristiche in quanto per problemi reali è difficile misurare la bontà di una soluzione.
La conoscenza euristica può essere specificata nel problema in due modi
nelle regole Le regole non descriveranno solo le possibili mosse, ma anche le mosse "sensate".
con la funzione euristica La f.e. è una funzione che valuta gli stati del problema e determina quanto siano buoni per giungere alla soluzione.
Mentre non è sempre possibili inserire l'euristica nelle regole possiamo sempre trovare una funzione euristica, e di questo ci occuperemo nei prossimi paragrafi.
Tali funzioni, assegneranno ad ogni stato del problema una misura di desiderabilità. Per tanto i programmi useranno metodi per massimizzare o minimizzare il valore di queste funzioni in modo da guidare la ricerca nella direzione più vantaggiosa diminuendo il numero di passi da effettuare, e nel caso limite trovando la soluzione senza effettuare ricerca. E' ovvio che più accurato sarà il calcolo della funzione tanto più sarà oneroso. E' necessario quindi trovare un compromesso per non far in modo che il costo del calcolo sia maggiore del risparmio nel processo di ricerca.
A questo punto è chiaro quanto sia cruciale la scelta dell'euristica. Tale scelta sarà realizzata attraverso uno studio accurato del problema, quindi è opportuna una classificazione. I problemi di solito vengono classificati secondo delle caratteristiche.
a) Annullamento dei passi distinguiamo tra problemi in cui si possono ignorare i passi già fatti in quanto non hanno portato a miglioramenti e problemi in cui ciò non è possibile.
b) Pianificazione: distinguiamo tra problemi in cui è possibile pianificare una sequenza di mosse e sapere dove si arriva, e problemi dove ciò non si può fare. Questo capita perché ad esempio non si ha conoscenza dell'ambiente;
c) Soluzione Assoluta o Relativa I problemi sono classificabili anche in base al tipo di soluzione; in problemi con un'unica soluzione non è importante come ci si arriva, mentre quando ci sono più soluzioni potremmo trovare una soluzione non ottimale.
d) Soluzione Stato o Cammino Abbiamo ancora una classificazione in base al tipo di soluzione, distinguiamo se la soluzione è uno stato (ad esempio in un problema di classificazione) oppure un cammino (ad esempio il gioco dell'8).
Nei prossimi paragrafi verranno presentati dei metodi di ricerca euristica.
L'algoritmo di Hill Climbing è una procedura euristica tra le più semplici e le più utilizzate per risolvere i problemi.
Il nome della procedura deriva dal fatto che essa opera come uno scalatore (e ne incontra gli stessi problemi), il quale per raggiungere la vetta, di fronte ad una scelta opta per quella che lo porta verso l'alto.
Così la procedura partendo dalla radice dell'albero fa espandere il figlio per cui il valore della funzione euristica si avvicina di più a quello finale.
Possiamo schematizzare l'algoritmo come segue
Considera la radice come nodo corrente.
SE il nodo corrente è un nodo finale allora hai RISOLTO il problema
Se il nodo corrente non ha figli allora la procedura ha FALLITO
Espandi il nodo corrente e calcola la funzione euristica per i figli
Scegli tra i figli quello che ha il miglior valore di funzione euristica
se tale nodo ha un valore euristico peggiore del corrente allora la procedura ha FALLITO
Considera nodo corrente il nuovo nodo. Ritorna al passo 2
In pratica lo HC risulta essere essenzialmente una ricerca in profondità nella quale non viene espanso il nodo più recente, ma il più promettente relativamente all'euristica adottata.
La procedura di HC tuttavia viene meno in presenza di situazioni denominate
a) altipiani
b) vette secondarie
c) creste
In pratica, un'implementazione pura dell'HC determina una strategia di ricerca irrevocabile, senza la possibilità di back-tracking, quindi non mantiene tracce delle opzioni scartate. Quindi non si accorge quando entra il loop. I loop sono possibili nel caso in cui ci sia una serie di nodi con la stessa funzione euristica, questa situazione viene chiamata altipiano. Un altro problema insidioso è quello delle vette secondarie, che si presenta quando la funzione trova un massimo (ovvero minimo) relativo, quindi termina risolvendo il problema, ma non trovando una soluzione ottima. In fine abbiamo il problema delle creste, che si verifica quando in tutte le direzioni possibili troviamo nodi con funzione euristica peggiore del nodo corrente, facendo così fallire la ricerca.
Nella procedura di Hill Climbing, se ci sono vette secondarie, altipiani o creste la ricerca non può procedere. Per risolvere questi problemi è stata trovata un'altra euristica che ha un approccio globale al problema. La ricerca Best First prende in considerazione tutti i nodi che sono stati esaminati fino a quel momento ed espande il nodo che valutato con la funzione euristica migliore da risultati migliori.
L'algoritmo può essere schematizzato in 4 passi
Sia L la lista dei nodi iniziali del problema, ordinati secondo la distanza dal goal.
Sia n il primo nodo di L. Se L è vuota la procedura fallisce
Se n è il goal fermati e restituisci la strada percorsa per raggiungerlo.
Altrimenti rimuovi n da L e aggiungi a L tutti i nodi figli di n; riordina la lista L in base alla distanza relativa dal goal, e ritorna al passo 2.
La funzione euristica utilizzata è
f(n)=g(n)+h'(n)
dove g(n) è la profondità del nodo e h'(n) è la distanza dal goal.
Espandendo i nodi per cui f(n) è più piccola troviamo una via di mezzo tra i vantaggi dell'Hill Climbing cioè l'efficienza e quelli della ricerca a costo uniforme (ottimalità e completezza). Cioè consideriamo oltre la distanza dal goal anche il costo per raggiungerlo. In generale però questo tipo di ricerca non è ottimale.
Un problema della BF è la complessità spaziale, infatti in memoria deve essere conservata tutta la frontiera, problema che può essere risolto aggiungendo un'ulteriore fattore eurisitico e cioè mantenendo in memoria ad ogni passo solo i primi k nodi più promettenti
La BF può risolvere problemi non banali del tipo "Missionari e Cannibali": 3 missionari e 3 cannibali devono attraversare un fiume. I missionari per non essere mangiati non devono essere mai meno dei cannibali che sono sulla tessa loro sponda , e c'è una sola barca che contiene al massimo due persone. In questo caso si considera come costo del cammino il numero di traversate, e come distanza dal goal il numero di persone rimaste sulla prima sponda.
Algoritmo A
Un Algoritmo A è un algoritmo Best First con una funzione di valutazione euristica del tipo
F(n)=g(n)+h(n) con h(n) >=0 per ogni n e h(goal)=0
Dove g(n) è il costo del cammino per raggiungere il nodo n, e h(n) è una stima del costo per raggiungere un nodo goal.
Vediamo dei casi particolari di algoritmi di tipo A
h(n)=0 abbiamo una ricerca Uniforme
h(n)=0; g(n)=depth(n) abbiamo una ricerca in ampiezza.
g(n)=0; abbiamo una ricerca Greedy
In particolare è possibile dimostrare utilizzando funzioni euristiche con g(n) > depth(n) l'algoritmo A fornisce soluzione ottima.
Un algoritmo A* è un algoritmo A che una funzione euristica ammissibile monotona.
Una funzione Euristica ammissibile è una funzione del tipo
F(n) = g(n) + h (n)
Dove h(n) è una sottostima del cammino minimo tra n ed il goal e g(n) è il cammino percorso dalla radice al nodo n.
Un buona classe di funzioni ammissibili sono le funzioni che godono di monotonia su h
h(n) - h(n') <= g(n') - g(n) = costo_arco(n,n')
Le euristiche monotone garantiscono un'ottimalità locale e cioè che quando un nodo viene scelto
Concludendo possiamo dire che le procedure euristiche non sono la panacea dei metodi di ricerca, ma possono velocizzare molto il lavoro, sono quindi utili in problemi in cui ci serve una soluzione velocemente ed in problemi in cui la complessità per avere la soluzione ottima è esponenziale (come ad esempio il problema del commesso viaggiatore).
3.3 CONSTRAINT SATISFACTION PROBLEMS
Per molti anni i Constraint Satisfaction Problems (CSP) sono stati un oggetto di studio nel campo dell'Intelligenza Artificiale, la cui ricerca era concentrata sui problemi combinatoriali. Il contributo dato da AI è stato considerevole, infatti, molti algoritmi sono diventati una base per risolvere i problemi CSP.
Un Constraint Satisfaction Problems (CSP) è così definito:
Un insieme di variabili X=.
Ogni variabile xi, appartiene ad un finito insieme Di (dominio).
Un insieme di vincoli (constraints) restringe i valori che le variabili possono assumere.
Una soluzione di un CSP è un assegnamento di valori alle variabili, in modo che ogni vincolo sia soddisfatto. Le soluzioni di un CSP si possono trovare, ricercando sistematicamente attraverso i possibili assegnamenti alle variabili. I metodi di ricerca si dividono in due ampie classi:
Quelle che attraversano lo spazio delle parziali soluzioni
Quelli che esplorano completamente lo spazio dei valori assegnati stocasticamente, a tutte le variabili.
Le ragioni, che spiegano perché un problema viene rappresentato come un CSP sono:
La vicinanza al problema originale, infatti, le variabili corrispondono direttamente agli input del problema, e i vincoli possono essere espressi senza traduzione in disuguaglianze lineari. Questo crea una formulazione più semplice.
Gli algoritmi per risolvere i CSP non sono complicati, e le soluzioni si possono trovare in tempi apprezzabili.
Vincoli Binari
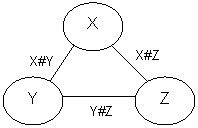
Un vincolo può influenzare un certo numero di variabili. Bisogna distinguere, però, due casi: unario e binario. Per i vincoli unari si può eseguire un preprocessing del dominio, e possono essere ignorati. I vincoli binari possono essere rappresentati come un "grafo dei vincoli" (constraint network), in cui ogni nodo rappresenta una variabile, e ogni arco rappresenta un vincolo tra le due variabili (estremi dell'arco). Anche un vincolo unario, può essere rappresentato con un arco la cui origine e fine è nello stesso nodo.
Esempio: X # Y, Y # Z, X # Z
E' possibile convertire un CSP arbitrario, in un equivalente CSP binario mediante l'utilizzo di una nuova variabile che incapsula un insieme di variabili vincolate. Questa nuova variabile è chiamata incapsulata; ed il suo dominio è il prodotto cartesiano dei domini delle variabili individuali.
Esempio: Variabili individuali e i loro domini X::[1,2], Y::[3,4], Z::[5,6]
Variabile incapsulata e relativo dominio U::[(1,3,5), (1,3,6), (1,4,5), (1,4,6), (2,3,5), (2,3,6), (2,4,5), (2,4,6)]
Algoritmi di ricerca
Un CSP può essere risolto utilizzando le seguenti strategie:
Generate-and-test (GT)
Backtracking (BT)
Il metodo Generate-and-test ha origine dall'approccio matematico per la risoluzione di problemi combinatori. Il metodo GT genera ogni possibile valore da assegnare alle variabili, e poi verifica se la soluzione soddisfa i vincoli originari. La soluzione è data dalla prima combinazione di valori che soddisfa tutti i vincoli.
Algoritmo GT:
gt(Variables,Constraints,Solution):-I difetti del metodo GT sono legati, alla generazione di molti valori, rifiutati poi dal test, da assegnare alle variabili. Per ovviare a tale inconveniente, l'algoritmo GT si utilizza con un approccio di backtracking.
Il backtracking è il più comune algoritmo per effettuare una ricerca sistematica. Esso cerca di estendere, una parziale soluzione che specifica dei valori coerenti per qualche variabile, verso una completa soluzione. Infatti sceglie ripetutamente dei valori da assegnare alle altre variabili, rispettando sempre la coerenza con i valori della soluzione corrente. Nel metodo BT le variabili sono stanziate in sequenza, rilevando man mano la validità dei vincoli; se una parziale soluzione viola un vincolo, si esegue il backtracking, che riporta le variabili al precedente assegnamento, per il quale ci sono ancora delle scelte. I principali svantaggi di tale metodo sono:
Thrashing, in pratica ripetuti fallimenti dovuti alle stesse ragioni. Questo è causato perché lo standard backtracking non identifica la reale ragione di un conflitto. Tale inconveniente può essere evitato, utilizzando intelligent backtracking, che memorizza le variabili che portano a fallimenti.
Redundant work, in pratica se i valori delle variabili che portano ad un conflitto sono identificati durante intelligent backtracking, essi non sono poi ricordati, per lo stesso conflitto, nel calcolo successivo. Per risolvere quest'inconveniente si utilizza dependency-directed backtracking, che aggiunge ulteriori algoritmi che causano un certo carico computazionale, bilanciato, però, dal vantaggio del loro utilizzo.
Detects the conflict too late, è dovuto alla non abilità nell'individuare i conflitti prima che essi accadano. Anche quest'inconveniente può essere evitato utilizzando delle tecniche consistenti (forward check).
Tecniche consistenti
Queste tecniche, sono state introdotte per migliorare l'efficienza dei programmi di riconoscimento d'immagine (picture recognition), dai ricercatori d'Intelligenza Artificiale. Il riconoscimento d'immagine, comporta un etichettamento di tutte le linee in un'immagine in modo consistente, ed il numero di possibili combinazioni può essere enorme, però sono poche quelle consistenti. Bisogna notare che tali tecniche sono deterministiche. Nei CSP binari, vengono utilizzate varie tecniche consistenti per i grafi dei vincoli, riducendo così la ricerca.
Nodo Consistente: è la più semplice tecnica consistente, ed è riferita ai nodi del grafo. Un nodo che rappresenta una variabile X, è un nodo consistente, se per ogni valore del dominio di X, il vincolo unario su X è soddisfatto. Per esempio, se il dominio D di X contiene un valore "a", che non soddisfa il vincolo unario di X, l'assegnazione di "a" a X sarà sempre inconsistente, e così il nodo inconsistente può essere eliminato rimovendo il valore di "a" dal dominio D.
Arco Consistente: l'arco (X, Y) è un arco consistente, se per ogni valore x, del dominio di X, c'è un valore y, nel dominio di Y tale che X=x e Y=y è permesso dal vincolo binario tra X e Y. Bisogna notare che il concetto di arco consistente, è direzionale; cioè se (X, Y) è consistente, non significa che anche (Y, X) sia consistente. L'utilizzo di queste tecniche consistenti, permette di realizzare degli schemi per la risoluzione di problemi CSP, infatti, si possono creare delle strategie per prevenire i conflitti.
Strategie di anticipazione
Combinare metodologie come backtracking e tecniche consistenti, può essere d'aiuto, per rendere più efficienti gli algoritmi per la risoluzione dei CSP. Alcuni schemi che adottano tale soluzione sono: Forward Checking e Look Ahead.
Forward Checking
Tale metodo, esegue una "forma ristretta" di arco consistente per le variabili che ancora non sono state stanziate. Parliamo di forma ristretta di arco consistente, perché forward checking controlla solo i vincoli tra le variabili correnti, e quelle future. Quando un valore è assegnato ad una variabile corrente, ogni valore del dominio che sarà in conflitto (in futuro) con questa variabile, viene temporaneamente eliminato. Il vantaggio di questa tecnica, è che se il domino diventa vuoto, allora la soluzione parziale corrente è inconsistente. Questo permette di costruire un albero di ricerca, in cui i fallimenti sono eliminati prima.
Look Ahead
Questo metodo ha vantaggio, di riuscire a scovare i conflitti delle variabili future, permettendo così di eliminare dei rami nell'albero di ricerca, prima di un forward checking, però effettua più lavoro.
Ordine delle variabili e dei valori
Un algoritmo di ricerca per la risolvere i CSP, richiede un ordine nel considerare le variabili, non solo, ma anche un ordine dei valori a loro assegnati. Gli esperimenti eseguiti dai ricercatori, hanno mostrato che l'ordine delle variabili può avere un impatto sostanziale, per la ricerca della soluzione, infatti, un giusto ordine può migliorare l'efficienza dell'algoritmo. Le strategie impiegate sono:
Ordine statico, che è specificato prima che la ricerca inizi, e non viene cambiato.
Ordine dinamico, il quale dipende dallo stato corrente della ricerca.
Diverse euristiche, sono state sviluppate per selezionare l'ordine delle variabili. La più comune, è basata sul principio di "first-fail", in pratica, durante la ricerca è meglio fallire subito che sprecare risorse in una strada sbagliata. In questo metodo, la variabile con meno alternative successive viene stanziata, in questo modo l'ordine delle variabili stanziate, è in generale differente nei diversi rami dell'albero di ricerca. Un'altra euristica, applicata quando tutte le variabili hanno un uguale numero di valori, è di scegliere la variabile che partecipa in più vincoli.
Anche l'ordine dei valori, da assegnare alle variabili, ha una certa influenza sul tempo di calcolo della soluzione, infatti, l'euristica che può essere utilizzata, controlla che i valori assegnati, portano ad una più facile soluzione del CSP. Questo richiede, di stimare la difficoltà di risoluzione di un CSP.
Algoritmi stocastici ed euristici
Questi algoritmi, usano metafore tipo "rapair" o "hill-climbing", per muoversi verso soluzioni più complete. Per evitare di restare bloccati in minimi locali, si utilizzano varie euristiche, per randomizzare la ricerca.
Hill-Climbing
E' probabilmente l'algoritmo di ricerca locale più conosciuto. L'algoritmo è diviso in tre passi:
Assegnamento casuale a tutte le variabili (stato iniziale).
Dirigersi verso uno stato vicino, che ha numero di vincoli violati più piccolo.
Se un minimo locale è raggiunto, allora si ricomincia da un altro stato generato in modo casuale.
L'algoritmo, procede finché una soluzione del problema, non è trovata.
Per evitare di esplorare tutti gli stati vicini (allo stato corrente), sono utilizzate alcune euristiche per trovare le mosse successive. L'euristica Min-Conflicts, sceglie la variabile che è coinvolta in qualche vincolo non soddisfatto, e poi casualmente sceglie un valore che minimizzi il numero di vincoli violati. Se, tale valore non esiste, si sceglie casualmente un valore che non incrementa il numero di vincoli violati.
procedure MC(Max_Moves)Min-Conflicts-Random-Walk
Dato che l'algoritmo min-conflicts non può sfuggire ai minimi locali, si utilizza una strategia random-walk, che per una data variabile si sceglie casualmente un valore con una probabilità p, e si applica l'algoritmo MC con probabilità 1-p.
procedure MCRW(Max_Moves,p)L'algoritmo Steepest-Descent, è la versione Hill-Climbling dell'algoritmo Min-Conflicts. Invece di selezionare casualmente la variabile in conflitto, l'algoritmo esplora, gli stati vicini alla configurazione corrente, e seleziona il vicino migliore in base al numero di conflitti. Per evitare ottimi locali, si utilizza la strategia random-walk.
Tabu-Search
Tabu search(TS) è un metodo, che permette di evitare i cicli e minimi locali. Esso si basa sull'utilizzo di una memoria flessibile, chiamata tabu list, capace di mantenere traccia delle precedenti configurazioni incontrate. Nella tabu list, vengono memorizzate gli attributi delle configurazioni. Sono definite delle regole, chiamate criteri di aspirazione, che permettono di sovrascrivere gli attributi di una configurazione presente nella memoria, nel caso in cui la nuova configurazione è migliore della precedente.
Gsat è una procedura greedy di ricerca locale, utilizzata per soddisfacimento di formule logiche in forme normali congiuntive (CNF). Tali problemi sono chiamati SAT o k-SAT (k è il numero di letterali in ogni clausola), e sono NP-hard. La procedura inizia con un arbitrario assegnamento delle variabili, e permette di raggiungere, il più alto grado di soddisfacimento per piccole successioni di trasformazioni, chiamate rapairs o flips
Tutti gli algoritmi visti precedentemente, sono basati su di un'idea comune, conosciuta come nozione di local search. Nella ricerca locale, una configurazione iniziale è generata, e l'algoritmo si muove da tale configurazione ad una vicina, finché una soluzione, o una buona soluzione non viene trovata.
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2025