|
|
| |
La codifica audio rappresenta un insostituibile mezzo per la trasmissione e l'elaborazione di un qualunque segnale audio, a partire da un semplice segnale vocale fino al più complesso brano musicale.
La conversione di una qualsiasi forma audio (suoni, musica,.) in dati memorizzabili e utilizzabili da un sistema digitale consente di modificare a piacimento i dati stessi e di scambiarli anche tra utenti a grande distanza.
Grazie allo sviluppo dell'audio digitale si può contare su una qualità costante dell'audio archiviato e sulla costanza nel tempo dei codificatori numerici. Si preferisce studiare codificatori a basso bit rate per garantire un aumento dell'efficienza a bassi costi, mantenendo comunque alta la qualità del segnale ricostruito. Infine, dalla parte del decodificatore, si richiede bassa complessità e basso consumo di energia.
Si ricordi che la qualità di un segnale audio presente su un supporto digitale è proporzionale alla memoria occupata. Con un semplice esempio numerico si dimostra quanto detto e
si mostrano facilmente anche gli ordini di grandezza: un brano musicale contenuto su di un cd contiene frequenze non superiori ai 22 kHz. Sarà dunque sufficiente campionare al doppio della frequenza massima, basta campionare a 44.1 kHz, usando ad esempio 16 bit per la quantizzazione delle ampiezze. Ciò vuol dire prendere 1 campione ogni 22.6 micro secondi. Se si sceglie di campionare 1 minuto di musica, in 1 secondo si prendono 44100 campioni, in 1 minuto 2646000 campioni. Per memorizzare su di un supporto digitale 1 minuto di musica in qualità cd occorrono 423336000 bit (2646000*16), cioè circa 5 Mbytes di memoria. Essendo poi i brani stereo, cioè formati da 2 canali indipendenti, si moltiplica per due ottenendo 10 Mbytes. Al fine di ridurre i costi in termini di memoria si studiano quindi speciali codifiche per comprimere i dati senza perdere la qualità del segnale.
Una prima classificazione puo' essere fatta basandosi solo sulla larghezza di banda del sistema e sulla qualità del segnale decodificato. Questi schemi, infatti, non tengono conto del fatto che il segnale vocale ha una sua struttura tipica e sfruttando ciò si può ridurre la velocità di trasmissione e migliorare quindi la qualità del sistema.
Un'importante codifica audio dove il parlato è
rappresentato da un numero fisso di campionamenti al secondo è PCM (Pulse
Code Modulation). E' molto utilizzata nelle reti telefoniche con 8000
campionamenti a 8 bit al secondo, così da trasmettere 64000 bit al secondo. Il
segnale dapprima viene filtrato per eliminare eventuali errori di aliasing
e poi campionato; in seguito, a ciascun campione del segnale viene sostituita
l' indicazione dell'intervallo di appartenenza i[k]. Se M è il numero di dei
possibili intervalli, ciascun termine i può assumere M determinazioni ed è
quindi rappresentato da un vettore binario a log2 M componenti. A lato
ricezione la sequenza ricevuta viene dapprima segmentata in successioni di log2
M bit e ad ogni successione viene associato l' intervallo i corrispondente e a
quest'ultimo il suo valore centrale qi. La sequenza dei valori quantizzati così
ricostruita viene trasformata in un segnale campionato che passa infine
attraverso un filtro ricostruttore passa-basso.
Lo schema di quantizzazione PCM non dà buone compressioni, non tiene infatti
conto della variabilità a breve termine delle caratteristiche del segnale. I
sistemi che tengono conto di questa variabilità e in funzione di questo operano
una scelta della trasformazione da operare localmente vengono detti sistemi
adattativi.
Una versione più efficiente del PCM è l' ADPCM (Adaptive Differential Pulse Code Modulation), che invece di trasmettere i campionamenti PCM trasmette le differenze tra due campionamenti successivi, così da ottenere una maggiore compressione.
A-Law: e' un metodo utilizzato, particolarmente in Europa ed in Asia, per diminuire la dinamica audio passando da campioni a 12 bit a campioni a 8 bit utilizzando una trasformazione non lineare dei valori campionati.
m-Law: simile al metodo A-Law, viene utilizzato negli Stati Uniti. Come il precedente, presenta un rapporto SNR di 38 dB e consente un bit-rate di 64 Kbit/s.
Questi ultimi due metodi riducono le prestazioni di picco a vantaggio di una migliore uniformità di comportamento al variare della potenza del segnale.
Altro schema di classificazione
Si possono distinguere due categorie di sistemi che invece tengono conto della struttura tipica della voce. I sistemi che appartengono alla prima categoria sono chiamati sistemi a codifica di forma d'onda e cercano di creare uno schema di quantizzazione più evoluto (in genere adattativo), migliorato attraverso l'uso di pesature, che tengono conto delle proprietà uditive dell'orecchio.
Una seconda categoria di sistemi utilizza le conoscenze della struttura del segnale vocale per generare in ricezione un segnale , attraverso un modello di generazione locale, grazie ai parametri estratti dal segnale vocale originario e trasmessi in sostituzione di quest'ultimo. Al lato di emissione infatti, avviene un'estrazione e codifica di opportuni parametri del segnale originario, che una volta trasmessi consentono al lato ricezione di generare un segnale sintetico dotato di caratteristiche le più simili possibili a quelle del segnale originario.Questi sono chiamati sistemi a codifica di parametri Rappresentanti di queste due categorie sono la codifica MP3 (MPEG 1, layer III) per la codifica a forma d'onda, e il CELP (Code-Excited Linear Prediction) per la codifica di parametri, che è, fra l'altro, usato nei sistemi GSM di telefonia mobile.
4.1 LPC (Linear Predictive Coding)
4.2 Codificatori 'Analysis- by- synthesis'
Predittore a breve termine
Metodo dell'autoccorrelazione
Predittore a lungo termine
Prima di passare a una più accurata descrizione di alcuni sistemi a codifica di parametri e a codifica di forma d'onda è utile fare un cenno al modello di generazione del segnale vocale.
Gli organi di fonazione comprendono i polmoni, le corde vocali e il tratto vocale; a seconda della loro posizione vengono prodotti diversi tipi di suoni. Brevemente si può dire che, se le corde vocali non sono tese e vi è un'improvvisa apertura lungo il tratto vocale vengono emessi suoni sordi; se le corde vocali sono invece tese l'aria non riesce a fuoriuscire se non quando l'accresciuta pressione prodotta dai polmoni non riesca a vincere l'azione di chiusura dei muscoli che tendono le corde vocali. L'aria fuoriesce a sbuffi, la pressione acustica a valle delle corde vocali ha un andamento periodico, con forma d'onda triangolare. La frequenza fondamentale, che varia in genere tra gli 80 e i 300 Hz in funzione del parlatore è detta frequenza di pitch Fo, intendendo con la parola pitch il tono della voce. I suoni emessi in questo caso vengono detti sonori.
In questo modello figurano due diverse sorgenti di eccitazione, entrambe a distribuzione (stazionaria), uniforme ed a potenza unitaria; la prima, che schematizza i suoni sonori, emette una sequenza periodica di impulsi di frequenza Fo; la seconda, che invece schematizza i suoni sordi, o non vocalizzati, emette una sequenza puramente casuale.
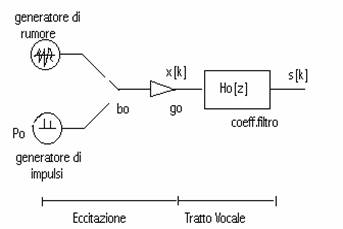
Fig.1 Schema generale del modello del segnale vocale
Il segnale di eccitazione x[k] emula la pressione acustica all'ingresso del tratto vocale, schematizzato con Ho[z] sia nel caso sonoro (bo=1) che nel caso sordo (bo=0).
Inoltre il filtro Ho[z] tiene conto della forma effettiva del segnale di eccitazione entro il periodo, quando vengono emessi suoni sonori.
Lo spettro complessivo è pari al prodotto di una componente periodica in frequenza di ampiezza diversa da zero solo in un intorno dei multipli di Fo, dovuta all'eccitazione, per una componente lentamente variabile in frequenza, che descrive il comportamento del tratto vocale.
In un tratto temporale di 15-30 ms,al lato di emissione vengono calcolati e quantizzati i coefficienti di predizione, viene classificato il suono e, se sonoro, viene individuata la frequenza fondamentale.
Tutti questi parametri vengono quantizzati e inviati . Al lato ricezione, i parametri vengono dequantizzati e si ricostruisce il segnale sintetico x'[k].
Questi sistemi presentano il vantaggio di una bassa velocità di trasmissione, sebbene non presenti un'elevata qualità . Si riescono a realizzare sistemi a velocità compresa tra 1200 e 2400 bit/sec guadagnando in velocità da 50:1 a 25:1 rispetto al sistema PCM.
I codificatori vocali LPC operano a un bit -rate inferiore ai 2 kbit/sec, ma la qualità del segnale sintetico diventa scadente, ad esempio, per applicazioni telefoniche commerciali.
Il bisogno di ottenere una buona qualità del discorso a un bit-rate minore di 10 kbit/sec per applicazioni su canali con larghezza di banda limitata ha sviluppato l'interesse nel ricercare algoritmi più efficienti per la codifica LPC. La limitazione maggiore della codifica LPC è nell'assumere che i segnali parlati sono o sordi o sonori, percui la sorgente d'eccitazione è o un treno di impulsi o un rumore. In verità il tratto vocale può essere eccitato da entrambi i tipi di suoni.
Dal 1982 cominciarono i primi studi verso un nuovo modello di eccitazione:'multi-pulse excitation', in cui non c'e' il bisogno di conoscere a priori la natura del suono.
L'eccitazione è modellata da un numero di impulsi (in genere 4 per ogni 5 ms) le cui ampiezze e posizioni sono determinate minimizzando l'errore pesato tra il segnale vocale originario e quello sintetizzato.
Da queste ipotesi nascono una serie di codificatori sempre migliori capaci di mantenere la qualità del discorso a bassi bit-rate (<10 kbit/sec e <4.8 kbit/sec): codificatori 'analysis by sinthesis' (analisi per sintesi).
I vari codificatori differiscono tra loro solo per il modo in cui è modellata l' eccitazione. Prima di approfondire uno dei vari codificatori, è opportuno descrivere la struttura di base di questa classe di codificatori.
La prima parte è formata da un filtro di sintesi a soli poli come per il codificatore vocale LPC, spesso chiamato filtro a correlazione a breve termine poiché i coefficienti vengono calcolati predicendo un campione tramite i suoi precedenti (8-16 campioni). Il filtro può anche includere un filtro a correlazione a lungo termine in cascata, che modella le variazioni veloci dello spettro.
La seconda parte del modello è il generatore di eccitazione che produce appunto il segnale di eccitazione.
L'efficienza del codificatore descritto sta nella procedura di ottimizzazione a ciclo chiuso: la predizione residua è quantizzata minimizzando l'errore pesato tra il segnale originario e quello ricostruito, piuttosto che minimizzare l'errore tra la parte residua e la sua versione quantizzata, come viene fatto a ciclo aperto.
La terza parte del modello sta nel criterio usato nella minimizzazione dell'errore. Il criterio più comune è quello del minimo errore quadratico medio, qui invece l'errore passa attraverso un filtro che modella lo spettro del rumore, in modo da concentrarne la potenza alle frequenze centrali dello spettro del segnale vocale, mascherando così il rumore.

Decoder

Fig.2 Schema generale del codificatore LPC 'analysis by sinthesis'.
Premessa
Si è visto quindi che si riesce a modellare bene il segnale vocale se si forniscono in ingresso modelli pseudocasuali (excitation generator) e se si utilizza un modello AR per il filtro di sintesi che lega l'uscita all'ingresso attuale e ai campioni delle uscite precedenti. Il filtro di sintesi dà al modello lo spettro simile a quello del segnale vocale . Si può dire che in circa 10 ms il sistema sia stazionario. In pratica, i parametri del modello equivalente sono aggiornati in maniera ciclica ed iterativa ogni 20-25 ms, corrispondenti a 160-200 campioni (essendo 8 kHz la frequenza di campionamento del segnale vocale telefonico con banda convenzionale pari a 4 kHz).
La minimizzazione dell'errore infine porterà a scegliere la sequenza di eccitazione e i coefficienti del filtro. In ricezione si riproduce il segnale sintetico attraverso i coefficienti del filtro e il modello scelto.
La voce ha una marcata correlazione tra campioni vicini , ma è presente anche una correlazione tra campioni distanti (80-120 periodi di campionamento); per questo motivo si fa uso di un predittore a breve termine e di uno a lungo termine. Pertanto si usano due modelli AR in cascata ( a breve e a lungo termine) come filtro di sintesi.
Lo sviluppo spettrale di un segmento di parlato formato da un certo numero di campioni può essere approssimato con la funzione di trasmissione di un filtro digitale a soli poli.
Il filtro a soli poli (AR) è
dove il predittore è definito
p è l'ordine del predittore e il numero dei coefficienti ak del predittore.
L'idea di base è che un campione può essere approssimato da una combinazione lineare di campioni precedenti;il segnale predetto è
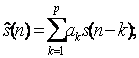
Si definisce l'errore
Passando alla trsformata z:
![]()
dove il filtro
è definito filtro dell'errore di predizione He(z). Il filtro inverso dell'errore di predizione, determinato dall'equazione alle differenze (con ingresso w(n))
![]()
è detto modello AR a breve termine della serie .
Per caratterizzare il modello AR a breve termine H(z) è necessario trovare tutti i valori dei coefficienti ak che minimizzano l'errore di predizione ai minimi quadrati su un piccolo segmento di parlato.
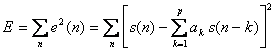
per trovare i
coefficienti ak che minimizzano E, si impone che la derivata di E rispetto ai
coefficienti ![]() con i =1,..,p sia uguale a
0.
con i =1,..,p sia uguale a
0.
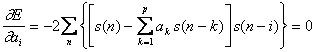
da cui
![]()
cambiando l'ordine delle sommatorie si ha
![]() i =1,.,p
i =1,.,p
Se si definisce
![]() ,
,
l'equazione può essre scritta come
![]() , i =1,.,p
, i =1,.,p
Per trovare i
coefficienti ![]() bisogna risolvere il
sistema di p equazioni in p incognite .
bisogna risolvere il
sistema di p equazioni in p incognite .
Per prima cosa si
cerca di calcolare ![]() con i =1,..,p e con k
=0,..,p, ma si deve specificare il limite della sommatoria. Dalle
considerazioni svolte sui limiti della sommatoria emergono vari metodi tra cui il
metodo dell'autocorrelazione.
con i =1,..,p e con k
=0,..,p, ma si deve specificare il limite della sommatoria. Dalle
considerazioni svolte sui limiti della sommatoria emergono vari metodi tra cui il
metodo dell'autocorrelazione.
Riprendendo
l'equazione ![]() , si è assunto che n possa
variare in un intervallo infinito.Dato che ciò non è possibile in pratica, si
assume che n vari tra 0 e L-1, dove L è la lunghezza del tratto analizzato nel
codificatore vocale LPC.
, si è assunto che n possa
variare in un intervallo infinito.Dato che ciò non è possibile in pratica, si
assume che n vari tra 0 e L-1, dove L è la lunghezza del tratto analizzato nel
codificatore vocale LPC.
Da questa considerazione si ha (assumendo l'ipotesi di stazionarietà locale):
![]() con i
=1,.,p e k =0,..,p
con i
=1,.,p e k =0,..,p
ponendo m =n-i
![]()
Si nota che ![]() è
l'autocorrelazione a breve termine di s(m) calcolata in (i-k). Quindi:
è
l'autocorrelazione a breve termine di s(m) calcolata in (i-k). Quindi:
![]()
dove
![]()
Il sistema di p equazioni in p incognite può essere scritto come
![]() i=1,..,p
i=1,..,p
La stessa equazione espressa in forma matriciale è:
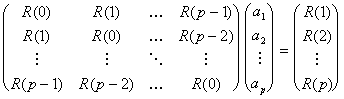
La soluzione più efficiente è la procedura ricorsiva nota come algoritmo di Durbin:
E(0) =R(0)
Per i =1,.,p
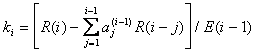
![]()
Per j =1,..,i-1
![]()
![]()
La soluzione finale è data da
![]() j =1,.,p
j =1,.,p
La quantità E(i) è
l'errore di predizione di un predittore di ordine i, i coefficienti ![]() sono
conosciuti come coefficiente coefficienti di riflessione e il loro
valore è compreso tra -1 e 1.
sono
conosciuti come coefficiente coefficienti di riflessione e il loro
valore è compreso tra -1 e 1.
Questa condizione imposta sui coefficienti di riflessione è necessaria e sufficiente affinchè tutte le radici del polinomio A(z) siano nel cerchio unitario. Il metodo dell'autocorrelazione garantisce la stabilità del modello AR H(z).
Il predittore a lungo termine, invece, serve a rilevare la correlazione di pitch; viene infatti spesso definito predittore di pitch, poiché rimuove la periodicità del pitch. Posto in cascata al predittore a breve termine, rende il segnale residuo un processo gaussiano.
Il predittore alungo termine è essenziale nei codifiacatori a basso bit-rate, come ad esempio nel CELP, dove il segnale d'eccitazione è modellato da un processo Gaussiano; infatti la presenza del predittore di pitch deve assicurare che la predizione residua sia molto simile a un processo Gaussiano.
La forma generale di un predittore a lungo termine è:

dove il predittore a lungo termine è:
![]()
che definisce l'errore di predizione:
![]()
Il filtro inverso dell'errore di predizione a lungo termine, determinato dall'equazione alle differenze (con ingresso w(n)):
![]()
è detto modello AR a lungo termine della serie .
I parametri ![]() e
vengono determinati minimizzando l'errore minimo quadrato residuo dopo i 2
predittori su un periodo di N campioni.
e
vengono determinati minimizzando l'errore minimo quadrato residuo dopo i 2
predittori su un periodo di N campioni.
La soluzione del problema è del tutto analogo al caso precedente, dato che si basa sul metodo dell'autocorrelazione ( assunta la stazionarietà locale della serie osservata).
La sola differenza
formale consiste nel fatto che l'indice i varia tra ![]() ed
ed ![]() ,
essendo in genere
,
essendo in genere ![]() .
.
Allora il sistema di ![]() equazioni
in
equazioni
in ![]() incognite
può essere scritto come:
incognite
può essere scritto come:
![]()
![]() per i =
per i = ![]()
ovvero, in forma matriciale:
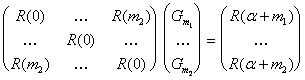
![]()
che è facilmente invertibile per lunghezza ridotta del predittore a lungo termine.
Infatti, in genere ![]() alfa
varia tra 80 e 120, mentre k=-1, 0, 1 o addirittura k=0 (un solo coefficiente).
alfa
varia tra 80 e 120, mentre k=-1, 0, 1 o addirittura k=0 (un solo coefficiente).
Come già detto, il predittore a lungo termine è essenziale per rimuovere la ridodanza del segnale vocale in molti codificatori tra cui il CELP.
Come detto, la cascata di due modelli AR (uno a breve termine e uno a lungo termine) è utilizzabile come filtro di sintesi per riprodurre il segnale vocale.
La codifica CELP presenta lo stesso schema dei codificatori 'analysis by sinthesis' , in cui il segnale residuo dopo i predittori a breve e a lungo termine diventa gaussiano (noise-like),e si assume che possa essere modellato con un processo Gaussiano con spettro di potenza lentamente variabile nel tempo. Nella codifica CELP un tratto di eccitazione di 5 ms (40 campioni) è modellato da un vettore Gaussiano scelto in un codebook, libro di codice, minimizzando l'errore pesato tra il segnale originario e quello sintetizzato. In genere un codebook ha 1024 righe, ossia 1024 sequenze formate da 40 campioni ciascuna e la sequenza ottima in ingresso al filtro di sintesi vieni scelta dopo una lunga ricerca nel codebook.
Nel CELP si utilizza la quantizzazione vettoriale, ossia si assegna lo stesso indice (in questo caso la stessa sequenza di eccitazione) a un gruppo di punti vicini nello spazio N-dimensionale, che rappresentano segnali con caratteristiche simili.
La sequenza di innovazione ottima viene scelta in un codebook stocastico che contiene sequenze bianche gaussiane, minimizzando l'errore tra il segnale originario e quello sintetizzato.
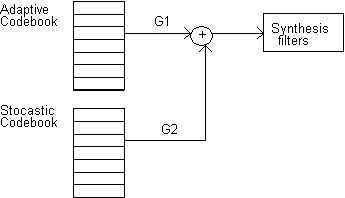
Fig.3 Schema della codifica CELP.
La correlazione di pitch è qui sostituita da un codebook adattativo.
Trasmettendo quindi solo i bit che codificano gli indirizzi delle parole di codice (una estratta dal codebook adattativo e l'altra da quello stocastico), i rispettivi guadagni ed i campioni del filtro si inviano tutte le informazioni necessarie alla ricostruzione del segnale. In ricezione, avendo a disposizione gli stessi codebook, si risale facilmente al segnale sintetizzato, ottenuto facendo passare il segnale di eccitazione determinato nel filtro di sintesi LPC. Il CELP permette quindi di codificare con pochissimi bit (bassa occupazione di banda) un qualsiasi segnale audio a scapito di un aumento di complessità dell'algoritmo di codifica.
Si riesce a codificare un frame di eccitazione (5-7.5 ms) con soli 15 bits; infatti 10 bits costituiscono l'indirizzo del codebook che individua la sequenza d'eccitazione scelta, 5 bits per codificare il guadagno. Per codificare la stessa eccitazione nel codificatore GSM RPE-LTP occorrono ben 47 bits. Aumenta però il numero di operazioni da fare per trovare il modello che meglio approssima il segnale originale: ogni sequenza va infatti convoluta con il filtro e poi si paragonano i possibili segnali sintetizzati con quello originale e si sceglie quello che dà l'errore più piccolo; ad esempio per un codebook di 1024 righe e un frame di eccitazione di 40 campioni sono richieste circa 40000 moltiplicazioni per campione per trovare il codebook.
Al fine di ridurre la complessità computazionale della codifica CELP si ricorre ad alcuni codebooks strutturati in modo da semplificare le procedure.
Tra i vari metodi è opportuno descrivere brevemente i codebook a eccitazione sparsa, i codebook ternari e i codebook a sovrapposizione.
Nei codebook a eccitazione sparsa la maggior parte degli impulsi nel vettore di eccitazione vengono posti a zero; ciò viene fatto tagliando i campioni al centro, e per popolare il codebook viene utilizzato un processo gaussiano a media nulla e varianza unitaria e le variabili casuali vengono poste a zero quando il loro valore assoluto si trova sotto una specifica soglia. Si è visto che in un tratto di 5 ms bastano 4 impulsi per rappresentare il segnale di eccitazione, ma quando il suono è sonoro ne bastano meno e porre la maggior parte dei campioni nel segnale residuo a zero non modifica la qualità del segnale. Dato che gli impulsi nel vettore di eccitazione non sono ottimizzati è preferibile usare vettori a eccitazione sparsa in caso di segmenti di suoni sonori.
D'altro canto in presenza di suoni sordi è preferibile utilizzare vettori di eccitazione stocastici non sparsi. Da alcune simulazioni si è visto che utilizzando 4 impulsi non nulli in un vettore di 40 campioni dà gli stessi risultati di una codifica CELP originale in cui l'intero vettore di eccitazione è un processo Gaussiano.
Il metodo dei codebook ad eccitazione sparsa può essere ancor più semplificato usando vettori ternari: un vettore ad eccitazione ternaria è un vettore ad eccitazione sparsa in cui gli impulsi non nulli vengono posti a -1 e 1. Come nel caso precedente i codebooks ternari possono essere tagliati al centro e popolati con un processo Gaussiano random dove le variabili casuali vengono poste a zero se il loro valore cade sotto una certa soglia, altrimenti la variabile è posta a -1 o -1.
Un ultimo efficiente metodo è quello dei codebook a sovrapposizione e può anche essere combinato con gli altri due metodi. Ogni parola di codice è ottenuta shiftando la parola di codice precedente di k campioni e aggiungendo k campioni nuovi. Così 2 parole di codice adiacenti hanno solamente k campioni differenti. Il primo vantaggio di questi codebooks è la riduzione della memoria richiesta. Per un codebook di lunghezza L con vettori di dimensione N, devono essere immagazzinati N+k*(L-1) campioni. Un secondo vantaggio altrettanto importante è la riduzione del carico computazionale richiesto per una ricerca ottima del codebook.
La codifica Celp utilizza un bit-rate che va dai 4.8 agli 8 kbit/sec.
Fa parte invece dei codificatori di forma d'onda lo standard MP3, algoritmo che implementa moderne tecniche di percezione sonora dell'apparato uditivo umano per raggiungere un'elevata compressione dei dati senza una percettibile perdita di qualità. Lo standard è stato studiato dall' MPEG (Motion Picture Expert Group) e stabilisce la sintassi e i metodi di compressione a basso bit-rate per audio e video per riuscire a comprimere il segnale così tanto da permettere l'invio di dati su canali di trasmissione lenti.
L'algoritmo layer III è attualmente il più efficiente in termini di maggiore compressione per la stessa qualità, ma questa efficienza viene pagata in termini di una maggiore complessità dell'algoritmo di codifica e quindi maggior tempo di codifica.
L'algoritmo di compressione MP3 è stato disegnato appositamente per gestire file audio che hanno determinate caratteristiche statistiche; infatti è possibile trovare ad esempio in un brano musicale una certa correlazione più o meno marcata tra campioni vicini, sintomo di ridondanza statistica che può essere eliminata utilizzando particolari codifiche (predizione lineare, codifica di Huffman..) che senza modificare il segnale audio permettono di avere una buona compressione.
In verità la vera potenza degli algoritmi MPEG di compressione audio è determinata dall'utilizzo di altri metodi di codifica che applicano una compressione con perdita di dati. L'algoritmo calcola mediante precise tabelle su cui è descritta la percezione del sistema uditivo umano, le parti di informazione audio che, seppur presenti, non vengono fisicamente percepite dall'orecchio. I suoni che non risultano udibili a causa dell'adattamento dinamico della soglia di udibilità vengono detti mascherati. L'udito non si può modellare con un filtro lineare, perché riesce a percepire bene solo in determinate bande critiche. Si comporta come un banco di filtri passa- basso, con bande di ampiezza tra i 50 Hz e i 5 KHz. Le bande di questo banco di filtri si sovrappongono,un modello potrebbe avere 26 bande che coprono 24 KHz udibili.
Grazie a questa struttura, può verificarsi il fenomeno della mascheratura simultanea.
La mascheratura nel dominio della frequenza avviene tra due segnali vicini in frequenza più della risoluzione in frequenza dell'udito umano; esiste quindi una soglia di mascheratura sotto la quale i segnali sono udibili.Vanno perciò eliminate dallo spettro in frequenza quelle righe per cui si ha un'ampiezza piccola rispetto ad ampiezze molto più grandi a frequenze vicine. Il segnale ricostruito dal decodificatore conserverà le caratteristiche fondamentali del segnale stesso. Esiste anche una risoluzione temporale dell'orecchio umano, sotto la quale non si riescono a distinguere due suoni, ed inevitabilmente si sente solo il più forte.
Scendendo un po' più nei particolari, di seguito vengono riportati i passi che l'algoritmo di codifica MPEG esegue sui dati audio:
Decomposizione in sotto-bande mediante un banco di filtri polifase
Il segnale audio a banda larga viene decomposto in 32 sottobande mediante uno pseudo-filtro QMF (Quadrature Mirror Filter) implementato con la cascata di una struttura polifase e di una DCT.
Per aumentare la risoluzione in frequenza , il layer III decompone ognuna delle 32 sottobande in un massimo di 18 ulteriori sottobande equispaziate. La maggiore risoluzione in frequenza offre un aumento del guadagno della codifica, però crea anche una fastidiosa perdita di risoluzione temporale, percui le sottobande vengono ridotte fino a 6.
Calcolo dei parametri del modello psicoacustico mediante una FFT
Sono stati studiati 2 modelli psicoacustici per lo standard MPEG1, uno utilizzato dagli algoritmi I-II, l'altro dal layer III.
Allocazione dinamica dei bit con riferimento ai parametri del modello psicoacustico
Si cerca di determinare il minimo numero di bit necessario per codificare le singole sottobande, in modo che non ne venga variata la percezione.
Quantizzazione e codifica dei segnali in sotto-bande
La quantizzazione è fatta per ogni sottobanda, utilizzando esclusivamente i bit che sono stati allocati per essa.
Multiplex e impaccaggio dei frame
Una prima compressione viene effettuata mediante la ricerca e l'analisi delle bande di frequenza critiche e delle soglie assolute.
L' apparato uditivo umano analizza i segnali a banda larga nelle cosiddette bande critiche. Lo scopo di questa analisi è quello di decomporre il segnale audio in sotto-bande (le bande critiche) e poi quantizzare e codificare questi segnali sottobanda. Dato che la percezione dei suoni sotto la soglia assoluta non è possibile, i segnali sotto-banda che si trovano sotto questa soglia non vengono né codificati né trasmessi.
In ogni banda critica la differenza tra il livello del segnale e la soglia assoluta è responsabile per la scelta dei passi di quantizzazione appropriati per ogni banda critica.
Nella seconda fase della compressione vengono sfruttati gli effetti del mascheramento che l'apparato uditivo umano applica ai segnali.
Per un rumore a banda limitata, oppure un segnale sinusoidale, sono state ricavate le soglie di mascheramento dipendenti dalla frequenza; queste soglie effettuano un mascheramento di quelle frequenze che hanno ampiezza minore di esse.
L'algoritmo layer III è attualmente il più potente e raggiunge rapporti di compressione elevatissimi da 1:10 fino a 1:12 senza variare la qualità del suono.
Per un segnale stereo, una tale compressione corrisponde a una velocità di tyrasmissine da 128 fino a 112 kbit per secondo.
Alcuni dati mostrano quanto si risparmia in termini di occupazione di memoria a discapito della qualità del suono con lk'algoritmo layer III:
|
Sound quality |
bandwidth |
mode |
bitrate |
reduction ratio |
|
Telephone sound |
2.5 kHz |
mono |
8 kbps |
|
|
better than shortwave |
4.5 kHz |
mono |
16 kbps |
|
|
Better than AM radio |
7.5 kHz |
mono |
32 kbps |
|
|
Similar to FM radio |
11 kHz |
stereo |
56..64 kbps |
|
|
Near CD |
15 kHz |
stereo |
96 kbps |
|
|
CD |
>15 kHz |
stereo |
112..128 kbps |
|
Il formato MP3 è correntemente usato in alcune applicazioni che dispongono di poche risorse (in termini di banda e memoria): collegamenti audio tramite isdn, radio digitale via satellite, audio su internet,etc.
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2025