|
|
| |
APPUNTI DI STATISTICA SPERIMENTALE
UNITA' STATISTICA - sono i soggetti descritti tramite uno insieme di dati.- possono essere persone, cose ed animali-
categorica - colloca una unità in una tra diversi gruppi i in una diversa categoria.
Quantitativa - assume valori numerici su cui è possibile effettuare operazioni aritmetiche quali somma o media.
La curva tracciata sopra i tetti di un istogramma è un'ottima rappresentazione per l'andamento generale dei dati.
Essa si trova sempre sopra o sull'asse orizzontale e l'area sotto di essa è esattamente pari ad 1. La curva di densità rappresenta il modello complessivo di 1 distribuzione e se assume una forma ben precisa è spesso in grado di rappresentare adeguatamente l'andamento generale della distribuzione. I valori estremi o deviazioni rispetto al modello generale non vengono rappresentati dalla curva.
Dalla Curva di densità possiamo misurarne il suo centro e la sua dispersione, attraverso la rappresentazione della MEDIANA, QUARTILI E DEVIAZIONE STANDARD.
La mediana di una curva di densità Simmetrica si trova al centro della curva.
Media e Mediana sono identiche quando si ha una curva
simmetrica, mentre se la curva e asimmetrica
I QUARTILI di una curva di densità dividono l'area in 4/4, pertanto avremo ¼ dell'area sotto la curva a sx del 1 quartile e ¾ dell'area sono a sx del 3 quartile.
ANALISI DELLE DISTRIBUZIONI NORMALI
Quando le curve di densità hanno un solo picco e sono a forma di campana, vengono denominate CURVE NORMALI rappresentando così le Distribuzioni Normali.
La curva di densità di una DISTRIB. NORMALE si ottiene dando la sua (Media μ) e la deviazione standard (σ ).
La deviazione standard controlla la variabilità di una Curva normale, pertanto se abbiamo un valore alto di dev. Standard la curva tenderà ad appiattirsi sull'asse orizzontale diventando più larga e bassa, mentre se il valore della dev. Standard tende a scendere avremo un innalzamento della curva diventando più stretta ed alta
Le Curve normali sono importanti in statistica perché :
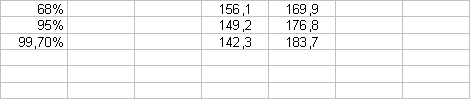
Tutte le Distribu. Normali obbediscono alla regola 68-95-99,7, ossia quando facciamo un'osservazione dobbiamo vedere se essa è compresa nell'intervallo
( μ - σ ) (μ + σ )
( μ - 2σ 242c25c ) (μ + 2σ )
( μ - 3σ ) (μ + 3σ )
Es: la distrib. Delle altezze delle donne fra i 20 ed i 29 anni è
approssimativamente Normale con Media CM. 163 e deviaz.standard
In quale intervallo simmetrico rispetto alla media cade il 95% delle altezze delle donne? L'intervallo corrisponde ai valori 149,2 - 1756,8
Quale percentuale delle donne supera i
Tutte le distribuzioni Normali sono identiche quando le rilevazioni vengono trasformate in scale standardizzate, ossia quando andiamo a sottrarre al valore, la media della distribuzione e poi dividere lo scarto risultante per la sua deviazione standard.
Il Valore z viene così rappresentato z = x - μ ci informa su quante deviazioni
σ
Standard l'osservazione originaria è distante dalla media ed in quale direzione.
Le osservazioni maggiori della media sono positive, mentre quelle minori della media sono negative.
La distribuzione viene definita Normale Standard quando assume valori N(0,1) con media 0 e deviazione standard 1.
Dato che tutte le distribuzioni Normali sono identiche una volta standardizzate, è possibile trovare le aree al di sotto di qualsiasi curva standardizzata da una singola tavola che riporti le aree al di sotto della curva per la distribuzione Normale standard.
Es: quale è la proporzione delle donne alte meno di cm 178?
Distribuzione N ( 163, 6,9)
Z= x - μ ossia z = 178 - 163 / 6,9 = 2,17 → questo valore ci indica che
l'area che vogliamo trovare sotto la curva normale standard è a sx del valore 2,17 - con la tabella A troviamo la superficie che corrisponde all'area 0,9850.
Possiamo anche DESTANDARDIZZARE UN RISULTATO Z
X = μ + σz ossia x = 163 + 6,9*2,17
X = 163 + 14,97 = 177,97 arrotondato a 178
La curva di densità è una curva che si trova sempre sopra o sull'asse dell'ascisse e l'area sotto di essa è sempre pari al valore 1.
Le aree sotto la curva rappresentano delle proporzioni rispetto al numero totale di osservazioni.
La curva di densità è una rappresentazione idealizzata della distribuzione dei dati, quindi è bene distinguere fra media / deviazione standard di una curva di densità e media e deviazione standard calcolata con i dati osservati.
Si parla di CURVA NORMALE quella curva di densità cha ha 1 singolo
picco ed è a forma di campana. - la curva normale rappresenta
Tutte le distribuzioni Normale obbediscono alla regola " 68-95-99,7 " - questo rappresenta la percentuale delle o sservazioni che si trovano entro 1 - 2- 3
Deviazioni standard dalla Media
Tutte le distribuzioni Normali hanno in comune alcune proprietà, tutte possono essere ricondotte ad una sola, attraverso il processo di standardizzazione.
Z = X - μ / σ
Z positivo = osservazioni > media
Z negativo = osservazioni < media
DIAGRAMMA A DISPERSIONE E CORRELAZIONE - Capitolo 4 -
Per studiare una relazione fra 2 variabili occorre misurarle entrambe entro lo stesso insieme di unità. Spesso 1 delle 2 variabili può spiegare ed influenzare l'altra.
Per fare una previsione dobbiamo comunque identificare la variabile esplicativa e la variabile di risposta.
La relazioni fra 2 variabili quantitative può essere rappresentata graficamente attraverso il Diagramma a dispersione. Sull'asse orizzontale vanno inseriti i valori della variabile indipendente mentre sull'asse verticale vanno inseriti i valori relativi alla variabile di risposta.
L'andamento Generale del diagramma a dispersione viene descritto
attraverso
I valori estremi o OUTLIER che non seguono l'andamento generale della relazione sono importanti tipi di deviazioni dal modello complessivo.
Se i punti sono sparsi nel diagramma assumendo forme quasi circolare non sussiste relazione, se i punti si estendono dall'angolo in basso a dx verso l'angolo in alto a sx, allora abbiamo una relazione negativa.
Possiamo dire che una relazione lineare è FORTE se i punti all'interno del diagramma di dispersione si trovano vicini ad una retta. La relazione è DEBOLE se i punti sono piuttosto dispersi dalla retta.
R = 1 / (n-1) * sommatoria di Zx * Zy
Il coefficiente R non ha un'unità di misura in quanto esso è un numero puro ed è comprese sempre tra -1 e 1
Se R si sposta da
Valori estremi R=1 e R= -1 indicano che la relazione lineare è perfetta e che i punti si trovano esattamente lungo una linea retta.
R non è una misura robusta - ossia essa varia fortemente quando intervengono valori estremi/outlier.
l I RESIDUI sono le differenze fra i valori osservati della variabile di risposta T ed i valori previsti dalla retta di regressione.
Residuo = Y osservata - Y previsto
L' OUTLIER è quell'osservazione che non segue il modello generale assunto dalla maggior parte delle osservazioni. I punti che possiamo considerare outlier in direzione della variabile Y hanno residui elevati.
OSSERVAZIONE INFLUENTE è quell'osservazione che se eliminiamo cambierebbe profondamente il risultato. I punti che possiamo considerare outlier in direzione della variabile X sono spesso i punti influenti nella direzione della retta di regressione dei minimi quadrati.
La retta di regressione può descrivere l'andamento generale di una relazione lineare, sintetizzando le relazioni fra 2 variabili sul grafico.
La retta descrive come cambia una variabile DIPENDENTE - Y- quando cambia la variabile INDIPENDENTE - X -.
La retta di regressione dei minimi quadrati è la linea retta che rende minima la somma dei quadrati delle distanze verticali tra i punti osservati e la retta stessa.
Y a cappello = a + bx dove a = intercetta o asse orizzontale X -
B = coefficiente angolare di una retta o gradiente - essa descrive la pendenza della retta di regressione rispetto all'asse delle ascisse.
Per calcolare Y a cappello prima bisogna trovare il valore del coefficiente angolare b:
b = correlazione R che moltiplica deviazione standard Y / deviazione standard X
b = r * Sy / Sx
a = media di Y meno ( coefficiente b moltiplicato per la media di X )
a = my - ( b*mx)
per disegnare la retta di regressione sul diagramma si utilizza l'equazione per trovare i valori di Y a cappello in corrispondenza dei 2 valori di X, prossimi agli estremi dei dati di X.
Le proprietà che caratterizzano la retta di regressione dei minimi quadrati sono:
R al quadrato = variabilità in Y a cappello quando la variabile X la spinge sulla retta
Variabilità totale nei valori osservati di Y
IL CAMPIONAMENTO - capitolo 7 -
L'analisi esplorativa dei dati cerca di individuare e descrivere ciò che i dati dicono, attraverso grafici ed indici numerici, ed i risultati che si ottengono riguardano solamente l'insieme dei dati preso in esame.
l Studio osservazionale consiste nell'osservare le unità e misurarne le variabili di interesse, ma non si cerca di influenzarne le risposte. Le indagini campionarie fanno parte dello studio osservazionale.
l Si parla di studio sperimentale quando si sottopongono le unità deliberatamente ad alcuni trattamenti al fine di osservarne le reazioni provocate. Se vogliamo capire il rapporto di causa/effetto, gli esperimenti sono le uniche fonti attendibili dei dati.
i campioni scelti tramite campioni volontari o per convenienza non rappresentano l'intera popolazione, questi metodi sono distorti e contengono errori sistematici che favoriscono alcuni sottoinsiemi di popolazione.
Il campione casuale semplice - CCS - quando un campione viene scelto casualmente non è possibile favorire l'inserimento di unità rispetto ad altre.
Scegliendo un ccs si annullano le distorsioni dando a tutte le unità la stessa probabilità di essere scelte e la stessa probabilità di essere estratte.
Per estrarre un campione, bisogna etichettare le unità statistiche assegnando loro un numero con il minor numero di cifre, ed utilizzando la tavola dei numeri casuali ( lunga sequenza di cifre 1,2,3,4,5,6,7,8,9,.) partendo da un punto qualsiasi della tavola si leggono le cifre a gruppi e si estrae la sequenza dei campioni che ci interessa.
Campione probabilistico - CP- è un campione scelto a caso, per ottenerlo è necessario conoscere quali campioni sono possibili e che probabilità ha ogni campione di essere estratto. Il principio essenziale per il campionamento statistico è l'uso della casualità nella selezione del campione.
Campione casuale stratificato - CCSP - questo processo viene messo in atto quando la popolazione è molto ampia oppure si estende su una vasta zona. E necessario innanzi tutto suddividere la popolazione in gruppi di unità il più possibile omogenei denominati STRATI, poi per ogni strato viene scelto un CCS ed infine si uniscono tutti i CCS derivati dagli strati formando un unico campione.
Il CCST può fornire informazioni più precise di un CCS in quanto tiene conto della omogeneità delle unità facenti parte dello stesso strato.
Si è detto che la selezione casuale elimina le distorsioni nella scelte di un campione, ma per avere questi dati è necessario avere l'elenco completo ed accurato delle unità. Ma tale lista di solito non omai disponibile e per questo motivo la maggior parte dei disegni campionari soffre già in partenza di un errore di copertura . Ossia quando alcuni gruppi di una popolazione vengono tralasciati dal processo di selezione del campione.
Altro fattore di distorsione è la mancata risposta ossia quando l'unità scelt per il campione non può essere raggiunta o si rifiuta di rispondere.
Altre distorsioni di risposta possono essere causate sia dagli intervistatori, sia dagli intervistati, infatti che risponde può non dire la verità oppure esagerare nelle risposte.
E' importante quindi prestare molta attenzione durante le interviste al fine di ridurre al massimo le distorsioni.
Anche la formulazione della domanda può influire nelle risposte in modo determinante.
Dobbiamo ricordarci che è impossibile che i risultati di un campione coincidano perfettamente con quelli dell'intera popolazione, ma il fatto più importante è che le stime che otteniamo con un campione casuale anche se cambiano da campione a campione obbediscano alle leggi della probabilità. Possiamo quindi quantificare l'errore che si commette quando si traggono delle conclusioni sulla popolazione, sulla base di un campione.
I campioni casuali più grandi offrono risultati più precisi dei campioni meno numerosi, quindi possiamo essere certi che il risultato ottenuto si avvicina molto alla verità della popolazione.
GLI ESPERIMENTI - capitolo 8 -
Una ricerca diventa un esperimento quando si sottopongono persone,cose
ed animali ad un trattamento con lo scopo di osservare
Si parla di SOGGETTI le unità oggetto dello studio sperimentale
Si parla di FATTORI sono le variabili Esplicative/ indipendenti
Si parla di TRATTAMENTO quando ai soggetti viene applicata una qualsiasi condizione sperimentale.
in un esperimento è possibile evitare l'effetto di CONFONDIMENTO quando i soggetti vengono assegnati casualmente ai trattamenti, controllandone anche le condizioni a cui sono sottoposti in modo da mantenere costante l'influenza dei fattori che non interessano.
Un vantaggio degli esperimenti è la capacità di studiare gli effetti di più fattori contemporaneamente.
ESPERIMENTI COMPARATIVI = gli esperimenti che si svolgono nei laboratori hanno un disegno molto semplice. Somministrare il trattamento ai soggetti ed analizzare la risposta.
In laboratorio si cerca di limitare l'effetto di confondimento attraverso il controllo delle condizioni ambientali dell'esperimento e l'unica cosa che influenza la variabile di risposta sono i fattori di interesse. Ma al di fuori del laboratorio abbiamo le variabili nascoste che creano quasi sempre confondimento e per evitarle debbono essere condotte con un gruppo di controllo.
Disegnando un esperimento bisogna sempre descrivere le variabili di risposta, i fattori e la struttura dei trattamenti servendosi sempre del confronto come principio guida dell'esperimento. Il confronto ha effetto solo se viene somministrato a gruppi simili di unità-
PRINCIPI GENERALI DEL DISEGNO DEGLI ESPERIMENTI :
Si parla di SIGNIFICATIVITA' STATISTICA quando un qualsiasi effetto osservato è di entità grande da non poter essere spiegato facilmente ricorrendo al caso.
ESPERIMENTO IN DOPPIO-CIECO - si ha quando né i soggetti né lo staff che lavora a contatto con loro sanno quale tipo di trattamento ciascun soggetto riceve.
La mancanza di realismo può inficiare la validità de un esperimento inducendo a non estendere i risultati ottenuti alla popolazione di riferimento.
DISEGNI PER DATI APPAIATI - si usa nel disegno statistico per avere risultati più precisi con confronto solo fra 2 trattamenti.
- si scelgono 2 soggetti il più simili possibile, ad uno scelto casualmente viene somministrato un trattamento mentre al restante si somministra l'altro.
Qualche volta la coppia appaiata è costituita da un solo soggetto che ha ricevuto entrambi i trattamenti, quindi ciascun soggetto è anche il proprio elemento di controllo.
DISEGNO A BLOCCHI - un blocco è un insieme di soggetti simili rispetto ad un fattore di cui si vuole verificare l'influenza sulla variabile di risposta.
Nel disegno a blocchi l'assegnazione dei soggetti ai trattamenti casuale ed è fatta in modo separato per ciascun gruppo.
Nel disegno a blocchi è possibile trovare conclusioni separate per ciascun blocco.
E' proprio grazie all'inserimento dei blocchi che è possibile eliminare le differenze sistematiche tra blocco e blocco, guadagnando in termini di precisione della risposta totale.
Concetto base sella statistica è quello di utilizzare il risultato di un campione per stimare un aspetto dell'intera popolazione. I campioni casuali tendono ad annullare le DISTORSIONI dovute alla scelta del campione, ma possono dare anche risposte non del tutto esatte a causa della variabilità dovuta alla loro estrazione casuale.
Per capire come sia possibile fidarsi dei campioni casuali e degli esperimenti randomizzati, dobbiamo studiare il comportamento del caso.
Il comportamento del caso è imprevedibile a breve termine ma rivela un modello regolare e prevedibile a lunga scadenza.
La probabilità descrive cosa succede a lungo termine ed è necessario analizzare molte ripetizioni di uno stesso esperimento prima di poter dire che un certo risultato so verifica con una certa probabilità.
Che differenza c'è tra casualità e probabilità?
un esperimento casuale è un esperimento il cui evento è incerto, ma ripetendo l'esperimento un elevato numero di volte, la distribuzione assume una forma regolare.
la probabilità di un risultato di un esperimento è la proporzione di volte in cui tale risultato ricorre in una lunga serie di ripetizioni.
IL modello probabilistico è composto dallo Spazio Campionario (S), ossia dall'insieme di tutti i possibili risultati.
L'evento, il risultato o un insieme di risultati di n esperimento casuale.
Quindi il modello probabilistico è una descrizione matematica di un esperimento casuale. Es. quando lanciamo una moneta abbiamo solo 2 risultati, testa o croce quindi lo spazio campionario è S ( T.C.)
Per poter rappresentare matematicamente la probabilità dobbiamo prima definirne le proprietà, ossia la probabilità devono sottostare a delle regole:
qualsiasi probabilità è un numero compreso tra 0 ed 1. - O < P < 1
Un evento con probabilità 0 - non si verifica mai
Un evento con probabilità 1 - si verifica in ogni ripetizione dell'esperimento.
Un evento con probabilità 0,5 - ricorre nel lungo periodo in metà delle prove.
Tutti i possibili risultati devono avere nell'insieme provabilità pari ad 1.
P (S) = 1 in ogni prova si verifica un risultato e la soma deve essere esattamente pari ad 1.
La probabilità che un evento non si verifichi viene rappresentata da
1 - meno la probabilità che l'evento si verifichi.
P (A) = 1 - P(A)
Se due eventi non hanno in comune risultati, la probabilità che uno o l'altro so verifichi è pari alla somma delle loro probabilità singole.
P( Ao B) = P(A) + P(B)
se A è un evento qualsiasi , la sua probabilità si scriverà P (A) -
Con il termine di VARIABILE CASUALE andiamo ad identificare il risultato numerico di un esperimento casuale.
La distribuzione di probabilità di una variabile ( X) ci dice quali valori essa può assumere e come assegna la probabilità a questi valori.
Le variabili casuali sono quelle che derivano da un campione casuale e si distinguono in due categorie:
CONTINUE - quando la variabile assume qualsiasi valore compreso tra un qualche intervallo numerico.
DISCRETE - quando essa assume un numero finito di valori.
Si parla di PROBABILITA' SOGGETTIVA di un evento quando abbiamo un numero compreso fra lo 0 ed 1 che esprime il giudizio di un individuo circa il verificarsi dell'evento. Esso varia la persona a persona e quindi non può essere definito né giusto e né sbagliato.
DISTRIBUZIONE CAMPIONARIA - capitolo 10 -
Quando si utilizzano i dati è bene chiarire se questi si riferiscono all'intera popolazione o ad un campione estratto da questa.
Con il termine PARAMETRO si vuole identificare quel valore che descrive la popolazione. Di solito è un valore incognito in quanto non è possibile esaminare l0intera popolazione.
Con il termine STATISTICA/o si intende un numero calcolato direttamente sulla base dei dati campionari a ns. disposizione.
Anche nella distr. Campionaria abbiamo la media che può essere suddivisa in:
MEDIA della POPOLAZIONE- identificata con il simbolo μ . E' un
parametro fisso ed è incognito quando si utilizza 1 campione per fare inferenza.
La media campionaria è la stima della media della popolazione-
Il termine di Inferenza statistica è l'utilizzo di dati campionari per arrivare a conclusioni che riguardano l'intera popolazione.
Poiché un Campione Casuale Semplice dovrebbe essere rappresentativo della popolazione, la media campionaria dovrebbe essere abbastanza vicina alla media della popolazione.
Se si aumenta progressivamente l'ampiezza del campione, la statistica(
media campionaria) sicuramente si avvicina sempre più al valore del parametro (
media popolazione). Quindi se aumentiamo progressivamente il campione, la stima
della soglia media diventerebbe sempre più accurata. Questa rappresenta
Per le distribuzioni campionarie si intende i quel modello teorico che risulterebbe se analizzassimo tutti i possibili campioni di numerosità estratti dalla ns. popolazione.
La distribuzione campionaria descrive come varia la statistica X in tutti i possibili campioni della stessa numerosità, estraibili dalla medesima popolazione.
σ/√n ( deviaz. Standard diviso radice quadrata di n).
Le medie campionarie sono meno variabili delle singole osservazioni che compongono il campione.
Se le singole osservazioni hanno Distribuzioni N( μ,σ) allora la media campionaria X di n° osservazioni indipendenti ha distribuzione ( μ, deviaz. Standard diviso radice quadrata di n).
Qual è la forma della distribuzione campionaria di ( media aritmetica) quando la distribuzione della popolazioni non è normale?
Quando la numerosità campionaria aumenta la distribuzione di media cambia forma. Essa sembra molto simile a quella della popolazione e molto più simile a quella della distribuzione normale.
TEOREMA DEL LIMITE CENTRALE -
Consideriamo un CCS di numerosità n° da una popolazione qualsiasi con media μ e deviazione standard σ finita.
Quando n, è elevato la distribuzione campionaria della media campionaria è approssimativamente Normale:
media campionaria è approssimativamente normale N ( μ, σ/√n).
REGOLA DEL PRODOTTO - capitolo
Due eventi A e B sono indipendenti se il verificarsi di uno non modifica il verificarsi dell'altro. Quindi se A e B sono indipendenti otteniamo
P( A e B) = P(A) * P(B) ( regola del prodotto)
Due eventi A e B sono disgiunti quando verificandosi A, B non può verificarsi. Gli eventi disgiunti non possono essere indipendenti.
Quindi si applica la regola della somma
P(A o B) = P(A) + P(B)
Essa può essere applicata anche ad una numerosità maggiore di eventi disgiunti quando nessuna coppia di eventi contiene risultati comuni.
Due eventi A e B non sono disgiunti, quando si possono presentare contemporaneamente. La probabilità che uno o l'altro si verifichi, è minore della somma delle loro probabilità.
Regola generale della somma per 2 eventi qualsiasi.
P( A o B ) = P(A) + P(B) - P(A e B )
È la probabilità che si assegna ad un evento può cambiare sapendo che un altro evento si è già verificato.
La probabilità condizionata di B dato il verificarsi di A è data dalla formula
P(A/B) = P ( A e B )
P(A)
Dove A rappresenta l'informazione di cui disponiamo, B è l'evento ci sui stiamo calcolando la probabilità.
La probabilità condizionata non ha senso se l'evento A non si verifica mai, quindi dobbiamo sempre avere bisogno che la probabilità di A sia sempre maggiore di 0.
Nella P(B/A) l'evento A ci offre delle informazioni aggiuntive riguardo alla possibilità che l'evento B si verifichi.
Delle volte avere l'informazione dell'evento A può non fornirci alcuna informazione circa il verificarsi di B- in questo caso A e B sono indipendenti.
P(B/A) = P(B)
ESPERIMENTO BINOMIALE - CAPITOL0 12 -
I componenti utili in un esperimento binomiale sono:
è una distribuzione di probabilità con il parametro " n" che corrisponde al numero delle osservazioni e " p " che corrisponde alla probabilità che un qualsiasi osservazione sia uguale ad un successo.
La distribuzione binomiale ci consente di valutare ex-ante se la numerosità del campione è sufficiente al calcolo della probabilità.
Esempio coefficiente binomiale : n = 5 osservazioni k= 2 successi
( numero di modi di ottenere K successi su N. osservazioni)
n = n!
k → k!(n-k)
= 5! = 5x4x3x2x1 = 120 = 120 = 10
2! * 3! (2x1) * (3x2x1) 2 * 6 12
il coefficiente binomiale conta il numero di modi differenti in cui K successi si possono presentare tra n. osservazioni.
MEDIA e DEVIAZIONE STANDARD della Binomiale:
Se X ha una distribuzione binomiale con N. osservazioni e P. probabilità di successo in ciascuna prova, la μ e σ di x sono:
μ = n*p Nota bene: Le formule sono valide solo per le
σ = Radice quadrata np(1-p) distribuzioni binomiali.
INTERVALLI DI CONFIDENZA - capitolo 13 -
Tramite i campioni si vuole infatti inferire le caratteristiche principali di tutta la popolazione da cui il campione è stato estratto.
L'INFERENZA STATISTICA definisce le tecniche per avere informazioni riguardanti la popolazione da cui il campione è stato estratto. Essa utilizza il linguaggio probabilistico per valutare il grado di affidabilità delle conclusioni.
Le tecniche più usare per rilevare l'inferenza sono gli INTERVALLI DI CONFIDENZA ed i TESTI DI IPOTESI.
Le condizioni base dell'inferenza statistica sono:
ma l'obiettivo è quello di fare inferenza su tale media della popolazione, sulla base di dati osservati e supponendo di conoscere la deviazione standard della popolazione.
Gli intervalli di confidenza sono composti da due elementi:
Il livello di confidenza C - ci indica la probabilità in cui l'intervallo comprenderà il vero valore del parametro, ripetendo più volte il campionamento - il livello di confidenza è la % di successo dell'operazione.
La superficie sotto la curva di distribuzione viene definita " C " mentre i valori -z* e + z* delimitano tale superficie e vengono definiti valori critici .
- z* C +z* Gli intervalli di confidenza per essere quasi veritieri devono
Essere estratti al 90% 95% 99%-
TAVOLA C -
Gli estremi di ogni intervallo sono : media ± z* che moltiplica deviazione standard/ radice quadrata di n. osservazioni-
Il valore zeta standardizzato moltiplicato per la deviazione standard / radice quadrata di n. osservazioni viene chiamato Margine di errore.
Il margine di errore diventa più piccolo quando:
Se abbiamo il valore critico z che ci assicura un dato livello di confidenza ed un margine di errore già fissato, possiamo trovare il valore di N. osservazioni che risolve l'equazione.
N = ( z* per dev.stand. diviso per il margine di errore stimato)
N. deve essere sempre arrotondato con il numero intero superiore.
TEST DI SIGNIFICATIVITA - CAPITOLO 14 -
I testi di significatività vogliono quantificare l'evidenza fornita dai dati nei confronti di una certa ipotesi riguardante la popolazione.
Per eseguire un test statistico dobbiamo prima di tutto definire attentamente le affermazioni che vogliamo confrontare.
Ipotesi nulla - Ho - è l'affermazione da verificare.
Il test è costruito in modo tale da valutare quanto sia forte l'evidenza fornita dai dati contro l'ipotesi nulla. Ho : μ = 0
Ipotesi Alternativa - Ha - è l'ipotesi per la quale stiamo cercando evidenza empirica a favore
Ha : μ > 0
Le ipotesi Ho ed Ha vanno definite in base ai parametri della popolazione, di solito si inizia con il definire le ipotesi Ha visto che rappresentano l'ipotesi che cerchiamo a FAVORE.
Z = media campionaria - media della popolazione, diviso deviazione standard / radice quadrata di N.
Valori elevati di Z rappresentano quindi delle prove evidenti contro Ho
Valori elevati di Z indicano che la stima è lontana dal valore del parametro specificato sotto Ha.
L'ipotesi alternativa determina quale DIREZIONE deve prendere Z per andare contro l'ipotesi Ho.
IL VALORE P - è la probabilità calcolata assumendo vera Ho, che Z assume un valore TANTO o PIU' ESTREMO di quello attualmente osservato
valore P piccolo indica una forte evidenza contro Ho
valore P elevato non rappresenta invece un evidente segnale contro Ho.
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2025