|
|
| |
Se cerchiamo la parola "conoscenza" sul vocabolario Zingarelli della lingua italiana, troviamo la seguente definizione:
Conoscenza: 1) Facoltà, atto, modo, effetto del conoscere. 2) Rapporto tra soggetto e oggetto, tra pensiero ed essere che si può configurare in vari modi (sin. gnoseologia)
La seconda definizione (gnoseologia) rimanda a un aspetto della filosofia che ha suscitato un immenso dibattito, dall'epoca degli Elleni fino a oggi. Si tratta di un tema estremamente vasto, che riguarda ogni aspetto della cultura umana (e quindi riguarda anche noi), ma che non può essere analizzato in questa sede.
La prima definizione riguarda invece la conoscenza in senso pratico. Secondo questa definizione "conoscere" significa "aver avuto esperienza", "padroneggiare" qualcosa e così via. Se siamo stati a Vienna possiamo dire di "conoscere" la capitale austriaca; un ingegnere del software può dire di "conoscere" il linguaggio C, eccetera. Nel seguito di questo capitolo, quando parleremo di "conoscenza" intenderemo sempre la conoscenza in questo senso.
In generale, la conoscenza empirica sembra fortemente connessa alla capacità umana di assegnare nomi alle cose. Già le religioni primitive attribuivano un ruolo fondamentale alla definizione dei nomi. Nominare un oggetto vuol dire, in un certo senso, possede 828e44i rlo. Molte religioni si "rifiutano" di dare un nome a Dio, considerato per definizione inconoscibile; è il caso della religione ebraica, per fare un esempio, ma lo stesso concetto si ritrova nel pensiero del filosofo cinese Lao Tse
In che senso nominare un oggetto vuol dire possederlo? Un nome è un simbolo che denota un oggetto con tutte le sue caratteristiche; di fatto è un modello mentale (non, ovviamente, da solo, ma in relazione ad altri nomi). Facciamo un esempio. Che cos'è un orso?
E' un carnivoro
E' un plantigrado
E' un mammifero
E' un animale pericoloso
E' un animale peloso
L'orso è mille cose, o può essere definito in mille modi. Non solo: la definizione di "orso" possono variare nel tempo; sarebbe triste ma possibile, ad esempio, che tra qualche decina d'anni si debba aggiungere alla lista anche la definizione "è un animale estinto".
Nel momento in cui dico "orso", dispongo di una rappresentazione (modello) mentale, in cui l'orso assume la sua "posizione" in relazione agli altri "oggetti" a me noti (che a loro volta posso nominare: carnivoro, plantigrado, mammifero, ecc.).
Il concetto di orso è l'elemento semantico che definisce l'orso. Il nostro modo di concettualizzare ci porta a creare reti mentali di termini o nomi, collegati tra loro attraverso precise relazioni. In pratica potremmo dire che qualsiasi conoscenza pratica si fonda sulla costruzione di una rete sintattica che definisce le relazioni tra i concetti afferenti allo specifico mondo conoscitivo. Nella mia mente dispongo di tutte le connessioni legate al concetto di orso; se ne trovo uno libero scappo; se trovo qualcuno che gli spara, lo denuncio (perché è una specie che va protetta). Nella mia mente non ho l'orso. Non ho neppure una rappresentazione completa dell'orso (che implicherebbe conoscere la disposizione esatta di tutti i peli ecc. degli orsi esistenti). In realtà, una simile rappresentazione non mi servirebbe a niente: mi è sufficiente il modello mentale associato al nome "orso", e la rete di relazioni a cui esso è collegato.
I modelli mentali associati ai nomi non sono, ovviamente completi. Se qualcuno mi facesse vedere lo scheletro di un orso e quello di un panda, per esempio, credo che farei molta fatica a distinguerli. Non saprei dire con precisione dove vive il grizzly e dove è diffuso il Kojak, e così via. In modo analogo, anche se conosco Vienna non saprei certo individuare dove si trova ogni palazzo della città semplicemente guardando la fotografia della sua facciata. Di solito esiste un momento in cui riteniamo la "rete concettuale" che definisce la nostra conoscenza sufficientemente ampia per le nostre esigenze. Se so distinguere un orso vivo da un panda vivo, significa che in qualche modo "conosco" entrambi questi animali.
Nel capitolo introduttivo abbiamo fatto notare che il successo della specie umana si deve principalmente alla sua capacità di capitalizzare le conoscenze dei singoli, mediante l'uso del linguaggio. Nel momento in cui la conoscenza acquisita da un singolo uomo viene trasmessa, essa diventa conoscenza collettiva, cioè elemento culturale. La trasformazione delle conoscenze dei singoli in elementi culturali è un problema fondamentale a diversi livelli; cercheremo di affrontarlo più in dettaglio nell'ultimo capitolo.
Il problema della conoscenza e della sua gestione (in senso lato) è particolarmente sentito nel mondo aziendale. Le aziende devono preoccuparsi di costruire una "cultura aziendale", nel senso che abbiamo visto. Senza di essa, sarebbero nelle mani di coloro che singolarmente detengono conoscenze particolari, che diventerebbero personaggi insostituibili. La consapevolezza di questa necessità ha portato alla definizione di una disciplina (dai contorni un po' vaghi), il cosiddetto knowledge management. Si può dire che gli iniziatori del knowledge management siano stati due giapponesi, Ikujiro Nonaka e Hirotaka Takeuchi, che hanno esposto le loro idee in un libro ormai celebre
Il punto di partenza della riflessione di Nonaka e Takeuchi è la distinzione tra quelle che i due autori chiamano conoscenza tacita e conoscenza esplicita.
La conoscenza tacita è tipica del "saper fare"; ad es. un bravo muratore è capace di tirare su un muro diritto ma, interrogato, potrebbe non saper spiegare come fa. In questo caso si parla di know-how (sapere come...).
La conoscenza esplicita è una conoscenza raccontata (o raccontabile); in un certo senso, una conoscenza che ha preso consapevolezza di sé. In questo caso si parla di know-that (sapere che...).
La rete di concetti associata ai nomi, finché rimane nella nostra testa, è utile a ciascuno di noi per razionalizzare il mondo e i suoi aspetti, ma non è utilizzabile da altri. La conoscenza tacita muore con il suo possessore; solo la conoscenza esplicita può essere capitalizzata in senso culturale. In questa operazione, secondo Nonaka e Takeuchi, si "crea" conoscenza. Anche se Nonaka e Takeuchi riferiscono la questione allo stretto ambito aziendale, l'esplicitazione della conoscenza è un aspetto fondamentale della creazione di cultura a ogni livello possibile.
C'è una frase che è stata attribuita a uno dei fondatori della scienza occidentale, Isaac Newton: "Se ho visto così lontano, è perché mi sono issato sulle spalle dei giganti". I "giganti" di cui parla Newton sono la generazione di filosofi della natura che l'hanno preceduto, primi fra tutti Galileo e Cartesio. Questa frase è molto significativa, dal punto di vista del problema che stiamo esaminando. Possiamo dire che il genio individuale è ciò che ha permesso a Newton la grande sintesi della meccanica classica; questo è stato possibile, in senso lato, grazie al suo "know-how", ma non sarebbe stato possibile senza il "know-that" culturale legato alle conoscenze (esplicite) acquisite e capitalizzate prima di lui.
Ci sono almeno tre ordini di problemi fondamentali legati all'esplicitazione della conoscenza.
Quali meccanismi occorre mettere in atti per trasformare la conoscenza tacita (dei singoli) in conoscenza esplicita (culturale)? Come "raccogliere" la conoscenza?
Come raggiungere la conoscenza, una volta che essa sia stata esplicitata o raccolta?
Come distinguere la qualità (se così si può dire) della conoscenza individuale, come selezionare quella che deve essere raccolta da quella che deve essere scartata?
In senso pratico, un sistema di conoscenza può essere realizzato usando strumenti informatici; tuttavia cominceremo a esaminare il problema in senso generale, cioè prescindendo da qualsiasi strumento specifico che ci permetta di realizzare un sistema di questo tipo.
La struttura standard di un sistema di conoscenza è stata analizzata in un celebre report Ovum del 2000. Per descriverla possiamo partire da una considerazione. Se il problema è quello di esplicitare la conoscenza, da qualche parte essa deve esistere, sia pure in forma tacita. In un'azienda, ad esempio, esiste sotto forma di migliaia di allegati tecnici, contratti, note commerciali ecc., oltre che nelle teste dei dipendenti e dei collaboratori. In Università è distribuita nella testa dei docenti, in centinaia di dispense, libri accumulati sugli scaffali della biblioteca, ecc.
Di tutta questa conoscenza, quella più facilmente catturabile è quella che è stata "registrata": libri, pubblicazioni, ma anche filmati, registrazioni audio e così via. Un libro rappresenta di per sé un esempio di conoscenza esplicita. Tuttavia, dal punto di vista del sistema di conoscenza, il suo contenuto deve essere classificato: è necessario che la sua esistenza sia nota. Se il libro è scritto, ma si limita a giacere su qualche scaffale polveroso, tanto vale considerarlo conoscenza tacita.
L'architettura canonica di un sistema di conoscenza prevede che esistano uno o più "sorgenti di conoscenza", che nella terminologia standard del knowledge management sono detti repository. Il termine è preso in prestito dal mondo della gestione documentale, in cui si usa per indicare uno spazio (ad esempio uno o più dischi rigidi) in cui sono immagazzinati documenti in formato elettronico. Noi lo useremo in senso lato. Un repository potrebbe essere una biblioteca, o un certo insieme di pagine web accessibili da Internet (o da una intranet aziendale)
Catturare la conoscenza contenuta nei repository comporta la necessità di creare una mappa (mapping) del contenuto dei repository stessi. In senso concreto, nei sistemi informatici di knowledge management la mappa sarà un data base di puntatori di qualche tipo; l'importante è che includa tutti gli oggetti rilevanti per il livello di conoscenza che intendiamo raggiungere.
Come esempi di mapping possiamo citare i seguenti.
In una biblioteca: l'archivio (o gli archivi). E' costituito da schede (una per volume) che riportano vari dati: autore, titolo dell'opera, collocazione, (se possibile) una breve descrizione dei contenuti; le schede sono in ordine alfabetico, in modo che sia possibile esaminarle.
Nel caso di pubblicazioni scientifiche: esistono volumi di "abstract", pubblicati periodicamente, che costituiscono una survey su un certo numero di riviste specializzate; ogni articolo pubblicato su tali riviste è corredato di un certo numero di parole chiave, che confluiscono negli abstract (riprenderemo questo tema più avanti).
Nel World Wide Web: per reperire informazioni ci affidiamo di solito a motori di ricerca.
In un libro: un indice, o un indice analitico, sono strumenti generali di mappatura della conoscenza contenuta nel volume.
Una volta che disponiamo di una mappa completa (sempre nel senso di quello che veramente ci interessa catturare), dobbiamo poterla "interrogare". Dobbiamo cioè disporre di strumenti che ci permettano di consultarla (proprio come si fa con la mappa di una regione geografica). Per capire quanto può essere problematica quest'operazione, facciamo ancora degli esempi.
Una biblioteca dispone di solito di archivi alfabetici per autore e (se va bene) per titolo; gli archivi sono sufficienti solo se chi li consulta ha un'idea di dove cercare quello che gli serve, altrimenti la ricerca risulta lunga e complessa. Si supponga, ad esempio, di voler individuare il personaggio dell'antica Roma che, in punto di morte, esortò i suoi concittadini ad "affrettarsi lentamente" ("féstina lénte"). Questa frase è effettivamente stata detta da un grande romano, ma individuare da chi (basandosi sull'indice della biblioteca) può essere davvero complesso
Nel World Wide Web, i motori di ricerca permettono di individuare solo le pagine che contengono esplicitamente determinate parole. Come si è visto, i motori di ricerca sul Web afferiscono alla categoria degli strumenti di Information Retrieval.
Un sistema di conoscenza deve prevedere appositi servizi, che permettano a chi lo usa di raggiungere in modo efficace la conoscenza che gli serve. Nella terminologia standard dei sistemi di conoscenza, si parla di servizi di discovery. Tanto lo schedario della biblioteca quanto l'interfaccia utente di un motore di ricerca (che include opzioni avanzate, la possibilità di cercare immagini ecc.) sono esempi di servizi di questo tipo.
La figura che segue illustra la struttura standard di un sistema di conoscenza. L'immagine è presa dal già citato report Ovum del 2000, e si riferisce ad un tipico sistema di conoscenza aziendale (Knowledge Base Management System). In essa è possibile riconoscere molti degli elementi che abbiamo descritto.
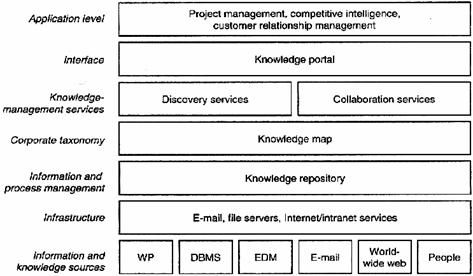
Figura L'architettura standard di un sistema di conoscenza secondo Ovum
E' facile intuire che l'aspetto più interessante e insieme problematico dell'architettura che abbiamo descritto è nello strato individuato nella figura come knowledge map. Come deve essere realizzato questo strato? E' davvero essenziale che ci sia? Nei sistemi concreti che raccolgono conoscenza, il mapping è stato realizzati in diversi modi.
Ricerche testuali (information retrieval): abbiamo già parlato di questa tipologia di accesso ai sistemi di conoscenza. Essa si basa su sistemi software in grado di creare opportuni indici delle parole contenute nei testi inclusi nei repository. Gli indici possono essere considerati a tutti gli effetti come dei data base (più o meno sofisticati) di parole. E' chiaro quindi che tali indici (e tutto l'apparato software necessario per gestirli) costituiscono lo strato mapping del sistema. L'accesso (discovery) avviene semplicemente fornendo al sistema un insieme di parole da cercare. A seconda del grado di raffinatezza del motore di information retrieval, sarà possibile individuare i testi che contengono tutte le parole specificate, almeno una delle parole specificate, le parole specificate a "breve distanza" le une dalle altre, ecc.
Tassonomie: i contenuti (documenti) vengono classificati secondo determinati criteri, e ciascuno di essi è accessibile selezionando la classe a cui appartiene. I titoli dei capitoli di un libro funzionano in questo modo. Semplicemente esaminando l'indice, chi legge ha modo di farsi un'idea del contenuto di ciascun capitolo o paragrafo. Le strutture tassonomiche sono di solito ad albero: classi principali, sottoclassi, ecc.
Sistemi di parole chiave: a ciascun documento vengono associate una o più parole chiave che rimandano ai concetti fondamentali di cui il documento stesso si occupa. Il mapping include le parole chiave e anche la loro eventuale strutturazione tassonomica.
Strumenti software sofisticati in grado di "decifrare" il significato semantico di una ricerca: anche se può sembrare fantascientifica, questa idea è già stata realizzata, almeno in parte, e potrebbe portare a interessanti sviluppi nel prossimo futuro.
Come nel caso degli ipertesti, anche nel caso del mapping dobbiamo liberarci dall'idea che esso richieda necessariamente strumenti informatici per essere realizzato. Facciamo un esempio.
Negli istituti di ricerca che si occupano di astronomia, fino a pochi anni fa, era praticamente certo che si trovassero i volumi dei cosiddetti Astronomy and Astrophysics Abstracts (oggi tali volumi sono disponibili in formato elettronico). Si tratta di una raccolta dei sommari (abstract) di tutti gli articoli che compaiono mensilmente sulle principali riviste del settore. La disponibilità di un sistema di questo tipo è assolutamente vitale per la ricerca. In caso contrario i ricercatori dovrebbero dedicare gran parte del loro tempo a sfogliare le riviste (centinaia), prendendo nota degli articoli che riguardano direttamente il loro settore di attività. Nel momento in cui un articolo viene inviato a una qualsiasi rivista del circuito, gli autori si occupano di specificare un certo numero di parole chiave associate all'articolo stesso. I volumi degli Abstract permettono di cercare i singoli articoli sia in ordine alfabetico di autore, sia per parole chiave, con un sistema affine a quello di un indice analitico.
Come è facile vedere, si tratta di un vero e proprio sistema di conoscenza, secondo la definizione canonica che ne abbiamo dato. I repository della conoscenza sono le riviste che contengono i vari articoli. Il sistema delle keyword permette la loro mappatura, mentre l'indice degli Abstract è il "portale" che dà accesso al servizio di discovery. Si noti che la definizione delle keyword è affidata ai singoli autori, dunque la creazione del mapping è un processo distribuito.
Un esempio di mapping elettronico basato su tassonomie è costituito dalle cosiddette yellow pages utilizzate da diversi portali sul Web. Per esempio, se si accede al motore di ricerca Yahoo è possibile sia cercare nel Web con la tecnica del motore di ricerca, sia accedere a siti preselezionati scegliendo una tra le categorie proposte dal portale.
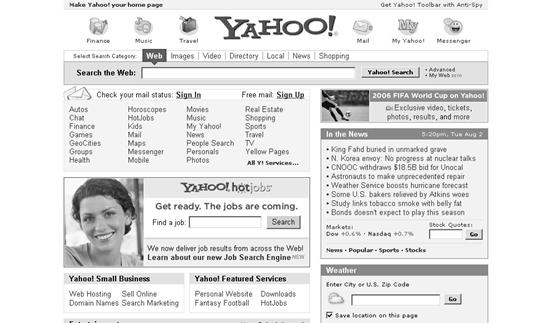
Figura La schermata principale del portale Yahoo; nella parte superiore sinistra sono visibili le "yellow pages"
E' importante rendersi conto della differenza profonda tra un sistema di mapping basato su parole chiave e uno che utilizza la tecnica degli indici di parole. Nel primo caso, ciascuna parola chiave rimanda a un concetto. Se nel portale Yahoo seleziono la voce "Music" significa che sto cercando un disco, un cd, una recensione musicale o qualcosa di simile. Le pagine corrispondenti rimandano al concetto di "musica", in tutte le sue possibili accezioni. Se invece digito la parola "music" come stringa di ricerca, non sto cercando un concetto, ma i siti che contengono la parola stessa. Mi potrebbe capitare, ad esempio, di trovare un sito in cui è riportata la frase: "Ticho Brahe sosteneva di non riuscire a sentire la musica delle sfere celesti"; un sito del genere difficilmente sarebbe classificato sotto l'etichetta "music" nel portale Yahoo. Per fare un altro esempio, nella frase "Il capo della più grande software house del mondo è anche l'uomo più ricco del mondo" "Bill Gates" non compare. Questa frase potrebbe apparire nel più interessante tra tutti gli articoli su Bill Gates, ma la pagina corrispondente potrebbe non comparire quando si cercano le parole "Bill Gates".
La distinzione può sembrare sottile, ma è significativa e gravida di conseguenze. Un mio amico che insegna a Informatica in Bicocca mi ha raccontato il seguente episodio. Nel suo corso egli fa realizzare agli studenti dei prototipi di siti web. I migliori vengono pubblicati su Internet, nel sito del corso. Tempo fa il mio amico ha avuto modo di consultare le statistiche di accesso a tale sito, ed è rimasto stupito dal loro numero, ben superiore a quello degli studenti iscritti. Andando a vedere, si è accorto che un numero sorprendente di accessi era effettuato da utenti Internet che cercavano occasioni di viaggi ai Carabi. Il motivo era semplicemente che un gruppo di studenti aveva scelto di costruire un prototipo di sito web che simulava quello di un'agenzia turistica.
Le parole chiave sono quindi simboli associati ai concetti che devono essere cercati. Nell'esempio del portale Yahoo, non è realmente significativo l'uso della parola Music per accedere ai siti musicali. Chi gestisce il portale avrebbe potuto scegliere qualsiasi altra parola, come XYZTT, limitandosi ad associare a tale parola i siti musicali. Ovviamente una scelta simile sarebbe stata scomoda per il navigatore; per questo motivo le parole chiave sono decifrabili (es. Music) e, se devono essere utilizzate da un'utenza internazionale (come nel caso di Yahoo), utilizzano il supporto di una lingua franca come l'inglese.
Trattandosi di simboli, è relativamente facile costruire strutture "al di sopra" del sistema delle parole chiave che semplifichino o aiutino la ricerca. Spesso, ad esempio, le parole chiave vengono strutturate a loro volta in alberi, fino a formare delle autentiche tassonomie. Esse possono venire connesse tra loro attraverso relazioni (ad esempio: una "mansarda" è un tipo di "abitazione"; un "diodo" è di solito parte di un "circuito elettrico", ecc.). Queste relazioni definiscono la semantica dei concetti (si parla infatti di reti semantiche). Esse possono essere inserite nel sistema del mapping e rese accessibili all'utente attraverso i servizi di discovery. Il caso più noto è quello della relazione di semplice affinità tra due concetti. Gli aiuti in linea dei programmi su computer, come abbiamo visto, forniscono agli utenti la possibilità di accedere ai contenuti attraverso opportune parole chiave. In molti casi, una volta selezionata una parola chiave si ha modo di leggere il testo di aiuto associato, mentre da qualche parte compare la lista degli argomenti collegati. In questo caso il sistema dispone dell'informazione relativa all'affinità tra i concetti associati alle parole chiave, e permette all'utente di "navigare" attraverso tale relazione.
Vorrei sottolineare ancora una volta che il mapping basato sulle parole chiave è una struttura sintattica: il sistema usa le parole chiave come puri simboli (la cui decifrazione è lasciata all'utente), e le relazioni semantiche non sono che relazioni tra simboli. La tecnica delle parole chiave permette, per così dire, di trasformare la semantica in sintassi. In questo senso, il mapping basato su parole chiave sembra ricordare i modelli mentali di cui abbiamo parlato all'inizio del capitolo. Potremmo dire che un sistema di mapping di questo tipo funziona come un modello del mondo conoscitivo a cui si riferisce.
Per proseguire la discussione, dobbiamo a questo punto spendere due parole su cosa si intende esattamente per modello.
L'ambito in cui il concetto di modello è stato sviluppato maggiormente è quello della conoscenza scientifica, ed è qui che dobbiamo volgere lo sguardo. In estrema sintesi, l'atteggiamento scientifico moderno (galileiano) di affrontare la conoscenza potrebbe essere riassunto nel seguente slogan: "non so esattamente cosa voglia dire conoscere, ma se so prevedere un evento, in senso pratico posso dire di conoscerlo". La scienza si occupa di costruire modelli che sono rappresentazioni astratte degli aspetti fenomenici legati ad un determinato ambito conoscitivo, con lo scopo di descrivere i fenomeni stessi e prevederne lo sviluppo (tipicamente temporale).
La parola fenomeno viene dal verbo greco fàino, che significa "apparire", "mostrarsi"; fenomeno è dunque ciò che "si mostra" del mondo reale. La grande scoperta di Galileo e dei suoi successori fu che il mondo dei fenomeni fisici è percorso da relazioni, che sono (relativamente) semplici da descrivere in linguaggio matematico. In senso scientifico, il modello coincide con la mappa delle relazioni logiche che permettono di descrivere il modo dei fenomeni.
Una mappa stradale è un ottimo esempio di modello. La mappa ha uno scopo: permettermi di andare da un punto A ad un punto B. Essa ha limiti di applicabilità precisi. Ad esempio, la mappa può riportare le autostrade e le strade statali, ma non le provinciali; in questo caso, essa potrà essere usata per andare da Milano a Roma ma non, per esempio, per spostarsi da Porretta a Loiano. Si noti che la mappa, a differenza del territorio, è completamente sotto controllo. Il vantaggio dell'uso dei modelli è proprio che essi, in quanto rappresentazioni astratte, sono totalmente dominabili (almeno in linea di principio).
Qualche esempio dovrebbe chiarire sia il concetto di ambito di applicabilità dei modelli, sia la loro natura di rappresentazioni astratte.
Fisica: la legge di Newton. Date due masse e la loro distanza, questa legge permette di calcolare la forza che agisce tra di esse, quindi le caratteristiche generali del moto delle masse stesse (ad esempio, le orbite). La legge di Newton è stata superata nel novecento dalla Relatività Generale di Einstein, che è una teoria più potente, ed ha un ambito di applicabilità maggiore.
Biologia: la tassonomia del mondo animale. Il modello evolutivo darwiniano ci fornisce una "spiegazione" delle somiglianze e delle differenze tra le specie animali, basato su regole di selezione: cosa avviene quando una popolazione rimane isolata, cosa avviene quando si verifica una variante genetica ecc. E' probabile che questo modello non basti per darsi una spiegazione scientifica dell'origine della vita sul pianeta Terra. Se questa affermazione risultasse vera, potremmo dire che il problema dell'origine della vita esula dall'ambito applicativo del modello evolutivo, così come è stato enunciato finora.
Psichiatria: le terapie da adottare per le psicosi. A fronte di determinati comportamenti lo psichiatra è in grado di individuare un certo quadro di psicosi, quindi di inquadrare un malato, di definire la cura adatta (farmaci, terapia psicanalitica) ecc. La psicosi, la sua tipologia, le sue conseguenze, i comportamenti che ne derivano esistono solo nel modello dello psichiatra. Uno schizofrenico può comportarsi in modo del tutto diverso da quello che prevedono i libri di psichiatria. La realtà è straordinariamente complessa; i nostri modelli ci permettono di orientarci, quando la affrontiamo, ma non la esauriscono mai.
Economia: le previsioni dell'andamento delle variabili economiche. Nel momento in cui l'economia di un paese ristagna, ad esempio, l'economista si aspetta che il tasso di inflazione scenda. Questo tipo di previsione si basa sull'esperienza storica (ogni volta che si è verificato il fatto A, puntualmente si è verificato anche il fatto B). Il collegamento tra le relazioni empiriche di causa e effetto nel mondo dell'economia definisce insiemi di regole economiche che poi possono essere applicate. Ancora una volta, gli effetti "reali" alla base degli andamenti economici sono straordinariamente complessi. La conoscenza degli economisti è costituita da modelli, quindi da forti semplificazioni del mondo fenomenico che essi studiano.
E' importante capire che non esiste un unico modello adatto alla descrizione di un certo ambito fenomenico. Ad esempio, se il mio problema è quello di calcolare la traiettoria di un proiettile con un margine di errore di qualche centimetro su una gittata di qualche chilometro, la fisica newtoniana è esatta, cioè: fornisce previsioni che si adattano ai requisiti (purché si tenga conto dell'attrito dell'aria, della forza di Coriolis, ecc.). Viceversa, se il problema è quello di calcolare la traiettoria di un'astronave che passi radente a una stella di neutroni, la fisica newtoniana è insufficiente, e occorre usare le equazioni della relatività.
Non è detto che il modello sia espresso in termini matematici. Lo è (in generale) nel campo della fisica, ma non certamente nel campo della psichiatria; non lo è compiutamente nei campi dell'economia e della biologia. In generale, modelli matematici completi possono essere enunciati in relazione a fenomeni semplici (ad esempio i fenomeni fisici). In ogni caso, la descrizione in termini matematici non è essenziale perché si possa parlare di modello.
Un aspetto generale dei modelli scientifici (di qualunque natura) è stato sottolineato dal filosofo ed epistemologo austriaco Karl Popper (1902 - 1994). Egli si è posto il problema di definire con precisione che cosa fa sì che una certa affermazione abbia carattere scientifico. La prima cosa che verrebbe da dire è: "per essere scientifica, un'affermazione deve essere verificabile". Popper ha dimostrato che il criterio corretto non è quello della verificabilità, ma piuttosto della falsificabilità: le affermazioni che a priori non possono essere falsificate non hanno carattere scientifico.
Per chiarire il concetto, prendiamo un esempio dello stesso Popper. Egli prende in esame la seguente affermazione.
"Esiste una sequenza finita di distici elegiaci latini tale che, se la recitiamo in maniera appropriata in un certo tempo e in un certo luogo, la sua recitazione è seguita immediatamente dall'apparizione del Diavolo, cioè a dire da una creatura simile all'uomo con due piccole corna e uno zoccolo fesso"
E aggiunge:
"... alcuni dei miei amici positivisti mi hanno assicurato che secondo loro la mia asserzione esistenziale intorno al diavolo è empirica. E' empirica ma falsa, mi hanno detto...ma perché, chiedo, chi la considera empirica dovrebbe credere che è falsa? Empiricamente è inconfutabile." (Karl Popper - Scienza e filosofia)
Qual è il problema? Il numero di possibili sequenze finite di distici elegiaci latini è infinito. Nel momento in cui ne abbiamo provate dieci, cento, un milione, un miliardo, senza mai veder apparire il diavolo, non ci siamo avvicinati di un passo alla falsificazione dell'affermazione di Popper. Cioè: l'affermazione non è falsificabile in linea di principio, ed è proprio questo fatto che la rende insostenibile dal punto di vista scientifico. Viceversa, se consideriamo l'affermazione: "Domani sorgerà il Sole", dobbiamo concludere che questa affermazione è falsificabile: può sempre capitare che domani il Sole non sorga.
Per sintetizzare questa sommaria panoramica sul significato dei modelli, possiamo dire che:
Un modello può essere visto come una mappa astratta relativa ad un certo ambito fenomenico.
Esso esplicita (o dovrebbe esplicitare) i suoi limiti di applicabilità.
E' falso solo se, entro tali limiti di applicabilità, non riesce a descrivere alcuni fenomeni, o prevede fenomeni che non si osservano
Deve essere a priori falsificabile nel senso definito da Karl Popper
Constatato che un sistema di parole chiave è un modello di conoscenza, la questione se sia preferibile a un sistema basato sulla ricerca libera sembrerebbe già risolta. I modelli servono per orientarci nel mondo dei fenomeni e prevederne l'evoluzione. Nel senso più specifico del mapping come modello, la possibilità di catturare concetti invece di frasi o parole sembrerebbe un vantaggio assoluto. C'è però un aspetto che getta un'ombra su questo ragionamento.
La realtà descritta dai modelli scientifici è statica. Una volta stabilito che tra due pianeti esiste una forza descritta dalla legge di Newton, possiamo evitare di controllare continuamente che il modello sia ancora vero. Questo non è il caso del mapping della conoscenza. Il contenuto dei "repository" è fluido come un mare in tempesta; i concetti si fanno obsoleti, mentre nuove conoscenze si aggiungono. Se si vuole, questo problema è associabile a quello della falsificabilità di Popper. Abbiamo detto che un modello, per essere valido, deve essere a priori falsificabile. "Falsificare il mapping" significa riconoscere in esso collegamenti a conoscenze false, oppure non trovarvi collegamenti a conoscenze rilevanti. La dinamicità della conoscenza rende quasi inevitabile che entrambi questi fatti si verifichino.
Se le parole chiave sono state definite bene, è difficile che esse rimandino a conoscenze false; tuttavia esse possono rimandare a conoscenze obsolete. Un testo di antropologia dell'ottocento, ad esempio, sarebbe stato classificato all'epoca con numerose parole chiave nei contesti della "fisionomica" o della "frenologia". Un testo di chimica del settecento avrebbe certamente incluso la parola chiave "flogisto". Un testo di fisica della stessa epoca avrebbe usato "calorico", eccetera.
Viceversa, la dinamicità della conoscenza fa sì che nuove parole chiave debbano entrare continuamente nel sistema. Fino a pochissimi anni fa una Knowledge base sulla telefonia avrebbe ignorato parole chiave come "Wap" o "UMTS". La parola chiave "commutazione di pacchetto", all'inizio degli anni sessanta forse sarebbe stata ignorata, non perché la tecnica della commutazione di pacchetto non fosse già stata inventata, ma perché a quell'epoca non era ancora applicata a sistemi rilevanti.
In sostanza le parole chiave catturano sì i concetti, ma allo "stato dell'arte" noto al momento in cui vengono definite. Un mapping per parole chiave è come un modello il cui ambito di applicabilità cambia continuamente nel tempo. Questo problema ha per così dire due facce. Col passare del tempo il sistema è sempre meno in grado di consentire un accesso completo alla conoscenza (ammesso che tale accesso sia possibile in generale). Inoltre, l'idea di aggiornare il sistema tenendo conto della necessità di inserire nuove parole chiave e di eliminare quelle obsolete è assolutamente impraticabile, anche dal punto di vista economico. Un conto, infatti, è il meccanismo distribuito per cui chi inserisce nei repository un documento lo classifica direttamente. Questa è un operazione che si potrebbe definire a costo nullo. Un conto invece è riclassificare una knowledge base di centinaia di migliaia o di milioni di documenti. E' noto, ad esempio, che molte grandi biblioteche italiane (ciascuna delle quali può raccogliere milioni di volumi) hanno un problema fondamentale, per lo più non risolto, di aggiornamento degli archivi. Capita che dispongano di archivi storici, magari dell'ottocento, che oggi sono ritenuti obsoleti; l'investimento che sarebbe necessario per la riclassificazione dei volumi è così alto da sfondare i budget delle biblioteche stesse.
Si potrebbe obiettare che questo problema è legato sostanzialmente alla limitatezza fisica del sistema delle parole chiave. In altre parole, se fosse possibile mappare fin dall'inizio tutti i concetti questo problema non si porrebbe. Quanti sono i concetti associati ad un certo mondo conoscitivo? Questa domanda ci ricorda qualcosa che abbiamo già visto, e cioè il problema del numero di simboli che è necessario definire in una scrittura completamente ideografica. Il paragone non è azzardato: in un certo senso, proprio per via della sua natura sintattica, una parola chiave si comporta come un ideogramma. Come gli ideogrammi, le parole chiave tendono a moltiplicarsi in modo tale che difficilmente i sistemi fisici sono in grado di gestirle, e quand'anche riuscissero a farlo il problema per l'utente di accedere ai sistemi stessi diventerebbe critico.
E' possibile verificare concretamente la tendenza delle parole chiave alla proliferazione incontrollata, attraverso un semplice test statistico. Supponiamo che una certa base documentale possa essere descritta attraverso un sistema finito (ancorché numeroso) di parole chiave. Supponiamo poi di iniziare a classificare i documenti. Prendiamo il primo, stabiliamo le parole chiave che ci servono per descriverlo, poi prendiamo il secondo, facciamo la stessa operazione e così via. E' naturale che prima o poi ci capiti, per classificare un certo documento, di usare qualche parola chiave già definita. Del resto, uno dei vantaggi delle parole chiave è proprio quello di poterle riutilizzare: usare il più spesso possibile parole chiave già note è senz'altro vantaggioso, perché ne limita il numero e permette di identificare concetti più ampi. Consideriamo ora quante parole chiave nuove occorre definire (in media) per ogni oggetto che classifichiamo. Per semplificare il discorso, supponiamo che ciascun documento venga classificato sempre con un numero fisso di parole chiave; il caso più semplice è quello di una sola parola chiave per documento. All'inizio, dunque, ogni volta che classifichiamo un documento definiremo una nuova parola chiave. Andando avanti, capiterà che qualche documento potrà essere classificato con una parola chiave già definita, il che significa che (nell'esempio che abbiamo fatto) i documenti dovrebbero essere senz'altro più numerosi delle parole chiave. Supponiamo ora che le parole chiave necessarie per classificare i nostri documenti siano in numero finito. Se è così, la probabilità che classificando un documento non sia necessario definire una nuova parola chiave cresce con il numero dei documenti che esaminiamo. Riportando su un grafico cartesiano il numero di documenti esaminati e il numero di nuove parole chiave entrate nel sistema in corrispondenza di ciascun documento, ci aspettiamo di trovare una distribuzione che si appiattisce e tende a un valore che corrisponde al numero totale delle parole chiave "possibili".
Cosa avviene nel caso delle Knowledge base reali? Se prendiamo ad esempio il caso degli Abstract dell'astronomia già citati in questo capitolo, quello che otteniamo è rappresentato nella figura seguente.
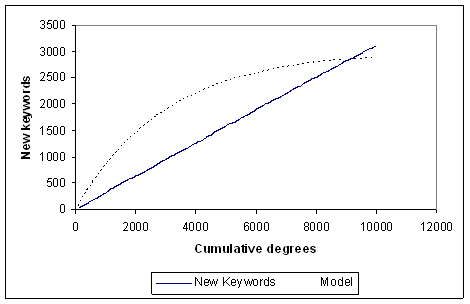
Figura La distribuzione delle nuove parole chiave nella Knowledge Base degli articoli di astronomia
La curva tratteggiata rappresenta un esempio di quello che ci si potrebbe aspettare se il numero di parole chiave fosse finito (nel caso rappresentato, circa 3.000). Si potrebbe obiettare che 3.000 parole chiave sono poche, e che aumentandone il numero le due curve potrebbero assomigliarsi, ma non è così. Basta notare, infatti, che la pendenza della distribuzione reale all'origine è sensibilmente minore di quella attesa sulla base della semplice ipotesi che le parole chiave siano in numero finito, e che vengano scelte "a caso" per marcare i documenti.
Indubbiamente la nostra ipotesi che ogni documento (nel caso specifico, ogni articolo di astronomia) venga classificato con una sola parola chiave è semplicistica e falsa, ma la distribuzione che abbiamo mostrato mette in evidenza un altro problema: le parole chiave non sono tutte ugualmente probabili. In ogni sistema reale ci sono parole chiave usatissime, altre molto meno "gettonate". Questo altera la statistica. In particolare, nel caso astratto che abbiamo presentato prima la pendenza della curva all'origine dovrebbe essere per forza di 45 gradi (all'inizio, abbiamo detto, ogni nuovo documento deve corrispondere a una nuova parola chiave). Nel caso reale, come si vede, non è così.
In ogni caso quello che emerge è che non c'è nessuna apparente tendenza ad appiattirsi nella distribuzione delle nuove parole chiave. Il sistema delle parole chiave sembra crescere linearmente con il numero dei documenti. Questo conferma che le parole chiave necessarie per classificare gli articoli di astronomia, se non sono infinite, sono comunque un numero enorme. Del resto, abbiamo già fatto un paragone tra le parole chiave e le scritture ideografiche: in entrambi i casi si tratta di sistemi di simboli associati a concetti. Anche nel caso delle scritture ideografiche avevamo notato la sostanziale impossibilità di tracciare "tutti i concetti possibili".
Ricapitolando, possiamo dire che:
Il mapping basato su parole chiave ha il vantaggio di essere controllato e sintattico.
Puntando a concetti, permette di raggiungere con esattezza tutto ciò che è stato classificato.
Tuttavia, esso congela la conoscenza allo stato dell'arte al momento in cui le parole chiave vengono definite; la riclassificazione è per lo più impossibile.
Inoltre, i sistemi di parole chiave tendono a divergere.
In conclusione, la tendenza recente è quella di rinunciare all'idea di sistemi completamente basati su parole chiave. Nei casi reali tendono a prevalere sistemi con ricerca libera, o eventualmente sistemi misti (come il caso del portale Yahoo di cui abbiamo parlato).
Il tema dell'utilizzo e della diffusione della conoscenza nelle aziende (o della "creazione" di conoscenza, secondo la terminologia di Nonaka e Takeuchi) merita di essere discusso in modo più ampio. Non c'è guru del knowledge management che non abbia sottolineato che la conoscenza aziendale è un problema eminentemente culturale, che non può essere ridotto ai suoi aspetti "sistemici". In altre parole, nel momento in cui un'azienda si dota di un sistema (tipicamente software) per la gestione della conoscenza, ha compiuto un passo necessario ma assolutamente non sufficiente nella direzione del knowledge management.
E' inutile sottolineare quanto sarebbe importante per un'azienda sapere o poter gestire la conoscenza al suo interno. Da questo punto di vista gli aspetti critici sono almeno due.
Esiste innanzi tutto il problema del riuso (o dell'uso) delle conoscenze acquisite dai singoli. Può capitare che il dottor Rossi abbia un problema tecnico che richiede conoscenze di cui non dispone e che sia costretto a dedicare tempo per procurarsele mentre, due uffici più in là, il dottor Bianchi ha già affrontato un problema del tutto equivalente con successo pochi mesi prima. Semplicemente, non è detto che il dottor Rossi lo sappia.
In generale sussiste il problema, per un'azienda, di basare tutta la propria azione su conoscenze (tecnologiche e di mercato) il più possibile aggiornate. E' opinione generale che proprio nella disponibilità di conoscenze e nella rapidità della loro capitalizzazione stia il principale vantaggio competitivo in cui un'azienda di oggi può sperare.
La creazione di conoscenza, o se si preferisce la sua esplicitazione, è un processo collettivo in cui numerose entità (i singoli individui) cooperano in modo distribuito. Una conoscenza per così dire "imposta in modo centralizzato" non potrebbe essere che una conoscenza statica; di più, essa procederebbe con i tempi tipici degli individui preposti al suo controllo, che sono immensamente più lenti di quelli caratteristici di un processo corale. Nel momento in cui si cerca di declinare questo concetto al caso dell'azienda, tuttavia ci si rende conto che c'è un problema di fondo.
Il mondo moderno vive il business come una guerra. L'azienda è un esercito schierato a battaglia per la conquista del mercato. Ora, da che mondo è mondo non è mai esistito un esercito "democratico", e l'azienda non fa eccezione. Un'azienda sana consente la libera circolazione delle idee al suo interno, anche se di norma tende a emarginare tutti coloro che si fanno portatori di atteggiamenti disfattisti (il personaggio che si aggira per i corridoi sostenendo che il direttore generale è un idiota e le sue idee porteranno l'azienda alla rovina di solito non fa carriera). Tuttavia, la libertà di espressione e la libera circolazione delle idee sono condizioni necessarie ma non sufficienti per la democrazia, che tipicamente comporta la polverizzazione dei momenti decisionali (almeno in una certa misura). In altri termini, perché ci sia democrazia non importa solo che ciascuno possa esprimere le sue idee, ma anche che l'opinione di ciascuno abbia un peso nella formazione delle decisioni. Questo non avviene in nessun esercito, e non avviene nelle aziende.
Il comandante in capo di un'armata, se è intelligente, ascolterà con attenzione l'opinione dei suoi generali, e poi farà di testa sua. Il general manager di un'azienda, se è intelligente, ascolterà con attenzione l'opinione delle sue prime linee, e poi sceglierà da solo. Né il comandante in capo di un'armata né il general manager di un'azienda prenderanno mai decisioni strategiche in modo assembleare. La conseguenza è che, dal punto di vista della conoscenza, l'azienda tende ad essere sempre più un mondo di "black box" permeabili solo nella misura in cui la direzione ha deciso che lo siano. L'attenzione alla riservatezza nella gestione dei dati. tende a diventare quasi maniacale. Ogni gruppo deve conoscere esclusivamente e solo ciò che gli è necessario per svolgere le proprie mansioni. Ogni ruolo aziendale corrisponde a un suo proprio livello di visibilità di ciò che avviene dentro e fuori l'azienda. I dati sugli andamenti degli utili e dei fatturati vengono discussi in riunioni a cui hanno accesso solo coloro che di tali dati devono prendere visione. Gli stipendi sono noti agli uffici del personale, così come i benefit, gli stati di carriera, gli incentivi. Se Rossi è destinato a succedere a Bianchi in un determinato ruolo è noto solo al direttore generale e al capo della divisione di cui Rossi e Bianchi fanno parte, e così via. In definitiva (e in senso lato) l'azienda moderna non sembra avere nessuna intenzione di diventare l'azienda basata sulla conoscenza di cui sognano i teorici del knowledge management. Se è vero che la creazione di conoscenza non può che essere un processo distribuito, questo processo è evidentemente in conflitto con le black box aziendali, che si comportano come autentiche barriere rispetto alla distribuzione di conoscenza. Questo problema ha fatto sì che gran parte degli studi sul knowledge management siano stati dedicati agli aspetti legati al governo del processo di creazione della conoscenza, più che alla sua natura e alle sue caratteristiche intrinseche. Questo problema esiste sia sul versante aziendale, sia su quello dei singoli operatori in azienda.
L'azienda nel suo complesso non può ammettere che le conoscenze vengano distribuite al di fuori di un rigido controllo su chi ne dispone e perché. L'incentivazione allo scambio di conoscenze, in senso generale, non può prescindere da questo aspetto.
I singoli si rendono conto che la loro conoscenza è, di fatto, potere aziendale. Il più delle volte, quindi, sono profondamente restii a condividere tale conoscenza con altri. In molte aziende finisce con l'essere prevalente l'aspetto di "chi sa cosa" (cioè: a chi ci si può rivolgere per avere informazioni su un certo tema) piuttosto che quello legato alla distribuzione delle conoscenze nel vero senso della parola.
Nei prossimi paragrafi studieremo comunque il problema prescindendo da questi aspetti. L'azienda che crea conoscenza, o anche solo che riesce a farla circolare, è una sfida di dimensioni troppo ampie perché possiamo pensare di accettarla in questa sede. Quello che ci interessa, invece, è come potrebbe essere fatto e gestito un sistema di conoscenza.
La tecnologia Web può essere applicata anche nel contesto di una rete locale, ad esempio nell'ambito di una singola azienda, di un singolo ente pubblico, di una rete di aziende o di enti pubblici ecc. Di fatto, questa tecnologia è stata adottata con successo in svariatissime situazioni. Si parla in questo caso di intranet, parola derivata per similitudine da "Internet". Con il termine Intranet si intende quindi un servizio disponibile su una rete locale con caratteristiche simili a quelle di Internet: pagine multimediali che nel loro complesso definiscono un ipertesto, accessibilità di documenti, immagini, filmati, programmi applicativi ecc., il tutto gestito attraverso il linguaggio html (o le sue estensioni). Come sinonimo si usa anche il termine CWW (Corporate-Wide Web), cioè "web esteso a una singola azienda".
Nel contesto di questo corso, la intranet ci interessa per due ragioni: essendo basata su tecnologia web, presenta le caratteristiche reticolari di un ipertesto; inoltre, nel momento in cui viene adottata in ambienti aziendali multinazionali con un altissimo numero di addetti, si comporta come un medium (per lo meno entro i suoi confini). Come vedremo, nel momento in cui si dota di una intranet l'azienda fa di tutto per eliminare l'atteggiamento anarchico che è tipico del Web su Internet.
L'uso della tecnologia Web ha diversi vantaggi: ad esempio è standard e non richiede strumenti client dedicati. Soprattutto, è un passo enorme verso l'unificazione dei sistemi in azienda. La Intranet permette alle aziende di concentrarsi solo su pochi strumenti software, di alta qualità, e, tra le altre cose, di non dissipare energie (e denaro) nella formazione del personale, nel trasferimento di informazioni tra sistemi diversi ecc.
La gestione della intranet viene normalmente è affidata di solito a gruppi interni, tipicamente alle aree ICT, almeno per le aziende sufficientemente grandi. La sigla ICT sta per Information and Communication Technology. Tale gestione può anche essere appaltata in outsourcing, ma in ogni caso è centralizzata. Questo significa che le aziende esercitano un controllo continuo su tutto ciò che confluisce nella Intranet. A differenza di Internet, che è un sistema anarchico e privo di centro, la Intranet è gestita come qualsiasi altro servizio aziendale, con dei responsabili e un gruppo dedicato.
In una tipica intranet possono confluire:
Accesso a repository documentali centralizzati (ad esempio: allegati tecnici, documenti di marketing, documentazione commerciale, sistema di qualità, ecc.).
Accesso a contenuti statici e dinamici. Il termine "contenuto" (Content) nella terminologia del Web sta a significare testo o immagini che vengono elaborati di per sé, per poi confluire all'interno di pagine opportunamente predefinite dal punto di vista del layout. Esistono programmi creati appositamente per la gestione dei contenuti (Content Management).
Accesso a sistemi, come ad esempio il controllo di gestione; tali sistemi possono di solito essere "adattati" in modo da avere un'interfaccia Web
Accesso a basi dati centralizzate, come l'archivio clienti, i listini, le gare d'appalto, ecc.
Funzionalità di tipo "collaboration": gruppi di lavoro, giornali aziendali, chat, ecc. Si tratta di funzionalità che possono migliorare in modo enorme la produttività, specialmente quando l'azienda è fisicamente distribuita su un territorio vasto, o addirittura ha sedi in diversi paesi.
La Intranet pone un problema generale legato all'accesso alle informazioni. Non tutti, in azienda, devono poter accedere a tutto. Un esempio tipico è proprio quello del controllo di gestione, tipicamente prerogativa del management. Spesso poi le singole unità operative hanno bisogno di spazi riservati (ad esempio per tutto ciò che non è ancora ufficialmente rilasciato). Nelle intranet il controllo è spesso affidato alle singole aree operative o applicazioni. Chi tenta di accedere ad aree protette deve "farsi riconoscere", cioè fornire il proprio nome e la propria password.
Anche la Intranet crea qualche problema, in un certo senso legato proprio alla sua comodità. Nel momento in cui si afferma in azienda, diventando uno strumento di uso quotidiano per dipendenti e collaboratori, tutte le aree aziendali sono incentivate a "partecipare", cioè a utilizzare la Intranet stessa come veicolo di trasmissione interna di informazione, se non di vero e proprio "marketing". Il risultato è che la Intranet finisce col crescere come una colonia di funghi.
Malgrado gli sforzi degli enti centrali preposti al suo sviluppo, le nuove componenti finiscono coll'integrarsi male con quello che esisteva già. Lo sforzo di ristrutturazione cresce più che linearmente con la crescita dei contenuti; tale sforzo è ritenuto spesso "poco strategico", quindi viene finanziato male. Il risultato è spesso una forte perdita di efficienza col passare del tempo. Le affermazioni tipiche dei dipendenti, quando sono chiamati a valutare la Intranet dopo qualche anno di esercizio, sono del tipo: "Sulla intranet c'è tutto, ma non si sa cosa c'è", oppure: "Sulla intranet ci sono cose importanti per me, ma non so dove (non riesco a trovarle)".
Il Corporate Portal è un concetto nato per risolvere questo tipo di problema. Esso nasce per similitudine rispetto ai portali Internet, e si pone esplicitamente l'obiettivo di razionalizzare la Intranet. L'idea di Corporate Portal è nata con l'onda di marea della fine del secolo legata all'esplosione di Internet e della tecnologia Web. E' stata, soprattutto all'inizio, un'ottima intenzione poco "declinata" nei suoi aspetti operativi e concreti; di fatto, i diversi vendor che piazzavano sul mercato prodotti orientati al Web finivano col dare definizioni del Corporate Portal semplicemente orientate alle caratteristiche dei loro prodotti.
Cerchiamo di definire, in senso del tutto generale, cosa dovrebbe fare un Corporate Portal.
Rappresentazione dei processi aziendali. Ogni servizio erogato dal Corporate Portal sottende un certo processo aziendale. I processi possono essere semplici (come un agenda centralizzata) o complessi (come la gestione di un magazzino). Il Corporate Portal deve contribuire in modo significativo all'efficienza di tali processi ed alla loro integrazione.
Single Sign-On (SSO). Il Single Sign-On è un meccanismo che permette all'utente di identificarsi una volta sola, in fase di accesso al sistema. Un sistema di SSO integrato con il Corporate Portal consente la gestione centralizzata della sicurezza (politiche e accessi) per applicazioni diverse; inoltre esso presenta agli utenti un'unica interfaccia. In questo modo tutta la gestione dell'accesso è centrata sull'utente (non sull'applicazione). Inoltre, le regole di accesso sono applicabili a gruppi di utenti (si può ad esempio specificare quali aree del Corporate Portal sono destinate al management, quali al personale del marketing, anche incrociando tra loro i profili).
Personalizzazione e profilazione. L'idea è di fare in modo che tutta l'interfaccia del Corporate Portal sia personalizzata rispetto al profilo specifico dell'utente che vi accede; chi opera in azienda deve essere in grado di percepire il Corporate Portal come un mondo chiuso, che contiene tutto e solo quello che gli serve, ma anche come un mondo nel quale trovarsi a proprio agio. La personalizzazione può andare anche oltre; il Corporate Portal potrebbe "accorgersi" della tendenza di un utente ad accedere a certi servizi, e modificare la sua interfaccia in modo da presentarli con maggiore evidenza. Il problema riguarda sia particolari gruppi di utenti, che vedono solo i servizi per cui sono abilitati in base al loro profilo, sia singoli utenti, che vedono principalmente i servizi che (singolarmente) usano.
Gestione dei dati e dei flussi informativi. L'accesso ai dati strutturati e non strutturati viene gestito in modo tale da evitare duplicazioni o perdite di informazione. Questo problema era quasi inevitabile nel modello della vecchia Intranet. Per dati strutturati si intendono i data base centralizzati; i dati non strutturati sono quelli di tipo documentale.
Struttura interna. La struttura del Corporate Portal è disegnata a misura dei suoi utenti. Le informazioni devono essere reperibili nel modo più naturale. Chi accede al Corporate Portal non deve (in linea di principio) porsi domande del tipo "dove sarà mai il dato che mi serve?". Questo implica che la struttura logica e l'albero di navigazione siano disegnati in modo da corrispondere all'organizzazione aziendale.
Semplicità e uniformità delle interfacce. Il Corporate Portal condivide con i portali Internet alcuni paradigmi legati all'usabilità. Questo implica una particolare cura nella definizione delle interfacce utente, che devono essere uniformi (nella intranet le interfacce erano spesso ereditate dai precedenti sistemi integrati solo dal punto di vista funzionale), e definite con criteri razionali (le stesse componenti occupano sempre le stesse parti dello schermo). Se gli aspetti di brand sono rilevanti, occorrerà richiamare con colori e scelte di caratteri i loghi aziendali.
Come possiamo classificare i servizi offerti da un Corporate Portal? Proviamo innanzi tutto a elencarne alcuni possibili.
Agenda centralizzata
Indirizzario centralizzato
Bacheca centralizzata
Sito della divisione Marketing
Cruscotto aziendale sulle vendite (a disposizione del management)
Gestione documentale
eccetera.
E' evidente che questi servizi giocano ruoli molto diversi.
Alcuni di essi sono destinati a tutti gli utenti (agenda, indirizzario, bacheca...). In questo caso possiamo parlare di servizi di tipo generale. L'accesso a tali servizi può dipendere, in qualche modo, dal profilo, dal ruolo e dalla posizione dell'utente nel contesto aziendale (ad esempio, non è detto che un manager voglia far vedere la sua agenda a tutti).
Ci sono poi servizi mirati alle direzioni, ad esempio il sito della divisione Marketing o quello dell'IT. Servizi di questo tipo possono avere una componente "privata" e una "pubblica". Quella "privata" include informazioni e strumenti di uso interno alla direzione, quella "pubblica" permette alla direzione interessata di rendere note informazioni o altro a tutta l'azienda.
Come terza categoria potremmo definire i servizi di base, ad esempio, la gestione documentale. Il sistema di gestione documentale, con ogni probabilità, deve supportare diverse direzioni e aree dell'azienda, ciascuna con le sue peculiarità. Ad esempio, una certa area potrebbe richiedere funzionalità avanzate di ricerca sui testi, altre aree potrebbero voler collegare la gestione documentale ai flussi operativi del processo interno (workflow).
Alcuni servizi possono poi insistere sul "core business" dell'azienda. In questo caso parleremo di servizi core. Si pensi, ad esempio, al monitoraggio delle vendite, alla gestione del magazzino, e così via. Servizi di questo tipo hanno un grado di rilevanza particolarmente alto. E' difficile immaginare che un'azienda sia arrivata al punto di porsi il problema dell'implementazione di un Corporate Portal senza disporre già di strumenti per la gestione del core business. E' quindi ragionevole pensare che, in questo caso, il ruolo del Corporate Portal stesso sia quello di integrare servizi già esitenti, fornendo loro un interfaccia di tipo Web.
L'ultima osservazione che abbiamo fatto ha carattere generale. In moltissimi casi, infatti, il Corporate Portal deve porsi più dal punto di vista dell'integrazione di servizi già esistenti che da quello della realizzazione di servizi ex novo. Va da sé che la scelta se integrare un certo servizio limitandosi a fornire un interfaccia di tipo Web a uno strumento software già esistente, oppure reimplementare il servizio dipende da molte cose (che fondamentalmente si riducono alla valutazione del rapporto costi/benefici).
Nello sviluppo di un Corporate Portal è essenziale rendersi conto della natura (e delle priorità) di ciascun servizio, dando la precedenza a quelli che sono insieme più "fattibili" e più "importanti".
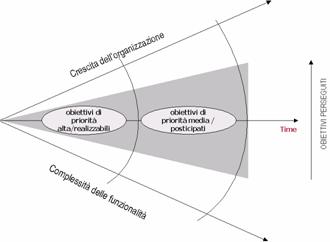
Figura La strategia generale di crescita di un Corporate Portal
La fattibilità di un servizio dipende principalmente da aspetti tecnologici. La si può misurare in termini di costo implicato dalla realizzazione. L'importanza è più difficile da definire; ci sono almeno due aspetti da tenere in considerazione:
In che misura il servizio insiste su processi critici o di tipo core, non trascurando la possibilità di implementare i servizi (anche critici) in modo graduale. In altre parole, se l'azienda già disponeva di servizi non Web per la gestione di determinati aspetti critici, non è detto che la riconversione al Web sia indispensabile in tempi brevissimi.
Quanti sono gli utenti interessati, qual è il target del servizio.
L'importanza del target è un aspetto particolare, sul quale vale la pena di spendere qualche parola. Secondo uno studio di Ovum i costi di sviluppo di un EP non crescono linearmente con il numero di utenti. A parità di requisiti, il costo per implementare le funzionalità richieste da un portale per 1000 o per 100000 utenti non varia in maniera significativa. Risulta invece che:
Un portale per 500 utenti è utile ma economicamente poco conveniente
Un portale per 700 utenti diventa economicamente interessante
Un portale che raggiunge 2000 utenti ha dei costi inferiori a quelli necessari per raggiungere gli utenti in qualsiasi altra forma
Anticipare lo sviluppo dei servizi ad alto target significa quindi anticipare il ritorno dell'investimento. Nella Figura 1‑2 sono rappresentati schematicamente alcuni servizi. La lunghezza delle barre rappresenta il numero di utenti (potenzialmente) interessati a ciascuno di essi. Anticipando quelli con il maggiore target, si ottiene l'effetto di raggiungere prima la quota di utenza necessaria a "rientrare" con i costi.
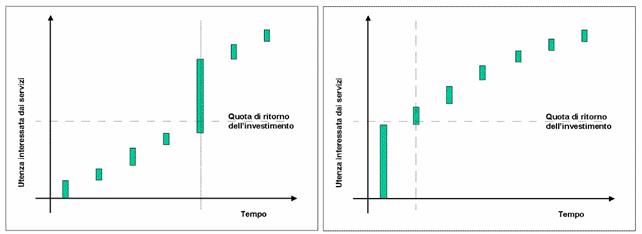
Figura Una strategia di sviluppo basata sul target
Sembra quindi molto importante dare la precedenza, per quanto possibile e compatibilmente con gli obiettivi generali del Corporate Portal, alla realizzazione dei servizi con alto target.
"Il Tao a cui è possibile dare un nome non è il Tao eterno". Con queste parole inizia il Tao Te Ching di Lao Tse.
E' invalso l'uso del termine knowledge base sia per intendere i repository che stanno alla base del sistema di conoscenza, sia come sinonimo del sistema di conoscenza stesso. Il termine è evidentemente mutuato dal più comune data base. Di solito si parla di data base come raccolta di dati (tipicamente sotto forma di tabelle), mentre ai sistemi di gestione dei dati stessi si dà il nome di DBMS (Data Base Management System). Estendendo la terminologia, si dovrebbe parlare di KBMS (Knowledge Base Management System).
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2025