|
|
| |
Il World Wide Web |
Il World Wide Web (detto anche Web, WWW o W3) è nato al Cern nel 1989 per consentire una agevole cooperazione fra i gruppi di ricerca di fisica sparsi nel mondo.
E' un'architettura software volta a fornire l'accesso e la navigazione a un enorme insieme di documenti collegati fra loro e sparsi su milioni di elaboratori.
Tale insieme di documenti forma un ipertesto (hypertext), cioè un testo che viene percorso in modo non lineare. Il concetto di ipertesto risale alla fine degli anni '40, e si deve a vari scienziati:
Vannevar Bush (sistema Memex, basato su microfilm);
Douglas Engelbart (sistema NLS/Augment, basato su elaboratori interconnessi);
Ted Nelson (sistema Xanadu, con enfasi sulla tutela dei diritti d'autore: un documento poteva contenere un riferimento ad altri documenti, che venivano inclusi "al volo" in quello referente e mantenevano così la loro unicità e originalità).
Il Web ha diverse caratteristiche che hanno contribuito al suo enorme successo:
architettura di tipo client-server:
ampia scalabilità;
adatta ad ambienti di rete;
architettura distribuita:
perfettamente in linea con le esigenze di gestione di un ipertesto;
architettura basata su standard di pubblico dominio:
possibilità per chiunque di proporre una implementazione;
uguali possibilità di accesso per tutte le piattaforme di calcolo;
capacità di gestire informazioni di diverso tipo (testo, immagini, suoni, filmati, realtà virtuale, ecc.):
grande interesse da parte di tutti gli utenti.
I documenti che costituiscono l'ipertesto gestito dal Web sono detti pagine web, e possono contenere, oltre a normale testo formattato, anche:
rimandi (detti link o hyperlink) ad altre pagine web;
immagini fisse o in movimento;
suoni;
scenari tridimensionali interattivi;
codice eseguibile localmente.
L'utilizzo del Web è semplicissimo:
un utente legge il testo della pagina, vede le immagini, ascolta la musica, ecc.;
se seleziona col mouse un link (che di solito appare come una parola sottolineata e di diverso colore) la pagina di partenza viene sostituita sullo schermo da quella relativa al link selezionato.
Si noti che la nuova pagina può provenire da qualunque parte del pianeta.
Il Web è una architettura software di tipo client-server, nella quale sono previste due tipologie di componenti software: il client e il server, ciascuno avente compiti ben definiti.
Il client (o user agent) è lo strumento a disposizione dell'utente che gli permette l'accesso e la navigazione nell'ipertesto del 848d31i Web.
Esso ha varie competenze:
trasmettere all'opportuno server le richieste di reperimento dati che derivano dalle azioni dell'utente;
ricevere dal server le informazioni richieste;
visualizzare il contenuto della pagina Web richiesta dall'utente, gestendo in modo appropriato tutte le tipologie di informazioni in esse contenute;
consentire operazioni locali sulle informazioni ricevute (ad esempio salvarle su disco, stamparle).
I client vengono comunemente chiamati browser (sfogliatori). Gli esempi più noti sono:
NCSA Mosaic (il primo);
Netscape Navigator;
Microsoft Internet Explorer.
In generale è troppo complicato e costoso (sarebbero necessari aggiornamenti troppo frequenti) sviluppare un browser che sappia gestire direttamente tutti i tipi di informazioni presenti sul Web, poiché essi sono in continuo e rapido aumento.
Per questa ragione, di norma i browser gestiscono direttamente solo alcune tipologie di informazioni, quali:
testo formattato;
immagini fisse;
codice eseguibile.
Viceversa, di norma gli altri tipi di informazioni vengono gestiti in uno (o entrambi) dei seguenti modi:
consegnandoli a un programma esterno (helper) che provvederà alla corretta gestione (ad esempio, un file contenente un filmato verrà consegnato a un programma per il playback di filmati);
se il browser ha un'architettura modulare le sue funzionalità possono essere estese per mezzo di plug-in, ossia librerie di codice eseguibile specializzato che possono essere caricate in memoria secondo le necessità. In questa situazione, se il necessario plug-in è installato, il browser provvede a caricarlo e gli affida la gestione delle informazioni da trattare.
Una importante caratteristica di tutti i browser moderni è di essere multithreaded, cioè di consentire che, quando la cpu è sotto il loro controllo, si alternino fra loro multipli thread di controllo, cioè flussi di elaborazione concorrenti. Spesso si usa come sinonimo di thread il termine lightweight process.
Ad esempio, nel caso di un sistema operativo (S.O.) che offre il multitasking, si può avere una situazione come quella seguente.
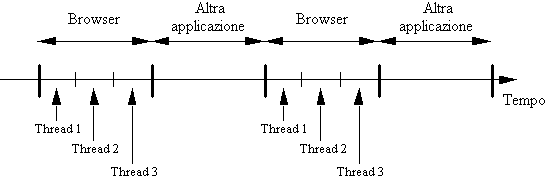
Figura 1-1: Uso della CPU in un browser multithreaded
Un thread, a differenza di un vero processo, è un contesto di esecuzione il cui spazio di indirizzamento viene ricavato all'interno di quello del processo che lo ha generato.
Il server è tipicamente un processo in esecuzione su un elaboratore. Esso, di norma, è sempre in esecuzione (tranne che in situazioni eccezionali) ed ha delle incombenze molto semplici, almeno in linea di principio. Infatti deve:
rimanere in ascolto di richieste da parte dei client;
fare del suo meglio per soddisfare ogni richiesta che arriva:
se possibile, consegnare il documento richiesto;
altrimenti, spedire un messaggio di notifica di errore (documento non esistente, documento protetto, ecc.).
Nonostante la apparente semplicità di tale compito, la realizzazione di un server non è banale, perché:
deve fare il suo lavoro nel modo più efficiente possibile, dunque deve essere implementato con un occhio di riguardo alle prestazioni;
deve essere in grado di gestire molte richieste contemporaneamente, e mentre fa questo deve continuare a rimanere in ascolto di nuove richieste.
Il secondo requisito in particolare implica una qualche forma di concorrenza nel lavoro del server. Essa si può ottenere in vari modi, anche in funzione delle caratteristiche del sistema operativo sottostante. Le due tecniche più diffuse sono descritte nel seguito.
Clonazione del server
L'idea è semplice:
per ogni nuova richiesta che arriva, il server (che è sempre in ascolto):
crea una nuova copia di se stesso alla quale affida la gestione della richiesta;
si mette subito in attesa di nuove richieste;
la copia clonata si occupa di soddisfare la richiesta e poi termina.
Le varie copie del server vivono in spazi di indirizzamento separati, e il loro avvicendamento nell'uso della CPU è governato dal sistema operativo.
Questo è un metodo tipico di S.O. multitasking quali UNIX, e si ottiene con l'uso della fork().
Vantaggi:
il codice del server rimane semplice, poiché la clonazione è demandata in toto al S.O.
Svantaggi
poiché in genere la gestione di una richiesta è piuttosto rapida, il tempo di generazione del clone può non essere trascurabile rispetto al tempo di gestione della richiesta, introducendo così un overhead che può penalizzare l'efficienza del sistema.
Server multithreaded
Esiste una sola copia del server, che però è progettato per essere in grado di generare thread multipli:
il thread principale (quello iniziale) rimane sempre in ascolto delle richieste;
quando ne arriva una, esso genera un nuovo thread che prima la gestisce e poi termina.
Questo metodo richiede che il S.O. offra librerie di supporto al multithreading, che ormai sono presenti in tutti i S.O. moderni (UNIX, Windows 95 e NT, MacOS, Linux) per cui di fatto è universalmente applicabile.
Vantaggi:
la creazione di un thread è molto più veloce di una fork() (anche 30 volte sotto UNIX), quindi in generale è più efficiente per gestire operazioni veloci come l'esaudire la richiesta del client.
Svantaggi:
il codice del server diviene un pò più complesso, perché al suo interno si dovranno gestire la creazione dei thread ed il loro avanzamento, anche in termini di sincronizzazione.
Standard utilizzati nel Web |
Ci sono tre standard principali che, nel loro insieme, costituiscono l'architettura software del Web:
sistema di indirizzamento basato su Uniform Resource Locator (URL): è un meccanismo standard per fare riferimento alle entità indirizzabili (risorse) nel Web, che possono essere:
documenti (testo, immagini, suoni, ecc.);
programmi eseguibili (vedremo poi);
linguaggio HTML (HyperText Markup Language): è il linguaggio per la definizione delle pagine Web;
protocollo HTTP (HyperText Transfer Protocol): è il protocollo che i client e i server utilizzano per comunicare.
Una URL costituisce un riferimento a una qualunque risorsa accessibile nel Web.
Tale risorsa ovviamente risiede da qualche parte, ed è in generale possibile accedervi in vari modi.
Dunque, una URL deve essere in grado di indicare:
come si vuole accedere alla risorsa;
dove è fisicamente localizzata la risorsa;
come è identificata la risorsa.
Per queste ragioni, una URL è fatta di 3 parti, che specificano:
il metodo di accesso;
l'host che detiene la risorsa;
l'identità della risorsa.
Un tipico esempio di una URL è:
https://somewhere.net/products/index.html
nella quale:
|
https:// |
è il metodo di accesso |
|
somewhere.net |
è il nome dell'host |
|
/products/index.html |
è l'identità della risorsa |
Metodo di accesso
Indica il modo di accedere alla risorsa, cioè che tipo di protocollo bisogna usare per colloquiare col server che controlla la risorsa.
I metodi di accesso più comuni sono:
|
http |
protocollo nativo del Web |
|
ftp |
file transfer protocol |
|
news |
protocollo per l'accesso ai gruppi di discussione |
|
gopher |
vecchio protocollo per il reperimento di informazioni; concettualmente simile al Web, gestisce solo testo |
|
mailto |
usato per spedire posta |
|
telnet |
protocollo di terminale virtuale, per effettuare login remoti |
|
file |
accesso a documenti locali |
Il Web nasce con l'idea di inglobare gli altri protocolli di accesso alle informazioni, per costituire un ambiente unificato che soddisfa tutte le esigenze.
Quando il client effettua la richiesta di una risorsa, usa nel dialogo col server il protocollo specificato dal metodo d'accesso. Se non è in grado di farlo, affida il compito a una applicazione helper esterna (questo è tipicamente il caso del protocollo telnet: il client lancia un emulatore di terminale passandogli il nome dell'host).
Dall'altra parte risponde il server di competenza, che può essere:
un server Web in grado di gestire anche altri protocolli;
un server preesistente per lo specifico protocollo (ftp, gopher, ecc.).
Nome dell'host
Può essere l'indirizzo IP numerico o, più comunemente, il nome DNS dell'host a cui si vuole chiedere la risorsa.
Dopo il nome dell'host può essere incluso anche un numero di port. Se non c'è, si intende il port 80 (che è il default). Ad esempio:
https://somewhere.net:8000/products/index.html
In questo modo si possono avere, sullo stesso host, diversi server Web in ascolto su diverse porte.
Identità della risorsa
Consiste, nella sua forma più completa, della specifica del nome di un file e del cammino che porta al direttorio in cui si trova.
Ad esempio, la URL:
https://somewhere.net/products/toasters/index.html
specifica il file index.html contenuto nel direttorio toasters, a sua volta contenuto nel direttorio products il quale si trova nel direttorio radice dell'host somewhere.net.
Si noti che:
la sintassi è quella di Unix;
il direttorio radice è relativo all'albero dei documenti Web, e non è necessariamente la radice dell'intero file system dell'elaboratore;
ciò fa sì che sia di fatto impossibile accedere per mezzo del Web al di fuori di tale parte del file system: il server, di norma, non consente di accedere a nulla che non sia nell'albero dei documenti Web.
Esistono alcune regole per il completamento di URL non interamente specificate:
se manca il nome del direttorio, si assume quello della pagina precedente;
se manca il nome del file (ma c'è quello del direttorio), a seconda del server:
si restituisce un file prefissato del direttorio specificato (index.html, default.html oppure welcome.html);
se tale file non esiste, talvolta si restituisce un elenco dei file nel direttorio.
Infine, una convenzione usata spesso è la seguente. A fronte di una URL del tipo:
https://somewhere.net/~username/
il server restituisce il file welcome.html situato nel direttorio public_html situato nel direttorio principale (home directory) dell'utente username.
Questo meccanismo consente agli utenti, che di norma hanno libero accesso al proprio home directory, di mantenere facilmente proprie pagine Web.
Il linguaggio per la formattazione di testo HTML è una specializzazione del linguaggio SGML (Standard Generalized Markup Language) definito nello standard ISO 8879.
HTML è specializzato nel senso che è stato progettato appositamente per un utilizzo nell'ambito del Web.
Un markup language si chiama così perché i comandi (tag) per la formattazione sono inseriti in modo esplicito nel testo, a differenza di quanto avviene in un word processor WYSIWYG (What You See Is What You Get), nel quale il testo appare visivamente dotato dei suoi formati, come fosse stampato. TROFF e TeX sono altri markup language, mentre ad esempio Microsoft Word è WYSIWYG.
Per esempio in HTML il testo:
...questo è <B>grassetto</B> e questo no...
indica che la parola grassetto deve essere visualizzata in grassetto (bold). Quindi il testo in questione dovrà apparire come segue:
...questo è grassetto e questo no...
Il ruolo di HTML è quindi quello di definire il modo in cui deve essere visualizzata una pagina Web (detta anche pagina HTML), che tipicamente è un documento di tipo testuale contenente opportuni tag di HTML.
Il client, quando riceve una pagina compie le seguenti operazioni:
interpreta i tag presenti nella pagina;
formatta la pagina di conseguenza, provvedendo automaticamente ad adattarla alle condizioni locali (risoluzione dello schermo, dimensione della finestra, profondità di colore, ecc.);
mostra la pagina formattata sullo schermo.
Nella formattazione si ignorano:
sequenze multiple di spazi;
caratteri di fine riga, tabulazioni, ecc.
I tag HTML possono essere divisi in due categorie:
tag per la formattazione di testo;
tag per altre finalità (inclusione di immagini, interazione con l'utente, elaborazione locale, ecc.).
Il linguaggio HTML è in costante evoluzione, si è passati dalla versione 1.0 alla 2.0 (rfc 1866), poi alla 3.0 e ora alla 3.2.
E' in corso una attività di standardizzazione della versione 3, che cerca di mediare le proposte, spesso incompatibili, che sono portate avanti da diverse organizzazioni (quali Netscape e Microsoft) le quali spingono perché proprie estensioni (ad esempio i frame di Netscape e gli style sheet di Microsoft) divengano parte dello standard.
In genere i tag hanno la forma:
<direttiva> ... </direttiva>
e possono contenere parametri:
<direttiva parametro1="valore"...> ... </direttiva>
Struttura di un documento HTML
Una pagina HTML ha questa struttura:
|
<HTML> <HEAD> <TITLE>...</TITLE> </HEAD > <BODY> </BODY> </HTML> |
Il ruolo di questi marcatori è il seguente:
|
HTML |
Inizio e fine del documento |
|
HEAD |
Questa parte non viene mostrata e contiene metainformazioni sul documento (creatore, data di "scadenza", e se c'è, il titolo) |
|
TITLE |
Il titolo del documento: appare come titolo della finestra che lo contiene |
|
BODY |
Il suo contenuto viene visualizzato nella finestra |
Tag per la formattazione
Alcuni dei tag esistenti per la formattazione del testo sono i seguenti:
|
<B>...</B> |
Grassetto (bold) |
|
<I>...</I> |
Corsivo (italic) |
|
<Hx>...</Hx> |
Intestazione (heading) di livello x (da 1 a 6) |
|
<PRE>...</PRE> |
Testo visualizzato esattamente come è scritto (preformatted), con spazi multipli, caratteri di fine linea, ecc. |
Ci sono moltissimi altri tag per la formattazione, coi quali si possono specificare:
dimensione, colore, tipo dei caratteri;
centratura del testo;
liste di elementi;
tabelle di testo in forma grafica (<TABLE>);
divisori (<HR>,<BR>,<P>);
colore di sfondo della pagina;
suddivisione della finestra fra più pagine (<FRAMESET>, <FRAME>).
Tag per altre finalità
Questi sono i tag che forniscono al Web la sua grande versatilità. Anch'essi sono in continua evoluzione, permettendo di includere sempre nuove funzionalità.
I tag di questo tipo più usati sono quelli per la inclusione di immagini in-line (visualizzate direttamente all'interno della pagina) e per la gestione degli hyperlink.
Il tag per la inclusione di immagini ha la seguente forma:
<IMG SRC="url"> oppure <IMG SRC="url" ALT="testo...">
Questo tag fa apparire l'immagine di cui alla URL. L'immagine (se il client è configurato per farlo) viene richiesta automaticamente e quando è disponibile viene mostrata. Altrimenti, al suo posto appare una piccola icona, sulla quale bisogna fare click se si vuole vedere la relativa immagine (che solo allora verrà richiesta), seguita dal testo specificato nel parametro ALT.
Altri parametri del tag <IMG> servono a:
specificare le dimensioni dell'immagine (WIDTH, HEIGHT);
specificare l'allineamento dell'immagine e del testo circostante (ALIGN);
specificare le aree dell'immagine sensibili ai click del mouse (ISMAP).
Tag per la gestione degli hyperlink
Costituiscono il fondamento funzionale su cui è basato il Web, perché è per mezzo di questi che si realizzano le funzioni ipertestuali.
Il tag è uno solo (con alcune varianti) e viene chiamato anchor:
<A> .....</A>
La sua forma standard è:
...<A HREF="url">testo visibile</A>...
Nella pagina la stringa testo visibile appare sottolineata e, di norma, di colore blu:
...testo visibile...
Quando l'utente fa click su un'ancora (ossia sul testo visibile della stessa) il client provvede a richiedere il documento di cui alla URL, lo riceve, lo formatta e lo mostra nella finestra al posto di quello precedente.
Il protocollo HTTP sovraintende al dialogo fra un client e un server web, ed è il linguaggio nativo del Web.
HTTP non è ancora uno standard ufficiale. Infatti, HTTP 1.0 (rfc 1945) è informational, mentre HTTP 1.1 (rfc 2068) è ancora in fase di proposta; parleremo di quest'ultimo più avanti.
HTTP è un protocollo ASCII, cioè i messaggi scambiati fra client e server sono costituiti da sequenze di caratteri ASCII (e questo, come vedremo, è un problema se è necessaria la riservatezza delle comunicazioni).
In questo contesto per messaggio si intende la richiesta del cliente oppure la risposta del server, intesa come informazione di controllo; viceversa, i dati della URL richiesta che vengono restituiti dal server non sono necessariamente ASCII (esempi di dati binari: immagini, filmati, suoni, codice eseguibile).
Il protocollo prevede che ogni singola interazione fra client e server si svolga secondo il seguente schema:
apertura di una connessione di livello transport fra client e server (TCP è lo standard di fatto, ma qualunque altro può essere usato);
invio di una singola richiesta da parte del client, che specifica la URL desiderata;
invio di una risposta da parte del server e dei dati di cui alla URL richiesta;
chiusura della connessione di livello transport.
Dunque, il protocollo è di tipo stateless, cioè non è previsto il concetto di sessione all'interno della quale ci si ricorda dello stato dell'interazione fra client e server. Ogni singola interazione è storia a se ed è del tutto indipendente dalle altre.
La richiesta del client
Quando un client effettua una richiesta invia diverse informazioni:
il metodo (cioè il comando) che si chiede al server di eseguire;
il numero di versione del protocollo HTTP in uso;
l'indicazione dell'oggetto al quale applicare il comando;
varie altre informazioni, fra cui:
il tipo di client;
i tipi di dati che il client può accettare.
I metodi definiti in HTTP sono:
|
GET |
Richiesta di ricevere un oggetto dal server |
|
HEAD |
Richiesta di ricevere la sola parte head di una pagina html |
|
PUT |
Richiesta di mandare un oggetto al server |
|
POST |
Richiesta di appendere sul server un oggetto a un altro (vedremo che si usa molto) |
|
DELETE |
Richiesta di cancellare sul server un oggetto |
|
LINK e UNLINK |
Richieste di stabilire o eliminare collegamenti fra oggetti del server |
In proposito, si noti che:
il metodo che si usa quasi sempre è GET;
POST ha il suo più significativo utilizzo in relazione all'invio di dati tramite form, come vedremo in seguito;
HEAD si usa quando il client vuole avere delle informazioni per decidere se richiedere o no la pagina;
PUT, DELETE, LINK, UNLINK non sono di norma disponibili per un client, tranne che in quei casi in cui l'utente sia abilitato alla configurazione remota (via Web) del server Web.
Ad esempio, supponiamo che nel file HTML visualizzato sul client vi sia un'ancora:
<A HREF="https://somewhere.net/products/toasters/index.html"> ..... </A>
e che l'utente attivi tale link. A tal punto il client:
chiede al DNS l'indirizzo IP di somewhere.net;
apre una connessione TCP con somewhere.net, port 80;
invia la sua richiesta.
Essa è costituita da un insieme di comandi (uno per ogni linea di testo) terminati con una linea vuota:
|
GET /products/toasters/index.html HTTP/1.0 |
Metodo, URL e versione protocollo | |
|
User-agent: Mozilla/3.0 |
Tipo del client |
|
|
Host: 160.10.5.43 |
Indirizzo IP del client |
|
|
Accept: text/html |
Client accetta pagine HTML |
|
|
Accept: image/gif |
Client accetta immagini |
|
|
Accept: application/octet-stream |
Client accetta file binari qualunque |
|
|
If-modified-since: data e ora |
Inviare il documento solo se è più recente della data specificata |
|
La risposta del server
La risposta del server è articolata in più parti, perché c'è un problema di fondo: come farà il client a sapere in che modo dovrà gestire le informazioni che gli arriveranno?
Ovviamente, non si può mostrare sotto forma di testo un'immagine o un file sonoro! Dunque, si deve informare il client sulla natura dei dati che gli arriveranno prima di iniziare a spedirglieli.
Per questo motivo la risposta consiste di 3 parti:
una riga di stato, che indica quale esito ha avuto la richiesta (tutto ok, errore, ecc.);
delle metainformazioni che descrivono la natura delle informazioni che seguono;
le informazioni vere e proprie (ossia, l'oggetto richiesto).
La riga di stato, a sua volta, consiste di tre parti:
Versione del protocollo http;
Codice numerico di stato;
Specifica testuale dello stato.
Tipici codici di stato sono:
|
Esito |
Codice numerico |
Specifica testuale |
|
|
|
|
|
Tutto ok |
|
OK |
|
Documento spostato |
|
Moved permanently |
|
Richiesta di autenticazione |
|
Unauthorized |
|
Richiesta di pagamento |
|
Payment required |
|
Accesso vietato |
|
Forbidden |
|
Documento non esistente |
|
Not found |
|
Errore nel server |
|
Server error |
Dunque, ad esempio, si potrà avere
HTTP/1.0 200 OK
Le metainformazioni dicono al client ciò che deve sapere per poter gestire correttamente i dati che riceverà.
Sono elencate in linee di testo successive alla riga di stato e terminano con una linea vuota.
Tipiche metainformazioni sono:
|
Server: ... |
Identifica il tipo di server |
|
Date: ... |
Data e ora della risposta |
|
Content-type: ... |
Tipo dell'oggetto inviato |
|
Content-length: ... |
Numero di byte dell'oggetto inviato |
|
Content-language: ... |
Linguaggio delle informazioni |
|
Last-modified: ... |
Data e ora di ultima modifica |
|
Content-encoding: ... |
Tipo di decodifica per ottenere il content |
Il Content-type si specifica usando lo standard MIME (Multipurpose Internet Mail Exchange), nato originariamente per estendere la funzionalità della posta elettronica.
Un tipo MIME è specificato da una coppia
MIME type/MIME subtype
Vari tipi MIME sono definiti, e molti altri continuano ad aggiungersi. I più comuni sono:
|
Type/Subtype |
Estensione |
Tipologia delle informazioni |
|
|
|
|
|
text/plain |
.txt, .java |
testo |
|
text/html |
.html, .htm |
pagine html |
|
image/gif |
.gif |
immagini gif |
|
image/jpeg |
.jpeg, .jpg |
immagini jpeg |
|
audio/basic |
.au |
suoni |
|
video/mpeg |
.mpeg |
filmati |
|
application/octet-stream |
.class, .cla, .exe |
programmi eseguibili |
|
application/postscript |
.ps |
documenti Postscript |
|
x-world/x-vrml |
.vrml, .wrl |
scenari 3D |
Il server viene configurato associando alle varie estensioni i corrispondenti tipi MIME. Quando gli viene chiesto un file, deduce dall'estensione e dalla propria configurazione il tipo MIME che deve comunicare al client.
Se la corrispondenza non è nota, si usa quella di default (tipicamente text/html), il che può causare errori in fase di visualizzazione.
Anche la configurazione del client (in merito alle applicazioni helper) si fa sulla base dei tipi MIME.
Tornando al nostro esempio, una richiesta del client quale:
GET /products/toasters/index.html HTTP/1.0
User-agent: Mozilla/3.0
ecc.
riceverà come risposta dal server (supponendo che non ci siano errori) le metainformazioni, poi una riga vuota e quindi il contenuto del documento (in questo caso una pagina HTML costituita di 6528 byte):
HTTP/1.0 200 OK
Server: NCSA/1.4
Date: Tue, july 4, 1996 19:17:05 GMT
Content-type: text/html
Content-length: 6528
Content-language: en
Last-modified: Mon, july 3, 1996 15:05:35 GMT
<----- notare la
<HTML>
<HEAD>
<TITLE>...</TITLE>
</HEAD >
<BODY>
</BODY>
</HTML>
Sulla base di quanto detto finora, si possono fare alcune osservazioni:
il protocollo HTTP è molto semplice, essendo basato su interazioni che prevedono esclusivamente l'invio di una singola richiesta e la ricezione della relativa risposta;
questa semplicità è insieme un punto di forza e di debolezza:
di forza perché è facilissimo, attraverso la definizione di nuovi tipi MIME e di corrispondenti funzioni sui client, estendere le tipologie di informazioni gestibili (il server non entra nel merito di ciò che contengono i file: si limita a consegnare i dati che gli vengono richiesti, senza preoccuparsi della loro semantica);
di debolezza perché queste estensioni di funzionalità talvolta mal si adattano alla concezione originaria (stateless) del protocollo, come ad esempio è il caso delle transazioni commerciali.
Estensioni del Web |
Al crescente successo del Web si è accompagnato un continuo lavoro per ampliarne le possibilità di utilizzo e le funzionalità offerte agli utenti.
In particolare, si è presto sentita l'esigenza di fornire un supporto a una qualche forma di interattività superiore a quella offerta dalla navigazione attraverso gli hyperlink, ad esempio per consentire agli utenti di consultare una base di dati remota via Web.
Le principali estensioni del Web da questo punto di vista sono:
introduzione delle form per l'invio di dati al server Web;
introduzione del linguaggio LiveScript (poi chiamato JavaScript) per la definizione di computazioni, eseguite dal client, direttamente associate a una pagina HTML;
introduzione del linguaggio Java per la creazione di file eseguibili, che vengono trasmessi dal server al client e poi vengono eseguiti in totale autonomia dal client;
Finora abbiamo sempre implicitamente considerato una URL come un riferimento ad un oggetto passivo, quale ad esempio una pagina HTML o un'immagine.
Ciò non è vero in generale, infatti una URL può fare riferimento a un qualunque tipo di oggetto, e in particolare anche a un file eseguibile.
Proprio grazie a queste generalità del meccanismo di indirizzamento URL si è definita una potente estensione Web, che lo mette in grado di integrare praticamente ogni tipo di applicazione esterna.
L'estensione di funzionalità di cui stiamo parlando è costituita da due componenti:
sul client: la possibilità di offrire, nella pagina HTML, dei moduli, detti form, per immissione di dati e un meccanismo per l'invio di tali dati al server;
sul server: un meccanismo funzionale per consegnare i dati provenienti dalla form ad una applicazione che sa gestirli, e per restituire al client gli eventuali risultati prodotti da tale applicazione.
Idealmente, la situazione è questa:
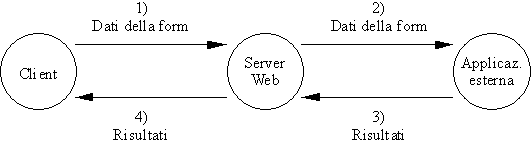
Figura 1-2: Dialogo fra cient, server Web e applicazione esterna
Ad esempio, supponiamo di avere questo scenario (che è anche il più tipico):
esiste una base dati interessante, ad esempio quella di una biblioteca;
si desidera consultarla via Web.
Immaginiamo che si voglia presentare all'utente un modulo di ricerca in biblioteca di questo tipo (in una pagina HTML):
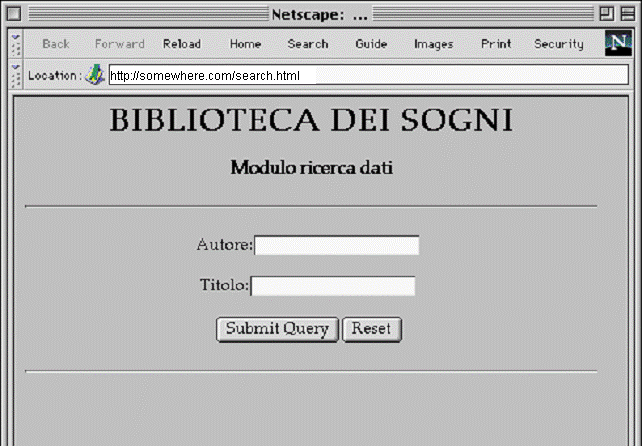
Figura 1-3: Modulo per la ricerca in biblioteca
Esistono degli appositi tag di HTML destinati a creare simili moduli. è possibile includere:
campi testo;
radio button;
checkbox;
menù a tendina.
Nel nostro caso, il codice HTML che genera il modulo sopra visto è il seguente:
|
<HTML> <HEAD><TITLE> ... </TITLE></HEAD> </BODY> <CENTER> <H1>BIBLIOTECA DEI SOGNI</H1> <H3>Modulo ricerca dati</H3> <HR> <FORM ACTION="https://somewhere.com/scripts/biblio.cgi"> Autore:<INPUT TYPE="text" NAME="autore" MAXLENGTH="64"> <P> Titolo:<INPUT TYPE="text" NAME="titolo" MAXLENGTH="64"> <P> <INPUT TYPE="submit"><INPUT TYPE="reset"> </FORM> <HR> </BODY> </HTML> |
Il tag <FORM ... > ha un parametro ACTION che specifica l'oggetto (ossia il programma) a cui il server dovrà consegnare i dati immessi dall'utente. In questo caso, vanno consegnati a un programma il cui nome biblio.cgi (vedremo poi il perché di questa estensione).
I tag <INPUT ... > definiscono le parti della form che gestiscono l'interazione con l'utente. In questo caso abbiamo:
due campi per l'immissione di testo;
due pulsanti, rispettivamente per l'invio dei dati e per l'azzeramento dei dati precedentemente immessi.
Quando l'utente preme il bottone "Submit Query" il client provvede a inviare i dati al server, assieme all'indicazione dell'URL alla quale consegnarli.
I dati vengono inviati come coppie:
NomeDelCampo1=ValoreDelCampo1&NomeDelCampo2=ValoreDelCampo2 ecc.
dove:
NomeDelCampo viene dal parametro NAME;
ValoreDelCampo è la stringa immessa dall'utente in quel campo;
le coppie sono separate dal carattere & e sono opportunamente codificate, se ci sono spazi e caratteri speciali.
La forma specifica del messaggio inviato dal client dipende anche da un altro parametro del tag FORM: oltre a ACTION=... c'è anche METHOD=... , che può essere:
GET, assunto implicitamente (come nel nostro esempio);
POST, che deve essere indicato in modo esplicito (questo è praticamente l'unico ambito nel quale è ammesso l'uso di tale comando).
Dunque, possiamo avere:
<FORM ACTION=".....">
<FORM ACTION="....." METHOD="get">
<FORM ACTION="....." METHOD="post">
Nel primo e nel secondo caso, la richiesta inviata dal client consiste nella specifica della URL alla quale vengono "appesi" i dati richiesti (con un punto di domanda):
GET /scripts/biblio.cgi?titolo=congo&autore=crichton&submit=submit HTTP/1.0
User-agent: ...
Accept: ...
<----- riga vuota
Nel caso del metodo POST, che in questo contesto è molto diffuso, i dati vengono rinviati nel corpo del messaggio:
POST /scripts/biblio.cgi HTTP/1.0
User-agent: ...
Accept
Content-type: application/x-www-form-urlencoded
Content-length
<----- riga vuota
titolo=congo&autore=crichton&submit=submit <----- dati della form
Il primo metodo è molto semplice, ma impone un limite al numero di caratteri che possono essere spediti. Il secondo invece non ha alcun limite, ed è da preferire perché probabilmente il primo verrà prima o poi abbandonato.
Quando il server riceve la richiesta, da questa è in grado di capire:
i valori forniti dall'utente;
a quale programma deve consegnarli.
Nel nostro esempio (che è un caso tipico) il programma biblio.cgi avrà l'incarico di:
ricevere i dati dal server Web;
trasformarli in una query da sottomettere al gestore della base dati;
ricevere da quest'ultimo i risultati della query;
provvedere a confezionarli sotto la forma di una pagina HTML generata al volo;
consegnare tale pagina al server che la invia al client.
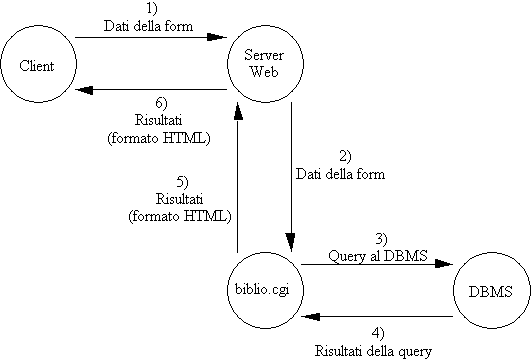
Figura 1-4: Dialogo fra cient, server Web, programma biblio.cgi e gestore della base dati (DBMS) della biblioteca
Il programma biblio.cgi del nostro esempio precedente fa da gateway fra il server Web e l'applicazione esterna che si vuole utilizzare, nel senso che oltre che metterli in comunicazione è anche incaricato di operare le opportune trasformazioni dei dati che gli giungono da entrambe le direzioni.
Da ciò deriva il nome CGI (Common Gateway Interface) per lo standard che definisce alcuni aspetti della comunicazione fra il server Web e il programma gateway, e l'uso dell'estensione .cgi per tali programmi.
Un programma CGI può essere scritto in qualunque linguaggio:
script di shell (UNIX);
Perl, TCL;
C, Pascal, Fortran, Java;
AppleScript (MacOS).
Si tenga presente che lo standard illustrato qui è di fatto relativo alla piattaforma UNIX. Per altre piattaforme i meccanismi di comunicazione previsti dalla relativa Common Gateway Interface possono essere differenti, fermo restando che le informazioni passate sono essenzialmente le stesse.
Per la comunicazione dal server Web al programma CGI si utilizzano:
variabili d'ambiente;
standard input del programma CGI (solo con il metodo POST: i dati della form vengono inviati mediante pipe).
Molte variabili d'ambiente vengono impostate dal server prima di lanciare il programma CGI; le principali sono:
|
QUERY_STRING |
La lista di coppie campo=valore (usata con il metodo GET) |
|
PATH_INFO |
Informazioni aggiuntive messe dopo l'URL (usate ad esempio con le clickable map) |
|
CONTENT_TYPE |
Usata con il metodo POST, indica il tipo MIME delle informazioni che arriveranno (application/x-www-form-urlencoded); |
|
CONTENT_LENGTH |
Usata con il metodo POST, indica quanti byte arriveranno sullo standard input del programma CGI |
In più ci sono altre variabili per sapere chi è il server, chi è il client, per la autenticazione, ecc.
Le comunicazioni dal programma CGI al server Web avvengono grazie al fatto che il programma CGI invia l'output sul suo standard output, che viene collegato tramite pipe allo standard input del server Web.
Ci si aspetta che il programma CGI possa fare solo due cose:
generare al volo una pagina HTML, che poi sarà restituita dal server al client;
indicare al server una pagina preesistente da restituire al client (URL redirection).
L'output del programma CGI deve iniziare con un breve header contenente delle metainformazioni, che istruisce il server su cosa fare. Poi una riga vuota, quindi l'eventuale pagina HTML.
Le metainformazioni che il server prende in considerazione (tutte le altre vengono passate al client) sono:
|
Metainformazione |
Valori |
Significato |
|
|
|
|
|
Content-type: |
Tipo/Sottotipo MIME |
Tipo dei dati che seguono |
|
Location: |
URL |
File da restituire al client |
|
Status: |
OK, Error |
Esito dell'elaborazione |
Ad esempio, supponendo di usare un linguaggio di programmazione nel quale sia definita una ipotetica procedura println(String s) che scrive una linea di testo sullo standard output, un programma CGI che genera al volo una semplice pagina HTML potrà contenere al suo interno una sequenza di istruzioni quale:
println "Status: 200 OK");
println("Content-type: text/html");
println(""); //linea vuota che delimita la fine delle metainformazioni
println "<HTML>");
println "<HEAD>");
println "</HEAD>");
println "<BODY>");
println "</BODY>");
println "</HTML>");
Viceversa, se il programma CGI vuole effettuare una URL redirection il codice eseguito potrà essere:
println "Status: 200 OK");
println("Location: /docs/index.html");
println(""); //linea vuota che delimita la fine delle metainformazioni
Per gli altri sistemi operativi i meccanismi di comunicazione possono essere diversi:
su Windows si usano variabili d'ambiente e file temporanei;
su MacOS si usa Applescript: le informazioni (inclusa la risposta del programma CGI) vengono passate come stringhe associate a variabili dal nome predefinito.
Dunque, la tipica catena di eventi è la seguente:
il client invia una richiesta contenente:
identità del programma CGI;
dati della form;
il server riceve i dati;
il server lancia il programma CGI e gli passa i dati;
il programma CGI estrae dai dati i valori immessi dall'utente;
il programma CGI usa tali valori per portare avanti il suo compito, che può essere ad esempio:
aprire una connessione con un DBMS (anche remoto) ed effettuare una query;
lanciare a sua volta un'altra applicazione, chiedendole qualcosa;
il DBMS (o l'applicazione) restituisce dei risultati al programma CGI;
il programma CGI utilizza tali risultati per confezionare al volo una pagina HTML, che restituisce al server;
il server invia tale pagina al client, che la visualizza sullo schermo.
Ulteriori usi del meccanismo CGI si presentano in relazione a:
server side image map;
motori di ricerca.
Server side image map
L'idea è di avere sul client un'immagine sensibile al click del mouse che possa fare da "ponte" verso nuove pagine HTML scelte sulla base del punto dell'immagine sul quale si preme il pulsante.
Sul server sono necessari:
una immagine (ad esempio, image.gif) e una pagina HTML che la contiene;
un file di testo detto mappa che definisce le parti dell'immagine sensibili al mouse (ad esempio, image.map);
un programma CGI di servizio (ad esempio, image.cgi).
Il funzionamento è il seguente:
l'utente fa click su un punto dell'immagine;
il client invia le coordinate del punto di click al server;
il server passa le coordinate al programma CGI;
il programma GCI esamina la mappa e, sulla base delle coordinate ricevute, restituisce un opportuno documento.
Supponiamo che:
l'immagine image.gif sia di 100x100 pixel;
il file image.map contenga
le linee:
rect /paginaA.html 5,5,95,45
rect /paginaB.html 5,55,95,95
Tali linee impongono la seguente struttura (invisibile) sull'immagine image.gif:
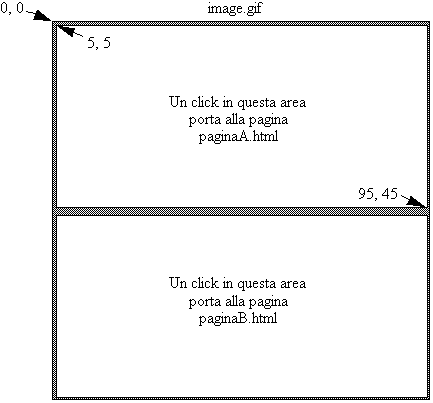
Figura 1-5: Aree sensibili definite da image.map
Nella pagina di partenza l'ancora che contiene l'immagine sensibile è del tipo:
<A HREF="image.cgi$image.map"><IMG SRC="image.gif" ISMAP></A>
Quando l'utente fa click, ad esempio, nel punto 50, 20 dell'immagine (l'origine è in alto a sinistra), il client invia la richiesta:
GET image.cgi$image.map?50,20 HTTP/1.0
Il server lancia il programma image.cgi, che riceve il nome del file di mappa e le coordinate, e quindi restituisce (tramite URL redirection) il file paginaA.html da mostrare al client.
Client Side Image Map
Recentemente è stato introdotto un nuovo meccanismo per ottenere un comportamento analogo senza bisogno di interagire col server.
Il client fa tutto da solo, poiché trova le informazioni necessarie direttamente nella pagina HTML.
In sostanza, si definisce la mappa in HTML e si dice al client di usare direttamente quella. Il caso precedente diventa:
<IMG SRC="image.gif" USEMAP="#localmap">
<MAP NAME="localmap">
<AREA COORDS="5,5,95,45" HREF="paginaA.html">
<AREA COORDS="5,55,95,95" HREF="paginaB.html">
</MAP>
Facendo click su una delle due aree, il client invia direttamente la richiesta della pagina A o B.
Per garantire la compatibilità con i client più vecchi, che non gestiscono il parametro USEMAP, si possono far coesistere le due possibilità:
<A HREF="image.cgi$image.map"><IMG SRC="image.gif" ISMAP USEMAP="#localmap"></A>
<MAP NAME="localmap">
<AREA COORDS="5,5,95,45" HREF="paginaA.html">
<AREA COORDS="5,55,95,95" HREF="paginaB.html">
</MAP>
Motori di ricerca
Esistono dei siti che offrono funzioni di ricerca di informazioni sull'intera rete Internet. In generale essi sono costituiti di 3 componenti:
un robot di ricerca, che è un programma che esplora automaticamente il Web e raccoglie informazioni sui documenti che trova (tipicamente, analizzando TITLE e HEAD). Con tali informazioni alimenta la base di dati di cui al punto successivo;
una base di dati che raccoglie i riferimenti alle pagine collezionate, con opportune strutture di indici per velocizzare le ricerche;
un CGI di interfaccia fra il Web e il programma di gestione della basi di dati, e una o più form per l'immissione dei criteri di ricerca da parte degli utenti.
1.3.3) Linguaggio JavaScript (già LiveScript) |
E' una proposta di Netscape. Consiste nella definizione di un completo linguaggio a oggetti, con sintassi analoga a Java, con il quale si possono definire delle computazioni direttamente nel testo della pagina HTML. Tali computazioni vengono poi eseguite dal browser.
Ad esempio, si può usare JavaScript per controllare che i vari campi di una form siano riempiti in modo sintatticamente corretto prima di inviare i dati al server.
Nell'esempio che segue, il bottone "submit" chiama una routine JavaScript di controllo del campo cognome. Se esso è vuoto si avvisa l'utente dell'errore, altrimenti si invia la form.
|
<HTML> <HEAD> <SCRIPT LANGUAGE="LiveScript"> function checkForm (form) else </SCRIPT> </HEAD> <BODY> <CENTER> <FORM> Cognome:<INPUT NAME="cognome" VALUE=""> <P> <INPUT TYPE="button" VALUE="Submit" onClick="checkForm (this.form);" > <INPUT TYPE="reset"> </FORM> </CENTER> </BODY> </HTML> |
L'effetto di un errore di immissione, dal punto di vista dell'utente, è il seguente:
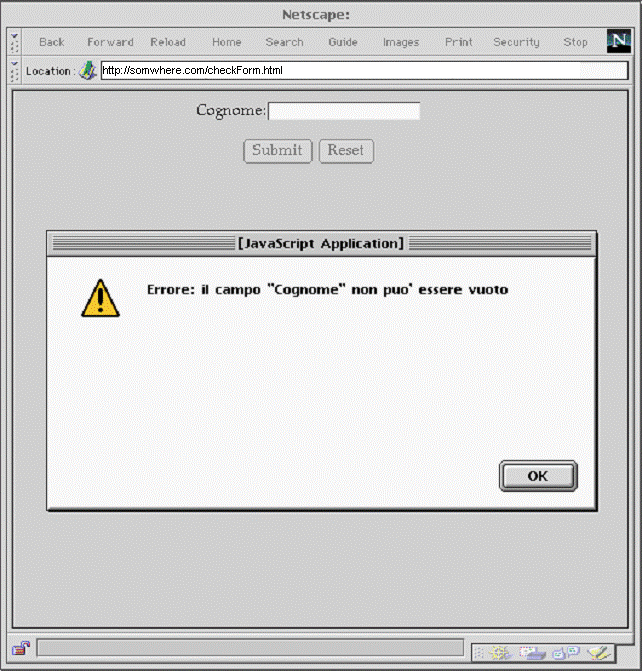
Figura 1-6: Messaggio di errore di JavaScript
Si noti che all'utente il bottone di invio sembra di tipo Submit, ma in realtà è di tipo Button, altrimenti la pressione su di esso causerebbe comunque l'invio dei dati della form.
Il linguaggio consente:
la definizione di funzioni;
la definizioni di variabili (non tipate: il tipo si deduce dall'uso);
la gestione degli eventi, fra cui:
onClick
onFocus, onBlur;
onChange;
l'accesso a tutti gli oggetti, automaticamente istanziati, relativi al contenuto della pagina;
la comunicazione bidirezionale con gli applet Java presenti nella pagina.
Gli oggetti predefiniti sono organizzati in una gerarchia i cui principali elementi sono:
Document
Anchor
Applet
Form
Button
Checkbox
Radio
Submit
Textarea
Image
Link
Ogni singolo oggetto contiene una istanza di ciascun tipo di oggetto in esso contenuto: ad esempio, un oggetto Form contiene le istanze di tutti i campi immissione dati, bottoni ecc. che sono inclusi nella form stessa.
Anche disponendo delle form e dei programmi CGI, ciò che rimane impossibile è avere una rapida interazione con la pagina Web.
Inoltre, la vertiginosa apparizione di nuove tipologie di informazioni da gestire e nuovi tipi di servizi da offrire rende problematico l'aggiornamento dei client: troppo spesso si devono ampliare le loro funzionalità o si deve ricorrere a programmi helper e plug-in.
La prima risposta a entrambi questi problemi è venuta da una proposta della Sun che ha immediatamente suscitato un enorme interesse a livello mondiale: il linguaggio Java e il relativo interprete.
Originariamente (nei primi anni '90) il linguaggio si chiamava OAK ed era destinato alla produzione di software per elettrodomestici (orientati all'informazione) connessi in rete. Era progettato per:
essere indipendente dalla piattaforma di calcolo;
consentire una esecuzione senza rischi per l'attrezzatura di destinazione.
Successivamente il progetto fu riorientato verso il Web, il linguaggio ha preso il nome di Java ed ha conosciuto un enorme successo.
L'idea di fondo è molto semplice:
una pagina Web contiene (fra le altre cose) un link a un programma scritto in Java, detto applet;
quando l'utente carica tale pagina, assieme ad essa viene recuperato il codice eseguibile (bytecode) dell'applet;
dopo essere stato caricato, del tutto o in parte, l'applet viene mandato in esecuzione sul client "dentro" la pagina HTML.
In questo modo si ottiene di fatto la possibilità di estendere senza limiti la funzionalità del Web, infatti:
se l'applet ha una finalità prettamente locale (gioco, applicazione specifica quale un word processor, tabellone elettronico, ecc.) si offre quella alta interattività che prima mancava al Web;
viceversa l'applet può costituire una estensione delle funzionalità del browser. Ad esempio, l'inventore di un nuovo formato per la compressione dati (chiamiamolo MPEG-2000) scriverà un applet per la visualizzazione degli stessi, che sarà caricato dai client quando questi dovranno accedere a tali dati.
La piattaforma di calcolo basata su Java consiste di varie componenti:
il linguaggio Java;
un compilatore da Java a bytecode;
un interprete di bytecode, ossia una macchina virtuale Java (Java Virtual Machine, JVM).
Il linguaggio
E' principalmente caratterizzato da queste caratteristiche:
general purpose;
orientato a oggetti;
fortemente tipato;
concorrente (multithreading);
privo di caratteristiche dipendenti dalla piattaforma;
dotato di caratteristiche simili a SmallTalk;
dotato di sintassi simile a C e C++.
Il compilatore
Traduce i file sorgenti scritti in Java (aventi l'estensione .java) in codice eseguibile, contenuto in uno o piu file caratterizzati dall'estensione .class.
Sono questi i file che viaggiano sulla rete e vengono caricati dai client Web per l'esecuzione.
I file .class hanno un formato indipendente dalla piattaforma:
stream di byte (8-bit);
quantità multibyte memorizzate in big-endian order.
La macchina virtuale
E' il cuore di tutto il meccanismo. Essa fornisce un dispositivo di calcolo astratto, capace di eseguire il codice contenuto nei file .class e dotato di:
un set di istruzioni macchina;
un insieme di registri, un program counter, ecc.
Si noti che attualmente i file .class si ottengono a partire da codice Java, ma questo non fa parte delle specifiche della macchina virtuale. Non è escluso che in futuro si possano usare anche altri linguaggi sorgente (con opportuni compilatori).
Per eseguire i bytecode su una macchina reale, bisogna realizzare un emulatore della macchina virtuale, il cui compito è tradurre i bytecode in istruzioni native della piattaforma HW/SW ospite.
Dunque, sono le varie implementazioni della macchina virtuale che offrono ai bytecode l'indipendenza dalla piattaforma.
Vari modi sono possibili per implementare emulatori della macchina virtuale Java:
all'interno di un client Web: in questo caso l'emulatore della macchina virtuale risiede all'interno del codice eseguibile del client;
applicazione a se stante: in questo caso il client viene configurato per usare la JVM come helper esterno (ad esempio, MS Internet Explorer può scegliere quale JVM usare);
all'interno del S.O. (per ora con Linux, a breve anche con Windows e MacOS).
Nel secondo e terzo caso, la JVM è in grado di eseguire non soltanto gli applet, ma anche applicazioni vere e proprie scritte in Java, cioè programmi del tutto autonomi che possono risiedere permanentemente sulla macchina ospite e possono essere eseguiti senza utilizzare il client Web.
Tali programmi non sono soggetti alle restrizioni imposte (per ragioni di sicurezza, come vedremo poi) agli applet.
Sono in corso di sviluppo progetti volti a realizzare un chip che implementi la JVM direttamente in hardware, con ovvi benefici dal punto di vista delle prestazioni.
Funzionamento nel Web
In una pagina HTML si fa riferimento a un applet con uno specifico tag:
<APPLET CODE="game.class" WITDH=200 HEIGHT=200></APPLET>
E' possibile fornire all'applet anche ulteriori parametri, che vengono passati all'applet al momento del lancio, quali ad esempio:
<APPLET CODE="game.class" WITDH=200 HEIGHT=200>
<PARAM NAME="level" VALUE="5">
<PARAM NAME="weapons" VALUE="none">
</APPLET>
Quando il client incontra il tag Applet:
riserva uno spazio di 200x200 pixel nella pagina;
richiede con una GET il file game.class;
quando riceve il file lo passa alla JVM (interna o esterna) che:
effettua gli opportuni controlli (come vedremo in seguito);
se è tutto OK, avvia l'esecuzione dell'applet;
mostra nello spazio riservato nella pagina (200x200 pixel nell'esempio) il contesto di esecuzione dell'applet;
provvede a richiedere (su indicazione della JVM) gli ulteriori file .class che sono necessari all'esecuzione dell'applet.
Spesso, a corredo di un emulatore di JVM è consegnato un AppletViewer, che è un programma di supporto volto a fornire alla JVM la possibilità di reperire attraverso il protocollo HTTP i file .class. In sostanza, un AppletViewer può essere visto come un client Web che sa gestire solamente il tag APPLET e ignora tutto il resto.
Il protocollo HTTP è nato con una finalità (lo scambio di informazioni fra gruppi di ricercatori) che si è radicalmente modificata col passare del tempo.
Infatti, attualmente:
il suo utilizzo si è ampliato enormemente;
si cerca di sfruttarlo anche per transazioni di tipo commerciale.
Questi due aspetti hanno messo alla frusta il protocollo soprattutto da tre punti di vista:
efficienza nell'uso delle risorse di rete;
assenza del concetto di sessione;
carenza di meccanismi per lo scambio di dati riservati.
Efficienza nell'uso della rete
Il problema di fondo è che il protocollo HTTP prevede che si apra e chiuda una connessione TCP per ogni singola coppia richiesta-risposta.
Si deve tenere presente che:
l'apertura e la chiusura delle connessioni TCP non è banale (three way handshake per l'apertura, idem più timeout per la chiusura);
durante l'apertura e la chiusura non c'è controllo di flusso;
la dimensione tipica dei dati trasmessi è piccola (pochi KByte);
TCP usa la tecnica dello slow start per il controllo di flusso.
Di conseguenza, si ha che:
il protocollo HTTP impone un grave overhead sulla rete (sono frequentissime le fasi di apertura/chiusura di connessioni TCP);
gli utenti hanno la sensazione che le prestazioni siano scarse (per via dello slow start).
Assenza del concetto di sessione
In moltissime situazioni (ad esempio nelle transazioni di tipo commerciale) è necessario ricordare lo stato dell'interazione fra client e server, che si svolge per fasi successive.
Questo in HTTP è impossibile, per cui si devono trovare soluzioni ad hoc (ad esempio, restituire pagine HTML dinamiche contenenti un campo HIDDEN che identifica la transazione).
In proposito c'è una proposta (State Management, rfc 2109) basata sull'uso dei cookies, cioè particolari file che vengono depositati presso il client e che servono a gestire una sorta di sessione.
Carenza di meccanismi per lo scambio di dati riservati
L'unico meccanismo esistente per il controllo degli accessi (Basic Authentication) fa viaggiare la password dell'utente in chiaro sulla rete, come vedremo fra breve.
HTTP versione 1.1
E' in corso di completamento la proposta, che diventerà uno standard ufficiale di Internet, della versione 1.1 di HTTP.
Essa propone soluzioni per tutti gli aspetti problematici che abbiamo citato ed introduce ulteriori novità. I suoi aspetti salienti sono:
il supporto per connessioni persistenti;
il supporto per l'autenticazione;
l'introduzione dei metodi estensibili.
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2026