|
|
| |
L'apparato vocale umano può essere schematizzato come un tubo acustico in grado di variare la propria forma nel tempo eccitato da una sorgente di energia . Questo tubo acustico ha in genere la funzione di filtrante sul segnale alimentato dalla sorgente di energia , che può essere individuata nei polmoni.
Questo responsabile dei suoni cosiddetti vocalizzati utilizza le corde vocali ;l'apertura creata da queste è in grado di aprirsi e chiudersi a un ritmo variabile dagli 80 ai 200 periodi al secondo ,producendo così un segnale acustico periodico di forma quasi triangolare. Il segnale ,passando attraverso il tubo acustico ,viene filtrato acquistando caratteristiche spettrali determinate dalla forma assunta dal tubo acustico stesso.
Le vocali sono suoni o FOMENI vocalizzati. Esistono però anche alcune consonanti che possono essere considerate vocalizzate. I suoni elementari o fonemi si contraddistinguono dunque dalla forma che assume il tubo acustico durante la loro produzione e dal tipo di eccitazione.
Il fonema è un'astrazione teorica: non esiste come entità a sé stante. Infatti la parole sono formate da sequenze di suoni e le frasi da sequenze di parole; quindi ,nel passaggio da un suono all'altro il tubo acustico passa da una configurazione alla successiva in modo continuo ,producendo intervalli di segnale le cui caratteristiche spettrali variano in modo molto rapido(transizioni).Almeno nelle sue porzioni transitorie ,la realizzazione fisica del fonema è fortemente dipendente dal contesto fonetico in cui è inserita. Ad esempio, la /m/ nella parola amo si realizza in un segnale acustico differente dalla /m/ della parola uomini; per questo si parla di due diversi <allofoni> dello stesso fonema /m/.
Il fenomeno che prende il nome di coarticlazione, aumenta in modo notevole il numero effettivo di eventi acustici distinti di una lingua parlata. Si possono comunque definire eventi acustici elementari che risultano abbastanza indipendenti dal contesto. Questi elementi sono chiamati DIFONI e sono definiti come segmenti di segnale acustico che vanno dalla metà della parte stazionaria di un fonema fino alla metà della parte stazionaria del fonema successivo. Per ciò i difoni comprendono interamente la transizione fra due fonemi e, se per esempio una lingua prevede 30 fonemi, si possono avere 30 X 30 = 900 difoni.
Un'altra sorgente di variabilità del segnale vocale è dovuta alle differenze di pronuncia che si verificano sia fra parlanti differenti , sia nelle frasi e parole pronunciate in tempi differenti dalla stessa persona: questo implica una variabilità spettrale nella voce prodotta da diverse persone. Inoltre anche la voce prodotta da uno stesso soggetto rivela una notevole varianza nelle caratteristiche di un dato suono pronunciato in tempi diversi.
La voce deve essere considerata quindi un fenomeno casuale e il suo trattamento richiede l'uso di tecniche di tipo statistico.
Un metodo efficiente per visualizzare l'evoluzione spettrale del segnale vocale è costituito dal SONOGRAMMA.
Il sonogramma è una rappresentazione su tre assi ; tipicamente l'asse orizzontale rappresenta il tempo, quello verticale la frequenza e il terzo l'intensità.
E' possibile quindi seguire l'andamento dei contributi energetici alle varie frequenze durante la pronuncia di una data frase; in particolare è molto significativo l'andamento delle tipiche striature orizzontali (chiamate formanti)che corrispondono alle frequenze di risonanza del tratto vocale e sono quindi direttamente correlate all'evoluzione della sua configurazione articolatoria.
Le tecniche di riconoscimento vocale richiedono l'uso di un calcolatore numerico come unità di elaborazione. Per introdurre la voce in un calcolatore si trasforma il segnale elettrico fornito da un microfono in una successione di numeri in codice binario ,direttamente utilizzabili da un calcolatore.
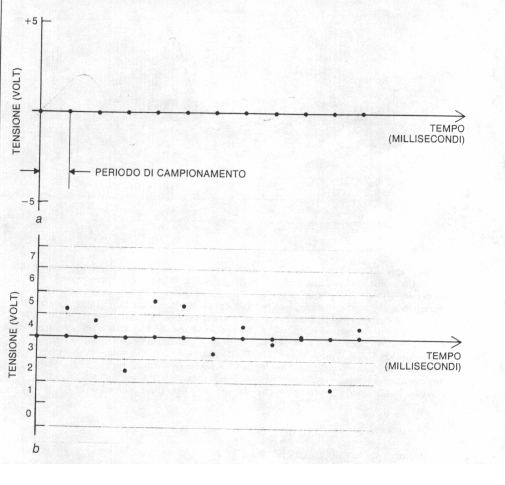
La possibilità di effettuare questa numerizzazione dei segnali ci viene garantita dal teorema del campionamento formulato da H.Nyquist negli anni venti. Questo teorema afferma che un segnale continuo può essere completamente rappresentato e perfettamente ricostruito attraverso una serie di misure , o campioni, effettuate sulla sua ampiezza a regolari intervalli di tempo. L'intervallo fra tali campioni non deve però essere superiore al semiperiodo della più alta frequenza presente nel segnale stesso.
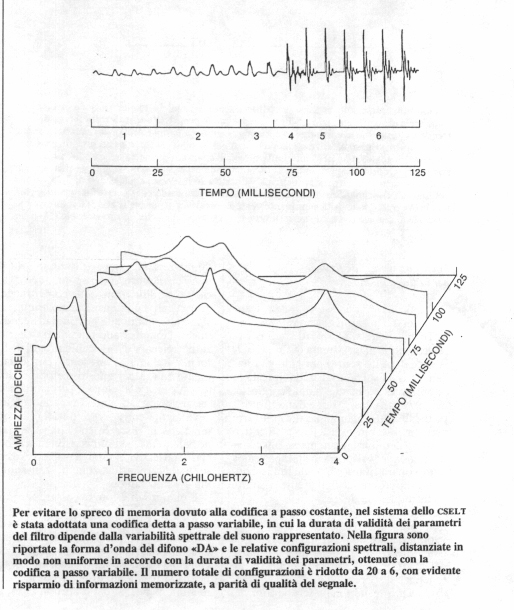
Occorre inoltre considerare che l'informazione contenuta nella forma d'onda del segnale vocale è affettata da una notevole RIDONDANZA. Gran parte di tale informazione può essere eliminata mantenendo inalterate le caratteristiche del segnale che rendono i vari suoni percettivamente diversi: ne risulta un'onda con una configurazione più semplice sola l'informazione discriminante i vari eventi fonetici. Una rappresentazione di questo tipo viene indicata con il termine PATTERN.
Esistono diversi metodi per estrarre una configurazione del segnale vocale : uno di questi è il cosiddetto metodo delle BANDE CRITICHE.
Il segnale vocale , dal punto di vista delle caratteristiche spettrali , può essere ritenuto stazionario con buona approssimazione in intervalli dei millisecondi. Supponiamo quindi di suddividere il segnale in intervalli consecutivi della durata di 10 millisecondi che chiameremo finestre( frame in inglese).
Ciascuna finestra di segnale possiede ben determinate caratteristiche spettrali, rilevabili calcolandone lo spettro di energia.(lo spettro di energia è una curva dell'energia in funzione della frequenza. L'area di tale curva fra due valori di frequenza f1 e f2 è proporzionale al contributo energetico al segnale dell'intervallo .
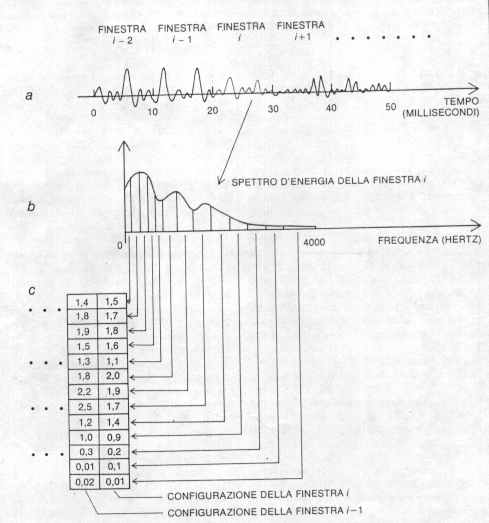
Quindi ogni finestra può essere descritta mediante i vari contributi energetici in ciascuna banda critica. Per fare un esempio ,nell'intervallo fra 300 e 3400 hertz sono individuabili 13 bande critiche (la prima fra 300 e 430, l'ultima fra 2968 e 3400 hertz.
Calcolando quindi lo spettro di energia possiamo ricavare il contributo energetico di ciascuna delle 13 bande e avere una descrizione spettrale della finestra in questione sotto forma di una lista di 13 numeri. In questo modo abbiamo ottenuto la configurazione ad un0unica finestra .Man mano che il segnale si evolve nel tempo, otteniamo così una successione di liste ( o vettori) una ogni 10 millisecondi .Chiameremo questa successione << rappresentazione parametrica>>del segnale vocale.
SISTEMI DI RICONOSCIMENTO:
- per parole isolate
Questo sistema ,inventato nei laboratori della CSELT(centro studi e laboratori telecomunicazioni ) è un riconoscitore delle di parole pronunciate separatamente, vale a dire interponendo pause di silenzio fra di loro. I sistemi di riconoscimento per parole isolate (IWR)sono molto più semplici dal punto di vista realizzativo rispetto a quelli che riconoscono il parlato continuo. Infatti ,essendo le parole separate da pause, il loro inizio e la loro fine sono più facilmente individuabili e per di più non è presente la coarticolazione fra le parole stesse .
Generalmente la determinazione dell'inizio e della fine si basa su misure di ampiezza o di energia del segnale in successivi segmenti temporali. Tuttavia i problemi nascono quando il rumore ambientale è abbastanza elevato , tale da non permettere alle misure di ampiezza di distinguere tra i suoni vocali a bassa intensità e le pause prodotte dal parlante.
Inoltre il parlante stesso può provocare rumori indesiderati all'inizio e alla fine della pronuncia delle parole causate per esempio dalla apertura e chiusura delle labbra, da respiro, dai movimenti meccanici del microfono o da eventuali colpi di tosse. In tal caso è necessario utilizzare misure che rendano distinguibile la voce dagli altri rumori.
Per poter riconoscere delle parole ,il sistema deve possedere in memoria una loro descrizione. Questa descrizione è fornita alla nostra macchina sotto forma di prototipi di parole pronunciate dal potenziale utente.
E' quindi necessario aver fissato in precedenza un vocabolario, cioè l'insieme delle parole che la macchina dovrà riconoscere. Fatto questo l'utente dovrà pronunciare almeno una volta tutte le parole del vocabolario(fase di addestramento).
Le loro rappresentazioni parametriche verranno quindi memorizzate ed etichettate , e andranno a costituire l'insieme dei prototipi. Una volta che verrà pronunciata una parola del vocabolario, questa verrà riconosciuta effettuando un confronto fra la sua rappresentazione parametrica e tutti i prototipi memorizzati durante l'addestramento.
- parlato continuo
Un sistema in grado di riconoscere il parlato continuo, cioè senza pause fra le parole, deve risolvere problemi ulteriori rispetto ad un iwr. Non solo non conosce l'esatta identità delle parole contenute in una frase, ma neppure il loro numero, né l'istante di inizio e di fine di ciascuna di esse. Se fossimo in grado di riconoscere il punto di separazione , nel segnale vocale , fra una parola e la successiva , potremmo applicare la tecnica delle parole isolate sulle varie porzioni di segnale corrispondenti alle singole parole. In realtà non esiste alcuna tecnica che permetta di effettuare questa operazione in modo affidabile, anche perché la separazione fra parole non è facilmente definibile a causa del fenomeno della coarticolazione.
COME SI PUO' INTRODURRE LA VOCE IN UN CALCOLATORE?
Innanzitutto si deve poter disporre di un microfono. Il segnale in uscita da un microfono viene essenzialmente campionato ad intervalli regolari. Immaginiamo che il nostro segnale possa assumere valori di tensione compresi fra -5 e +5 volt. Suddividiamo quindi quest'intervallo in N intervalli più piccoli. Possiamo quindi costruire un quantizzatore che ad ogni campione associa un numero intero (compreso tra 1 e N) corrispondente all'intervallo di tensione al quale il campione appartiene. Il campione può quindi essere rappresentato da questo numero. Quanto più alto è N , maggiore è la precisione con cui viene rappresentato ciascun campione.
Tipicamente vengono utilizzati 4096 intervalli ; quindi ciascun campione può essere espresso da un numero binario di 12 cifre (2^12=4096).
Un'apparecchiatura che svolge tutte le operazioni che vanno dal campionamento alla rappresentazione numerica in codice binario di ciascun campione viene chiamata convertitore A/D(analogico/digitale).Mediante un convertitore A/D è quindi possibile inviare alla memoria di un calcolatore una rappresentazione numerica del segnale acquisito mediante un microfono; il teorema del campionamento formulato da H.Nyquist ci assicura che durante questa operazione (a parte le piccole inesattezze introdotte dalla quantizzazione ) non si ha perdita di informazione ,e pertanto possiamo trattare il segnale numerico come se fosse il segnale reale.
.
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2025