|
|
| |
Il Sistema Operativo è una componente software del sistema di elaborazione. Conviene fare un software che riguardi direttamente la gestione delle risorse, che verrà invocato dal S.O. Ci potrebbero essere più programmi che agiscono insieme e quindi c'è bisogno di qualcosa che li gestisca. Il livello minimo di gestione è che venga dato avvio al nuovo programma solo quando il precedente è terminato; le attività sono svolte sequenzialmente. Potremmo però volere che i programmi lavorino in parallello e per far ciò bisognerà allocare delle risorse ora ad un'attività ora ad un'altra. Le attività di gestione e di allocazione delle risorse sono svolte da un Sistema Operativo realizzato per una particolare architettura. Il S.O. è un insieme di programmi che devono essere presenti affinchè i programmi applicativi vengano eseguiti. Esempi di S.O. sono: Windows 95 (il primo della serie 9.x), Windows 98, Windows 2000 (ereditato da NT), MS-DOS, Windows 3.1 (una via di mezzo tra MS-DOS e Windows 9.x), Mcintosh, UNIX, LINUX (versione UNIX per PC), ecc. La struttura è:
Programmi Applicativi
HW
Il kernel (nucleo) è il cuore del Sistema Operativo; il kernel di Windows 3.1 è il DOS.
Vi sono due modalità d'esecuzione per un programma:
Modalità Utente (User Mode)
Modalità Supervisore (Kernel Mode)
Un programma non può eseguire una qualsiasi operazione fra quelle consentite dal set d'istruzione del sistema se non è in Kernel Mode. In generale possiamo indicare come Sistema Operativo tutto il codice che viene eseguito in Kernel Mode.
Microkernel S.O. (il kernel è ridotto al minimo)
Macrokernel S.O. (il kernel fa tutto [UNIX])
Funzioni del S.O.
Gestione dei processi
Scheduling della CPU (l'utilizzo della CPU viene fatto tramite un TDM).
Sincronizzazione: problemi di programmazione concorrente.
Gestione della Memoria
Viene effettuato uno Space Multiplexing della Memoria.
Gestore dei dispositivi I/O
Gestore dei File File System
Interprete dei comandi
Protezione e sicurezza
Sistemi distribuiti
Collegamenti fra + computer.
Centrale
I/O![]()
![]()
![]()
![]()

Interfacce
Memoria di massa (hard disk)
E' un dispositivo di I/O
Nell'architettura di von Neumann
CPU
 Unità di
Unità di
Controllo
Parte Operativa
L'Unità
di Controllo sorveglia il flusso di informazioni che giunge nella Parte
Operativa. In questa unità è memorizzato ciò che
Dentro
ALU
Unità che esegue operazioni aritmetiche e logiche.
IR (Istruction Register)
Registro di istruzione corrente.
PC (Program Counter)
Contatore di programma; vede qual è l'istruzione successiva.
![]() MAR (Memory
Address Register) Consentono di scambiare
MAR (Memory
Address Register) Consentono di scambiare
MBR (Memory Buffer Register) informazioni
Se qualche dato deve essere trasferito dalla memoria alla CPU, il suo indirizzo viene messo sul MAR e poi viene bufferizzato sul MBR.
k
![]()
![]()
![]() MBR
MBR
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() Memoria h i
Memoria h i
i
MAR
Altri Registri sono:
I/O BR (I/O Buffer Register)
I/O AR (I/O Address Register)
PSW (Program Status Word)
E' un registro di stato e serve per sapere in che modalità di esecuzione siamo. L'esigenza di distinguere uno stato utente (User Mode) da uno stato kernel (Kernel Mode) è nata per motivi di sicurezza: gli utenti possono andare a scrivere in locazioni di memoria riservate al sistema e pertanto è necessario distinguere tra questi due stati. Nessun S.O. sarà sicuro se l'architettura hardware non prevede almeno una parola di stato.
Esucuzione di istruzioni
Il comportamento della CPU nelle esucuzioni di istruzioni può essere schematizzato nel seguente modo:
![]()

 Fetch
indica lo stato di prelevamento dell'istruzione
Fetch
indica lo stato di prelevamento dell'istruzione
![]()
Fetch trasferisce l'istruzione contenuta nel PC (Program Counter) e la invia al IR (Istruction Register).
Tutte le operazioni che vengono svolte all'interno della Parte Operativa sono controllate dall'Unità di Controllo in due modi possibili:
Logica Microprogrammata
C'è una ROM in cui il costruttore dell'architettura hardware inserisce un firmware che controlla le istruzioini.
Logica Cablata
Le istruzioni vengono controllate tramite circuiti sequenziali.
CISC (Complex Istruction Set Control) Logica Microprogrammata
RISC (Riduct Istruction Set Control) Logica Cablata
Architetture non di von Neumann
Questo tipo di architetture hanno le sequenti caratteristiche che non sono presenti nelle architetture di tipo von Neumann:
Interrupt
Più BUS
Gerarchie di Memoria
![]()
![]() Registri
(tempo di accesso circa 1 ns)
Registri
(tempo di accesso circa 1 ns)
![]()
![]()
![]()
![]() Cache
Cache
![]()
![]()
![]() Dimensioni
decrescenti RAM Aumento della
velocità
Dimensioni
decrescenti RAM Aumento della
velocità
Aumento del costo per bit
Cache
CPU
Memoria
|
T Tempo di accesso alla cache
T Tempo di accesso alla memoria
TS = T + T Tempo di accesso al dato

![]() label
label
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
 cache Memoria Principale
cache Memoria Principale
TS = T + T con la presenza di cache
H Probabilità di successo (probabilità che il dato cercato sia nella cache)
Hit Ratio (Probabilità di successo)
TS = HT + (1 - H)(T + T
TS ![]() T allora
l'utilizzo della cache migliora le prestazioni della CPU
T allora
l'utilizzo della cache migliora le prestazioni della CPU
1 = H(T /TS) + (1 - H)[(T + T )/TS
1 = H(T /TS) + (1 - H)[(T /TS)+(T /T )(T /TS
1 = (T /TS)[H + (1 - H)(1 + (T /T
1 = (T /TS)[H + 1 + T /T - H - (T /T1)H]
1 = (T /TS) + (T /T ) (T /TS) - (T /T ) (T /TS)H
(T /TS) = 1/[1 + (T /T )(1 - H)]
(T /TS) ![]() 1 per migliorare
le prestazioni della CPU tramite la cache
1 per migliorare
le prestazioni della CPU tramite la cache
Se T ![]() 10T ho:
10T ho:
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]() (T /TS 1 H 0.8
(T /TS 1 H 0.8![]() 0.9
0.9
Se H ha tale valore (0.8![]() 0.9) il rapporto (T /TS)
si approssima a 1.
0.9) il rapporto (T /TS)
si approssima a 1.
Principio di Località
Memoria
Cache
S SAssumiamo che la cache prelevi dati in maniera random dalla memoria. In tal caso avremmo:
H = (S /S ) Per il fenomeno random la cache dovrebbe essere 80![]() 90 % della
90 % della
Memoria Principale e questo non è possibile visto il costo elevato
per bit della cache
![]()
![]()
![]()
![]()
![]() H 1 località crescente (S /S
H 1 località crescente (S /S
Se la località è crescente potremmo avere valori di cache (S ) piccole che mi garantiscono un valore di H compreso tra 0,8 e 0,9. Questo è vero se cade l'ipotesi di dati distribuiti uniformemente cioè se carico in cache dati che appartengono ad una stessa località e toglierò dalla cache quei dati che non vengono utilizzati spesso, ossia applico una politica LRU (least recently used) che rimuove il contenuto delle celle che non sono state usate da molto.

![]()

![]()
![]()
cache Località
Memoria
I/O e Multiprogrammazione
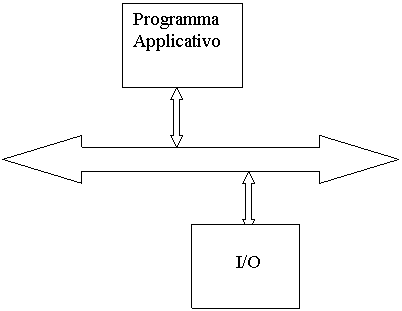
il dispositivo deve essere collegato ad
un Controller che è un vero e proprio Sistema di Elaborazione
3
1 2
Device Controller

![]()
![]()
![]() 1: Registri di Stato
1: Registri di Stato
2: Registri di comando
(contengono istruzioni)
3: Registri dati (buffer)
Device
N.B.: Il registro dati deve avere la dimensione di almeno un'unità di informazione del device.
Il Device può essere character oriented (tastiera) in cui l'unità d'informazione è il carattere, oppure block oriented (hard disk).
Programmi Applicativi
API (Application Program Interface)
![]()
![]()

 Device
Driver Kernel Device Controller Device
Device
Driver Kernel Device Controller Device
Il Device Driver viene di solito eseguito in modalità Kernel, dunque fa parte del S.O. e non può essere chiamato con una semplice chiamata di procedura ma attraverso una Supervisor Call o System Call. Attraverso l'API il programma applicativo comunica con il S.O.
Device Driver Program. Applicat. File Manager![]()
![]()
![]()
![]()
![]()
Parte del File
Device Device Controller
![]()
System
![]()
Polling
I/O
Interrupt
Polling:
il
device driver impegna
Interrupt:
il
device driver non impegna
Codice( 25 ) identifica l'elemento del vettore di Interrupt
![]()
|
|
|
|
|
|
![]()
![]()
![]()
![]() Prima del Fetch si
vede se c'è un interrupt.
Prima del Fetch si
vede se c'è un interrupt.
![]()
![]()
![]()
Controller
![]()
![]()
![]()
interrupt
177
![]() Tabella di Interrupt o vettore di
interrupt
Tabella di Interrupt o vettore di
interrupt
![]()




![]()

![]()
![]()
![]()
![]()
![]()
![]() (è
nella Memoria principale) Indirizzo dell'istruzione che deve
essere svolta all'interno
del Controller
(è
nella Memoria principale) Indirizzo dell'istruzione che deve
essere svolta all'interno
del Controller
Quando c'è l'interrupt il Program Status Word (PSW) viene salvato ed il Program Counter (PC) viene forzato all'indirizzo dell'istruzione corrispondente al codice dell'interrupt [(nell'esempio sopra il PC viene forzato all'indirizzo 177 corrispondente al codice( 25 )]. Dopo l'interrupt sia il PSW che il PC vengono rimpostati al valore prima dell'interrupt e continua il fetch. Se arriva un'altra interruzione mentre vi è una interrupt-handler routine, cioè mentre già si sta gestendo la risposta ad un interrupt precedente, questa verrà interrotta. Si possono disabilitare le interruzioni durante la fase di gestione della risposta ad un interrupt tramite un flag.
Le interruzioni alle quali non si risponde durante l'interrupt-handler routine della prima interruzione, non vengono perse ma messe in una coda di priorità di richieste di interruzioni; ogni interruzione ha un livello di interrupt univoco; un dispositivo non può avere lo stesso livello di interrupt di un altro. Questo meccanismo permette alla CPU di differire la gestione delle interruzioni di bassa priorità senza mascherare tutte le interruzioni, e permette ad un'interruzione di priorità alta di sospendere l'esecuzione della procedura di servizio di un'interruzione di priorità bassa, a meno che quest'ultima non abbia settato il flag di interrupt a 0 (Disable Interrupt).
Dopo l'interrupt si può tornare al fetch in due modi possibili:
Superscalarità
ALU
![]() Virgola Mobile
Virgola Mobile
ALU ALU![]()
![]()
 Aritmetiche Grafica
Aritmetiche Grafica
Schema dell'Interrupt
P programma Utente
![]()
![]()
![]() Modalità Kernel
Modalità Kernel
![]()
 A
A
1: Preparazione I/O
![]() 2:
Esecuzione
2:
Esecuzione
2 B 3: Gestione del risultato
![]()
![]()

![]() 3
3
C
Altro modo per ottimizzare l'utilizzo della CPU:
P
![]()
![]()
![]()
 A
A
![]()
![]()

![]()

![]()
 1 La fase 2 è gestita dal device controller
1 La fase 2 è gestita dal device controller
ed in quel periodo
![]() I/O per svolgere istruzioni del programma
I/O per svolgere istruzioni del programma
3
C
C
Il tempo C è vanificato se si hanno molte richieste di I/O, poiché dovrò bloccare il programma fino a quando il controller non ha finito. Per i programmi CPU-bound (programmi che prediligono processi d'elaborazione) è utile questo schema, mentre per quelli I/O-bound (programmi che prediligono processi di I/O) questo schema non è conveniente. Se il sistema è Monoprogrammabile non ha senso fare l'Interrupt. Mentre se il sistema e Multiprogrammabile, sicuramente ci saranno programmi che sono nello stato CPU-bound e quindi ha senso fare l'Interrupt.
Interrupt Software
Divisione per zero; il programma viene eliminato dal processo di esecuzione.
Trap
Richiesta di Interrupt da parte di programmi.
Così come c'è una tabella per gli interrupt hardware, c'è anche una tabella per i Trap.
INTERRUPT Hardware (proviene da un dispositivo I/O)
TRAP
INTERRUPT Software
Questi 3 eventi modificano il PC portandolo all'indirizzo corrispondente all'istruzione codificata nel segnale. Primo passo è il salvataggio dello stato dei registri della CPU, poi vi è il salto d'istruzione del PC.
TRAP
Il Trap è simile all'Interrupt, ma è generato da un programma che necessita di operare in modalità Kernel.
Trap < argomento > è
![]() il
bit di modalità, non il programma
il
bit di modalità, non il programma
Chiamata di procedura
Il programma non può eseguire istruzioni in modalità Kernel, ma deve intervenire il S.O. che , tramite una chiamata di procedura (Trap) da parte dello stesso programma, esegue l'istruzione di eccezione. L'architettura delle interruzioni memorizza le informazioni riguardanti lo stato cui era giunta l'esecuzione del codice utente, passa alla modalità Kernel e recapita l'interruzione alla procedura del Kernel che realizza il servizio richiesto. Al Trap si assegna una priorità d'interruzione relativamente bassa rispetto a quelle date alle interruzoni dei dispositivi (Interrupt hardware).
Operazione di Scrittura/Lettura
I/O (Dispositivo generico)
![]()
![]() Registri dati
Registri dati
![]()
Se ho una memoria di dimensione K ho:
![]()

![]() possibili spazi di indirizzamento per le celle di memoria K
Per i registri posso fare il seguente ragionamento:
possibili spazi di indirizzamento per le celle di memoria K
Per i registri posso fare il seguente ragionamento:

![]()
![]()
![]()
![]()
![]() Registri
di dispositivi I/O
Registri
di dispositivi I/O
![]() Memoria
principale
Memoria
principale
Dunque posso direttamente fare riferimento ai registri dei dispositivi senza indicare il device corrispondente. Tale configurazione viene chiamata I/O Mappato in Memoria o Memory-Mapped-I/O.
Memoria Principale CPU + Cache L1 Cache Level 2

100 Mhz
![]()

La cache di livello 1 Riuscirò ad inviare un dato
è
integrata nella CPU ogni ![]() sec.
sec.
Bridge IDE SCSI![]()
![]()
![]()
![]()
USB
|
|
|
|
Con il Memory-Mapped anche i dati contenuti nei registri dei device
possono essere caricati in cache. Il problema sorge però se si dovesse staccare
il device, poiché
Assegnazione dei livelli di Interrupt ai device
Plug and Play
Assegnazione dinamica dei livelli di Interrupt; dopo l'aggiunta della periferica il S.O. deve essere riavviato per inizializzare e assegnare il livello di Interrupt al device.
Kernel API


![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]() Driver
Driver
Tabella dinamica per l'entry del device (si inserisce il codice del device)
Quando si accende il computer viene avviato
per primo il bootstrap loading, un
programma per l'avvio e la diagnostica che si trova nella Flash Ram (memoria
riscrivibile). Possiamo quindi aggiornarlo mediante il BIOS; al contrario della
Flash Ram, il BIOS ha bisogno dell'alimentazione. Se si lascia il computer
spento per molto tempo si scaricherà
Processi (Programmi in esecuzione)
Un processo è qualcosa di più del codice di un programma: comprende l'attività corrente, rappresentata dal valore del Program Counter e dal contenuto dei registri della CPU; normalmemte comprende anche la propria pila (stack), che contiene a sua volta i dati temporanei (indirizzi di rientro, variabili locali) e una sezione di dati contenente le variabili globali. Un programma di per sé non è un processo; un programma è un'entità passiva, mentre un processo è un'entità attiva, con un PC che specifica qual è la prossima istruzione da seguire e un insieme di risorse associate.
P Pn
![]()
![]()
![]() CPU Virtuale
CPU Virtuale
CPU
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() P P
P P
![]() C'è
un clock che comanda il passaggio da un
C'è
un clock che comanda il passaggio da un
100 ms 100 ms processo ad un altro
Tempo di overhead della CPU:
Si decide a chi assegnare
Salvataggio del vecchio contesto e ripristino del nuovo (Contex Switching).
![]()
![]()
![]()
![]()
![]()
Tempo per caricare tutti i programmi contemporaneamnete
Tempo per caricare i programmi uno dietro l'altro
(supponendo che i programmi siano CPU-bound)
N.B.: La disequazione non è valida poiché i processi non sono sempre CPU-bound.
Stato del Processo
Mentre un processo è in esecuzione è soggetto a cambiamenti di stato. Ogni processo può trovarsi in uno dei seguenti stati:
Nuovo. Si crea il processo.
Esecuzione. Un'unità d'elaborazione esegue le istruzioni del relativo programma.
Attesa. Il processo attende che si verifichi qualche evento (come il completamento di un'operazione di I/O o la ricezione di un segnale).
Pronto. Il processo attende di essere assegnato ad un'unità d'elaborazione.
Terminato. Il processo ha terminato l'esecuzione.
Process Descriptor (PD) o Process Control Block (PCB)
Ogni processo è rappresentato nel S.O. da un PD detto anche PCB. Un descrittore di processo contiene molte informazioni connesse ad un processo specifico, tra cui le seguenti:
Stato del processo (nuovo, pronto, esecuzione, attesa, bloccato, ecc.)
Contatore di programma (contiene l'indirizzo della successiva istruzione)
Registri della CPU
ID Identificatore del processo
Elenco risorse assegnate al processo
File aperti
![]()
![]()
![]()
![]()
 Stack del Processo
Stack del Processo
Ad ogni processo è assegnato una porzione di memoria oltre alla quale non può andare (Spazio di indirizzamento)
Immagine del processo = Descrittore + Dati (stack del processo) + Codice
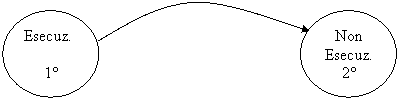
Possibili stati di un processo
![]()
Il passaggio dal 1° al 2° stato è determinato dalla scadenza del quanto di tempo (100 ms). Il passaggio dal 2° al 1° stato è effettuato dallo Scheduler.
All'interno del 2° stato vi sono processi
tali che se assegnassimo loro
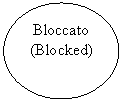
![]()
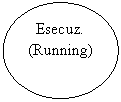




![]()

![]()
![]()
![]()
![]()
![]() Il responsabile
delle transizioni tra Running e Blocked è il S.O.
Il responsabile
delle transizioni tra Running e Blocked è il S.O.

![]()
Lo scheduler prende nella coda ready il processo con priorità più alta e lo manda in Esecuzione. Lo scheduling viene fatto solo ai processi ready. Questa attività si chiama Scheduling della CPU o di Breve Termine.

![]()




![]()



![]()
 Esisteva nei Sistemi
Esisteva nei Sistemi
Batch (Sistemi non interattivi)
non in Windows o Unix Gestito dallo Scheduler
a lungo periodo
Scheduler a Breve Termine
Lo scheduler a breve termine seleziona frequentemente un nuovo processo
per
Scheduler a Lungo Periodo
Lo scheduler a lungo periodo si esegue con una frequenza molto inferiore; tra la creazione di nuovi processi possono trascorrere diversi minuti. Lo scheduler a lungo termine controlla il grado di multiprogrammazione, cioè il numero di processi presenti nella memoria. Se il grado di multiprogrammazione è stabile, la velocità media di creazione dei processi deve essere uguale alla velocità media con cui i processi abbandonano il sistema; quindi lo scheduler a lungo termine si può chiamare solo quando un processo abbandona il sistema. A causa del maggiore intervallo che intercorre tra le esecuzioni, lo scheduler a lungo termine dispone di più tempo per scegliere un processo per l'esecuzione.
Scheduler a Medio Termine o di Memoria
Un processo pronto deve avere l'immagine in memoria primaria. Grazie alla Memoria Virtuale parte dell'immagine può stare nella memoria primaria e parte nella memoria virtuale. Se la porzione in memoria primaria è blocked non la stiamo utilizzando bene; pertanto conviene che le porzioni di immagine che sono blocked siano caricate in memoria virtuale (memoria di massa). Ciò viene fatto dallo Scheduler di Medio Termine tramite lo swapping dei processi. Al precedente schema dobbiamo aggiungere dunque due stati:
Blocked Suspend
Ready Suspend
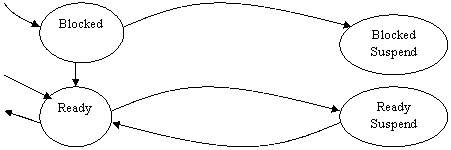
Lo scheduler difficilmente farà passare il Blocked Suspend a Blocked.
Memoria Virtuale
Opera con la paginazione, cioè ogni processo è diviso in pagine.
Processo Croce Memoria Princ. Processo Cerchio
o o o o o x x o x o x x x x x![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
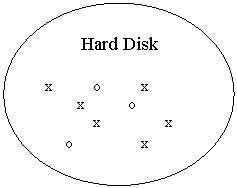
Se il programma non trova la pagina di riferimento dà al S.O. un
segnale di page fault così il S.O.
blocca l'esecuzione e carica la pagina corrispondente eliminando qualcuna più
vecchia. Se si hanno molti page fault
Multithreading
Un processo è un programma (insieme di istruzioni) in esecuzione.
Thread Programma in esecuzione che condivide parte dello Spazio d'indirizzamento.
![]()

![]()
![]()
![]()
Thread
![]()
P Processo (viene chiamato Task poiché ad esso è associato un insieme di
Thread)
P e l'insieme dei Thread ad esso associato hanno lo stesso spazio d'indirizzamento. P e P sono processi distinti che hanno spazi d'indirizzamento diversi.
Il thread è orientato alla condivisione di risorse ed è utilizzato soprattutto per avere del parallellismo nelle attività. Viene mandato in esecuzione (dunque in allocazione di memoria) un solo Task ma diversi thread, poiché ad ogni attività del processo viene associato un thread invece che allocare nuove risorse per altri processi. Tale sistema è chiamato multithreading.
Realizzazione del Multithreading
Multithreading a livello Utente
Multithreading a livello Kernel
Soluzione Mista
Il Kernel vede solo i processi. Ogni processo è realizzato con un'insieme di thread e la gestione di questi thread è fatta dal processo Utente. Il vantaggio è che non bisogna fare nessun salvataggio dello stato del Kernel, lo scheduling è realizzato senza far intervenire il Kernel. Lo svantaggio è che il Kernel non si accorge della presenza dei thread, dunque due Task che hanno diverso numero di thread vengono trattati dal Kernel in maniera equa (al Task con 1000 thread viene assegnato lo stesso tempo di utilizzo della CPU del Task con 10 thread). Un altro svantaggio è che se un thread fa una richiesta di tipo bloccante al Kernel tramite una System Call, vengono bloccati tutti gli altri thread e dunque anche lo stesso Task.
Il Kernel gestisce anche i thread che appartengono ai processi. In questo caso un thread può essere bloccato senza bloccare l'intero Task. Lo scheduling della CPU viene fatto in maniera equa, poiché un Task con più thread avrà per maggior tempo l'utilizzo della CPU. A livello Kernel il thread può essere considerato come un processo figlio.
Ha i vantaggi della soluzione 1 e 2. Ad ogni Task sono associati un certo numero di thread a livello Kernel e ad ogni thread sono associati dei LWP (Light Weight Process) cioè altri thread a livello Utente.
Utente
Multithreading a livello Utente
Kernel
P
Utente
![]()
![]()
![]()
![]() Multithreading a livello Kernel
Multithreading a livello Kernel
![]() Kernel
Kernel
P
30 20
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() Utente
Utente
![]()
![]()
 Soluzione Mista
Soluzione Mista
Kernel
![]()
![]()
3 Thread a livello Kernel gestiscono in totale 100
Thread a livello Utente
P
Ci sono due processi di scheduling, uno per i thread kernel ed uno per i thread utente. Pertanto se un thread utente fa una System Call il Kernel blocca solo il thread kernel corrispondente e non l'intero Task.
Scheduling
I parametri da considerare per la schedulazione sono:
Throughput (numero di processi che terminano nell'unità di tempo; va max.to)
Tempo di utilizzo della CPU (va max.to)
Tempo di Attesa medio nella coda ready
Tempo di risposta (va min.to)
Tempo
di turn-around (tempo che un processo deve attendere per poter
riutilizzare
Scadenze
Questi parametri sono collegati fra loro. Non possono essere soddisfatti tutti ma bisogna vedere quali privilegiare in base al S.O. Nei Sistemi Interattivi è più importante il tempo di risposta che è collegato necessariamente al tempo di attesa medio e di turn-around. Nei Sistemi Real-time sono importanti le scadenze che devono essere soddisfatte dal Sistema.
Esempi di Sistemi Real-Time:
Swapping per il controllo di processo.
Bio-informatica.
Attività Multimediali.
Scheduler
È composto da:
Gestore della coda di processi Ready.
Dispatcher.
Context Switcher.
Il Dispatcher interviene per l'individuazione del processo che deve essere eseguito; per terminare un processo; per far passare un processo da blocked a ready o da ready a blocked.
Il Context Switcher si occupa della commutazione di contesto. Il passaggio della CPU a un nuovo processo implica la registrazione dello stato del processo vecchio e il caricamento dello stato precedentemente registrato del nuovo processo. Questa procedura è nota col nome di cambio di contesto (context switch). Il contesto di un processo è descritto nel PCB di tale processo: include i valori dei registri della CPU, lo stato del processo e le informazioni di gestione della memoria. Quando si verifica un context switch, il Kernel registra il contesto del vecchio processo nel suo PCB e carica il contesto precedentemente registrato del nuovo processo scelto per l'esecuzione. Il tempo necessario al cambio di contesto è puro sovraccarico, infatti il sistema non compie nessun lavoro utile durante la commutazione, e varia da calcolatore a calcolatore secondo la velocità della memoria, il numero dei registri che si devono copiare e l'esistenza di istruzioni speciali (come un'istruzione singola di caricamento o memorizzazione di tutti i registri). Generalmente, questo tempo è compreso tra 1 e 1000 microsecondi.
Schedulazioni
Preemptive (con prelazione)
Non Preemptive (senza prelazione)
Algoritmi di Schedulazione non Preemptive
FCFS (First Come, First Served)
Approccio di tipo FIFO. I processi vengono eseguiti nell'ordine in cui arrivano.

![]()
In questo schema per minimizzare il tempo di attesa si dovrebbero
mettere alla fine i processi che sono molto pesanti per
SJF (Short Job First)
![]()
![]()
![]()
Valore stimato del
CPU-burst
Questa formula definisce una media esponenziale. Il valore di tn contiene le informazioni più recenti e denota la lunghezza dell'n-esima sequenza di operazioni della CPU; tn registra la storia passata. Il parametro a controlla il peso relativo sulla predizione della storia recente e di quella passata. Se a = 0, allora, tn+1 tn, e la storia recente non ha effetto; si suppone, cioè, che le condizioni attuali siano transitorie; se a = 1, allora tn+1 = tn, e ha significato solo la più recente sequenza di operazioni della CPU: si suppone, cioè, che la storia sia vecchia ed irrilevante. Più comune è la condizione in cui a = ½, valore che indica che la storia recente e la storia passata hanno lo stesso peso. L'algoritmo SJF può essere sia con prelazione che senza prelazione. La scelta si presenta quando alla coda dei processi pronti arriva un nuovo processo mentre un altro processo è ancora in esecuzione. Il nuovo processo può avere una successiva sequenza di operazioni della CPU più breve di quella che resta al processo correntemente in esecuzione. Un algoritmo SJF con prelazione sostituisce il processo attualmente in esecuzione, mentre un algoritmo SJF senza prelazione permette al processo correntemente in esecuzione di portare a termine la propria sequenza di operazioni della CPU.
Priorità
Ad ogni processo è assegnata una priorità.
Pi (processo) si (priorità)
Si genera pertanto una coda di
priorità in modo tale che lo schedulatore assegni
Concorrenza o Sincronizzazione
Semafori, Monitor Cap. 7 del Silberschatz ediz. 6°
Deadlock Cap. 8 del Silberschatz ediz. 6°
Gestione della Memoria
Cap. 9 e 10 del Silberschatz ediz. 6°
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2025