|
|
| |
Supponiamo che nel censimento di una data popolazione si registrino, per ciascun individuo, i valori assunti da due diverse caratteristiche, che indicheremo genericamente come X e Y (es. peso e altezza degli abitanti di un comune, o diametro e peso di una partita di pillole prodotte in un certo giorno da una casa farmaceutica). Per ordinare i risultati di tale indagine si utilizza una variabile statistica doppia, che consiste in una tabella a doppia entrata. Sulla prima colonna si indicano i valori assunti dalla caratteristica X e sulla prima riga i valori della caratteristica Y. In generale i valori argomentali (o le classi) delle due caratteristiche saranno diverse; indicheremo con n il numero delle classi della caratteristica X e con m quello della Y. Nel seguito utilizzeremo l'indice i, crescente dall'alto in basso, come indice di riga (i=1,2,., n) e l'indice j, crescente da sinistra a destra, come indice di colonna (j=1,2,.,m). Nella generica posizione (i,j) (in corrispondenza della coppia di valori (xi,yj)) si indica la frequenza assoluta Nij o relativa fij con cui la coppia di valori (xi,yj) si presenta nella popolazione. Valgono per le frequenze assolute e relative le stesse proprieta' gia' enunciate per la variabile statistica monodimensionale. La somma di tutti gli elementi della tabella viene sinteticamente indicata tramite una doppia sommatoria, una sull'indice i e l'altra sull'indice j. Fissata una riga (i=i*), si sommano tutti gli elementi che appartengono ad essa facendo variare l'indice di colonna j, quindi si sommano i valori della riga successiva (i**=i*+1) sempre scorrendo l'indice di colonna e cosi' via.
Vediamo come si ordinano in una variabile statistica doppia i risultati ottenuti da un'indagine su una popolazione di 10 individui, sulle caratteristiche X= peso e Y=altezza, che a priori possono assumere valori reali qualsiasi:
|
x | |
|
|
|
|
|
|
|
|
1.66 222b11c |
|
|
1.66 222b11c |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Possiamo assumere come valori argomentali delle due componenti, direttamente i valori che si sono presentati, o piu' sensatamente si possono suddividere i valori in classi. In tale secondo caso assumeremo che tutti gli individui di una classse assumano il valore argomentale scelto come rappresentante la classe stessa.
Ad esempio costruiamo le classi di peso seguenti 50-59,60-69,70-79,80-89, rappresentate dai valori 55,65,75,85,95; e le classi di altezza 1.60-1.69,1.70-1.79,1.80 1.89,1.90-1.99, rappresentate dai valori centrali 1.65, 1.75, 1.85, 1.95, e trasformiamo i valori che cadono in una classe nel valore rappresentativo della classe:
|
x | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
E infine calcoliamo le frequenze relative di ciascuna coppia di valori argomentali della tabella a doppia entrata
|
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
La somma delle frequenze relative di tutte le coppie sara' pari ad 1.
![]()
Nel caso in cui la variabile assuma valori in un insieme discreto di punti, noti a priori, si puo' rappresentare graficamente il risultato dell'indagine riportando sul piano cartesiano xy le coppie di valori argomentali e in corrispondenza le frequenze relative di ciascuna coppia.
Il digramma cumulativo di frequenza in corrispondenza di ciascuna coppia di valori argomentali assumera' il valore della somma delle frequenze relative di tutte le coppie con ascissa e ordinata minori o uguali a quelle della coppia considerata.
Nel caso in cui la variabile statistica assume valori in un insieme continuo, si possono rappresentare i risultati dell'indagine tramite istogramma e funzione cumulativa di frequenza.
Sul piano xy si riporteranno rispettivamente in ascissa e in ordinata i valori delle le classi in cui sono suddivisi i valori argomentali della componente X e della componente Y della variabile doppia.
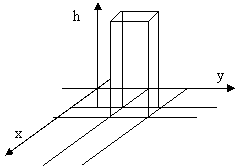
Nel caso dell'istogramma, poi, per ciascun areola Dxi Dyj si calcola l'altezza del diagramma h(xi,yj)=fij/(Dxi Dyj). Il volume di ciascun parallelepipedo con area di base Dxi Dyj e altezza hij rappresenta la frequenza degli individui che hanno valori argomentali compresi contemporaneamente nei due intervalli. La somma di tutti i volumi sara' pari a 1.


Supponiamo di voler conoscere la distribuzione di una soltanto delle due componenti nella popolazione. Nel nostro esempio si tratterebbe di ordinare in una variabile statistica monodimensionale i valori della caratteristica che interessa trascurando l'altra.
Ad esempio se ci concentrassimo sulla componente X, ovvero il peso avremmo:
|
x |
y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xi |
|
|
|
|
|
|
|
|
|
|
|
|
E analogamente potremmo ordinare la sola caratteristica y.
Vogliamo ricavare la stessa informazione, cioe' la distribuzione della caratteristica X nella popolazione a partire dalla variabile doppia in tabella.
Basta a tale scopo osservare che, ad esempio sulla riga i-esima sono registrate le frequenze relative allo stesso valore della caratteristica xi, associata al variare dell'indice j a valori diversi della caratteristica y. La somma di tutte le frequenze della riga i-esima dara' dunque la frequenza led valore xi , indipendentemente dalla caratteristica y.
In altre parole, se, a partire dai dati non ordinati, vogliamo determinare la frequenza relativa della classe di peso 65, considereremo sia l'individuo con le caratteristiche (60,1.62), che quello con (68,1.75), che infine quello con caratteristiche (60,1.60), ottenendo frequenza 0.3. Di tali individui 2 appartengono alla classe congiunta delle due caratteristiche (65,1.65), f22=0.2 e uno alla classe congiunta (65,1.75), f23=0.1. Di tale di tale distinzione non mi accorgo se ordino solo la caratteristica x, viceversa ne tengo conto se ordino sulla base delle sue caratteristiche, come nella tabella. Per annullare la distinzione sulla caratteristica y, bastera' sommare f22+f23=0.3.
Chiameremo le frequenze marginali della componente X qi, quelle della componente Y rj. Si avra'
![]() ,
, ![]() .
.
Le distribuzioni marginali sono variabili statistiche monodimensionali la cui somma delle frequenze relative e' pari a 1.
![]()
![]()
Supponiamo di voler conoscere come si distribuisca la variabile peso tra gli individui che presentano un valore di altezza pari a 1.65.
Dai nostri dati non ordinati, rileviamo che sono presenti 4 persone con altezza pari a 1.65, quelli evidenziati in tabella:
|
x |
y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
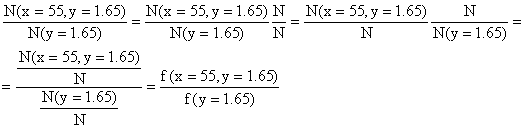
f(x=55|y=1.65)= ![]() .
.
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2024