|
|
| |
APPUNTI DI SISTEMI DI ELABORAZIONE 1
PARTE UNO
CAPITOLO UNO: Cenni introduttivi sull'architettura dei PC.................... 252e47c .................... 252e47c .................... 252e47c .............
1.1 L'architettura dei bus.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .........
1.2 L'8086 in breve.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..........
1.3 Cenni sull'implementazione dell'interrupt non mascherabile.................... 252e47c .................... 252e47c ...................
CAPITOLO DUE: Il meccanismo del DMA.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ....
2.1 Introduzione.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..........
2.2 Struttura del DMA controller.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ........
2.3 La sincronizzazione con la CPU.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .........
2.4 Ciclo del DMA.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .......
2.5 Un esempio.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..............
2.6 Modalità di trasferimento.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ...............
2.7 Un altro esempio.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ...................
2.8. Struttura dell'8237 DMA Controller.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..............
2.9. Stati di funzionamento.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ...
2.10. Registri dell'8237.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..................
2.11. DMA nell'architettura AT.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ...............
2.12 Generazione degli indirizzi.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ...............
CAPITOLO TRE: Le memorie dinamiche.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .....
3.1 La cella di memoria.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ............
3.2 I segnali principali.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ................
3.3 Cicli di memoria.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..
3.3.1 Ciclo di lettura.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..
3.3.2 Cicli di scrittura.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ...................
3.3.3 Funzionamento a pagine.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ....
3.4 Rinfresco.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................
3.4.1 Tipi di ciclo.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ........
3.4.2 Classi di rinfresco.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................
3.5 DRAM Controller.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..................
3.5.1. Rinfresco asincrono e sincrono.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ............
3.5.2 Il DRAM controller 8202.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ....
3.6 Il meccanismo di rinfresco nei primi PC.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ...........
CAPITOLO QUATTRO: rilevazione e correzione di errori nelle memorie.................... 252e47c .................... 252e47c ......
4.1 Introduzione.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ........
4.2 Determinazione dei bit di ridondanza.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ............
4.3 Parità: schema hardware di principio.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ............
4.4 Codici a blocco lineare.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .....
4.4.1 Codifica.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..............
4.4.2 Decodifica.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..........
4.4.3 Rilevazione e correzioni errori.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..............
4.5 Un metodo per ottenere un codice SEC-DED.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ...
4.6 Aspetti circuitali.................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c .................... 252e47c ..................
Vediamo lo schema a blocchi dell'architettura di un PC attuale, concentrando l'attenzione su quegli elementi che influenzano il rendimento del sistema.
Iniziamo con il distinguere 3 livelli di bus, che si riflettono poi in 3 livelli di velocità:

Figura : un livello di bus
Nei vecchi sistemi (oppure in quelli attuali più' semplici), il bus che collega la CPU alla memoria e' il bus di sistema, quello più' importante, su cui si definisce lo standard di comunicazione e dunque le prestazioni, le tempistiche, la forma del connettore (es: ISA, AT, MCA...). Questo livello, che collega la CPU con la memoria (magari passando attraverso la cache), è il più veloce, e la velocità di trasferimento è dettata dalla frequenza (esterna) della CPU e dal tipo di ciclo del bus.
Nei sistemi leggermente più' complessi, i dispositivi di I/O richiedono un canale di comunicazione separato, a velocità più bassa, e in questi casi tale canale diventa il bus di sistema.

Figura : due livelli di bus
Si hanno allora due livelli di velocità, e il bus controller deve interpretare gli indirizzi in modo da attivare la memoria oppure un dispositivo periferico.
Nei sistemi più evoluti, alcuni periferici hanno un canale privato che permette una comunicazione più veloce con la CPU. Uno di questi periferici e' il video, che deve scambiare velocemente un gran numero di informazioni con la CPU. In questo modo si hanno tre livelli: il più veloce vede la comunicazione tra memoria e CPU, quello intermedio la comunicazione tra periferici veloci e CPU, l'ultimo la comunicazione tra periferici lenti e CPU (fig. 3).
Il bus ISA è un bus di CPU "arricchito" di quei segnali utili per la gestione del sistema: questo vuol dire che, oltre ai segnali di indirizzamento (AddrBus), di trasferimento dati (DataBus) e di controllo, sono presenti altri segnali utili per il governo del sistema, in particolare i segnali per i meccanismi di DMA, di interrupt e di sincronismo per le architetture multiprocessore. Questi ultimi non sono gestiti direttamente dalla CPU, ma dai relativi controller. Il bus più vecchio, quello dell'architettura XT, portava solo i segnali di CPU, mentre dall'ISA in avanti, i segnali di sistema sono aumentati.
Piccola legenda 8282(3): latch 8286(7): transceiver 8288: bus controller 8289: bus arbiter 8255: porta parallela 8251: porta seriale (UART) 8259: Programmable Interrupt Interface
(PIC) 8237: DMA controller
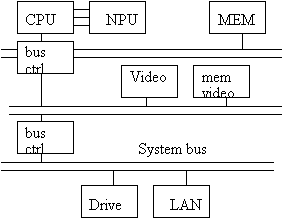
Figura : tre livelli di bus
Perché nei primi PC si è utilizzato un solo bus di sistema? Perché la velocità dei componenti che si affacciavano sul bus erano del tutto simili; i controllori 8255, 8259, 8237... hanno infatti velocità simile tra loro e simile a quella dell'8086. Con l'aumentare della frequenza dei processori, il divario di velocità è aumentato, e questo fenomeno, ancora attuale, ha portato a importanti modifiche nell'architettura del PC (memorie cache, bufferizzazione I/O, interleaving, bus dedicati...). Un altro fattore di grande importanza in questa evoluzione è stato la gestione della grafica, che nei primi PC era a carico della CPU, e questo andava bene finché le interfacce erano a caratteri; con l'avvento delle interfacce grafiche il lavoro della CPU e l'occupazione del bus sarebbe diventato eccessivo, quindi sono nati i coprocessori grafici con memoria propria, i bus locali (VESA), ecc.
Consideriamo come esempio il processore 8086. Esso ha un Address Bus di 20 bit, quindi può indirizzare fino a 1 Mbyte di memoria. In realtà i registri interni sono di 16 bit, ma con il noto trucchetto di sommare il registro Code Segment (CS) ad un registro di offset, si ottengono due vantaggi:
si ottiene un'indirizzo effettivo su 20 bit
si ottengono dei segmenti da 64Kbyte parzialmente sovrapponibili a meno di 16 byte
Con riferimento ai piedini dell'8086, notiamo le seguenti cose:
TEST : a questo piedino arriva un segnale dal coprocessore matematico (NPU 8087) che indica quando esso ha concluso un'operazione matematica
QS0,QS1: sono segnali di sincronismo tra la coda di prefetch della NPU e la coda di prefetch della CPU. Le due code, entrambe da 6 byte, sono identiche e si caricano/scaricano in modo sincrono per mantenere la corretta sequenzialità delle istruzioni;dal 286 in poi il coprocessore matematico è visto come un dispositivo di I/O, quindi non possiede più una coda di prefetch.
HOLD, HLDA: segnali di richiesta e di acknolewdge del DMA
LOCK: segnale che permette di realizzare il "test and set" in un sistema multiprocessore, rendendo l'istruzione sprcificata indivisibile (quindi non interrompibile da un altro processore)
READY: se il segnale su questo pin non è attivo, il processore si "congela" in stato di WAIT
S0, S1, S2: configurano lo stato della CPU; gli stati possibili sono 8.
|
S2 |
S1 |
S0 |
|
|
|
|
|
INTA |
|
|
|
|
Read I/O |
|
|
|
|
Write I/O |
|
|
|
|
HALT |
|
|
|
|
FETCH |
|
|
|
|
Read Mem |
|
|
|
|
Write Mem |
|
|
|
|
No bus cycle |
Siccome lo stato della CPU è legato al tipo di ciclo svolto sul bus, questi tre segnali definiscono anche il ciclo di bus. L'8288, cioè il controllore del bus, riceve questi segnali e li traduce in segnali di controllo sul bus. I segnali in uscita da questo controllore sono: il clock, l'address latch, mem read/write, I/O read/write, Interrupt Acknowledge...
Nell'8086 il ciclo di bus è composto da almeno 4 colpi di clock (più eventuali stati di WAIT tra il terzo e il quarto colpo di clock, inseriti sulla base del segnale READY).
Stato di WAIT: la CPU attende il dato dalla memoria, la quale non è pronta per rispondere
Stato di IDLE: la CPU rimane proprietaria del bus, ma tutti i segnali sono disattivati; questo capita quando la CPU non ha bisogno di cicli di bus e la coda di prefetch è piena.
Modalità del processore: minimum mode e maximum mode
Minimum mode: il numero di dispositivi che si affacciano sul bus è minimo; i segnali RD, WR e M/IO sono generati direttamente dal processore; in questa modalità non è possibile utilizzare il coprocessore matematico
Maximum mode: i segnali sono generati dal bus controller e sono più numerosi; permettono anche di interfacciare la CPU con il coprocessore matematico; la comunicazione tra CPU e NPU avviene tramite un canale apposito con un meccanismo molto simile al DMA.
A causa del bus troppo piccolo l'8086 non ha la possibilità di implementare il meccanismo del pipeline: infatti non è in grado di leggere più istruzioni in un solo ciclo. L'unica soluzione è il prefetching, che consiste nel caricare istruzioni in una coda mentre il processore è impegnato in istruzioni che non occupano il bus; il pipeline funziona bene con un processore di tipo RISC, in cui le istruzioni hanno tutte la stessa lunghezza (piccola) e impiegano lo stesso tempo per essere eseguite, mentre non funziona bene con un CISC (come l'8086), dove le istruzioni sono lunghe, di lunghezza variabile e con tempo di esecuzione variabile.
Tutti i processori INTEL hanno l'unità di controllo microprogrammata; per esempio nell'8086 le microistruzioni sono di 21 bit e ce ne sono 504; l'esecuzione di una microistruzione impiega 1 colpo di clock.
L'interrupt non mascherabile è utile per svolgere diverse funzioni:
è utilizzato per segnalare l'errore di parità sulle memorie
nell'8086 è utilizzato per segnalare errori relativi all'8087, nei PC più recenti per segnalare lo scattare del Real Time Counter, che deriva dal timer di sistema
è anche usato per segnalare l'errore di parità nelle schede di espansione di memoria
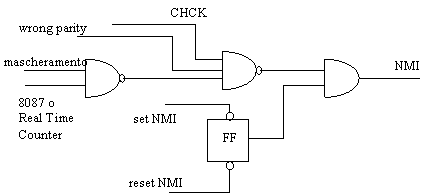
Figura : schema di principio del NMI
In fig.4 vediamo una possibile implementazione dell'interrupt non mascherabile (NMI); il filo NMI entra poi nel piedino corrispondente della CPU.
Ricordiamo che gli interrupt possono essere suddivisi in tre categorie:
Interrupt hardware: corrispondono a due pin sull'8086, INT e NMI, il primo è utilizzato dai dispositivi esterni per richiedere un servizio, il secondo è l'interrupt non mascherabile
Trap: sono interrupt attivati da situazioni anomale: divisione per zero, overflow, single step...
Interrupt software: sono attivati mediante l'istruzione INT n
Ad ogni interrupt è associato un numero compreso tra 0 e 255. Quando l'interrupt k è riconosciuto dal processore, avviene un salto alla routine il cui indirizzo è scritto nella locazione k ; al termine di questa routine deve esserci una istruzione IRET.
Il DMA non è un meccanismo per velocizzare gli I/O e non è vero che lavora in parallelo con la CPU.
Per capire il problema, vediamo un esempio pratico.
|
|
Poniamo di avere un sistema composta da una CPU a 30 Mhz, una DMA controller a 5 Mhz e che un ciclo di bus duri 2 colpi di clock (questo è vero dal 286 in poi). Nel caso in cui la CPU abbia il controllo del bus, possiamo calcolare facilmente la durata di un trasferimento: 30 Mhz = circa 1 colpo di clock ogni 30 ns, quindi in 60 ns avviene un ciclo di bus, cioè un trasferimento. |
Se il DMA prende il controllo del bus (la CPU è completamente scollegata), la velocità di trasferimento scende notevolmente: 5 Mhz = 200 ns, quindi abbiamo 400 ns per un trasferimento (in realtà, come vedremo, sono anche di più).
Come si può notare, in questo caso il meccanismo del DMA rallenta le prestazioni invece di migliorarle.
In generale vale la seguente regola: se il DMA e' veloce circa come la CPU, non è importante il parallelismo tra DMA e CPU, perché le prestazioni sono simili, indipendentemente da chi ha il controllo del bus; invece, più il DMA è lento rispetto alla CPU, più diventa importante il parallelismo tra i due: il DMA dovrebbe controllare il bus solo in quei momenti in cui la CPU è impegnata ad eseguire istruzioni che non richiedono l'utilizzo del bus. Ma questa situazione si verifica con una frequenza molto bassa.
Per illustrare il motivo per cui è stato introdotto il DMA, vediamo un altro esempio.
Nei microprocessori intrinsecamente sequenziali, come ad esempio lo Z80 o Z800, in cui la fase di fetch e quella di execute si alternano senza pausa, il rendimento è molto basso, circa lo 0,25 %
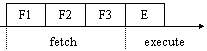
In media un'istruzione è composta da 3 byte, quindi occorrono in totale 4 cicli di bus per reperire (fetch) ed eseguire (execute) l'istruzione. I cicli di fetch sono a tutti gli effetti una perdita di tempo: il rendimento si misura in base al tempo di esecuzione, che in questo caso sta in rapporto 1/4 rispetto al tempo totale (25% di rendimento).
Il DMA cerca di migliorare questa situazione rendendo più veloci i trasferimenti, ma funziona sotto queste 2 condizioni:
si conoscono a priori l'indirizzo di lettura e di scrittura dei dati
il trasferimento non interessa la CPU, cioè non avviene elaborazione dei dati ma puro trasferimento
Vediamo un esempio di trasferimento da memoria a dispositivo I/O. Immaginiamo che il processore debba eseguire queste due istruzioni:
IN AH, indir.
MOV [BX], AX
Poniamo che occorrano 4 colpi di clock sia per il fetch che per l'execution:
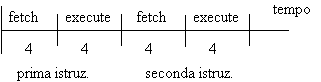
Con queste ipotesi il rendimento è del 50%, ma noi vogliamo ottimizzare il trasferimento e aumentare il rendimento. Per raggiungere tale scopo possiamo cercare di eliminare o ridurre il tempo speso nella fase di fetch.
Prima soluzione: parallelizzare fetch e execute:
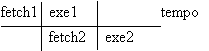
Questa soluzione è impraticabile sul PC perché abbiamo 1 solo bus. Inoltre le durate del fetch e dell'execute raramente sono identiche.
Seconda soluzione: utilizzare una coda di prefetch. Questa tecnica funziona solo quando ci sono istruzioni la cui esecuzione è più lunga della fase di fetch e che non richiedono l'utilizzo del bus (istruzioni tipo MOV AX,BX; MUL AX,3...). Durante l'esecuzione, infatti, la CPU può leggere e caricare nella coda l'istruzione successiva. Tutti i processori, dall'8086 in poi, hanno in effetti una coda di prefetch.
Esiste una terza soluzione, che ora vediamo, considerando il caso di un trasferimento da dispositivo di I/O a memoria (il discorso vale anche per il trasferimento contrario).
L'operazione di trasferimento dati da dispositivo I/O a memoria è composta da questi passi:
1- indirizzamento del periferico
2- trasferimento di n byte per ciclo di bus
3- incremento dell'indirizzo di memoria
4- se il trasferimento non è terminato ritorna al passo 2
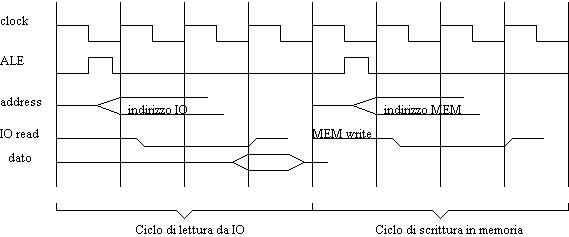
Figura : tempisitca di un trasferimento da I/O a memoria
Immaginiamo di eseguire le due istruzioni presentate poco fa e che implementano un trasferimento di un byte da I/O a memoria. La prima istruzione viene eseguita nel primo ciclo, che supponiamo duri 4 colpi di clock (così avviene effettivamente con l'8086). Alla fine del primo ciclo, nel registro AH si trova il byte letto. La seconda istruzione viene eseguita nel secondo ciclo, anch'esso di 4 colpi di clock. Alla fine del secondo ciclo, il byte è stato scritto in memoria.
Un eventuale terzo ciclo (per leggere il byte successivo) risulta identico al primo ciclo, perché l'indirizzo e i segnali di controllo sono i medesimi. Il seguente quarto ciclo differisce dal secondo solo nell'indirizzo di memoria, che sarà incrementato di uno.
Questo significa che la generazione di questi cicli può essere affidata a un dispositivo a cui basta sapere l'indirizzo di partenza da cui leggere, l'indirizzo di partenza su cui scrivere e il numero di byte da trasferire; in altre parole tale dispositivo deve replicare una parte delle funzionalità della CPU, in particolare la produzione di questi cicli di trasferimento, e non deve fare alcuna elaborazione sui dati; una volta programmato, può quindi lavorare in modo indipendente dalla CPU. Il dispositivo di cui parliamo è appunto il DMA controller.
Il DMA controller deve produrre i due cicli di fig.5, identici a quelli prodotti dalla CPU; in effetti il DMA controller è un chip molto simile alla BIU (Bus Interface Unit) incorporata nella CPU ed ha praticamente il medesimo comportamento. Il meccanismo di generazione degli indirizzi è piuttosto semplice, dal momento in cui è sufficiente un normale contatore.
L'indirizzo del dispositivo di I/O da cui leggere o su cui scrivere i dati, può essere cablato nel DMA controller, visto che si presuppone che tale indirizzo non cambi durante la vita di un PC, oppure programmato all'avvio del PC dal BIOS. Lo stesso discorso vale per l'indirizzo di memoria. Il numero di cicli da eseguire può essere fissato all'inizio del trasferimento, in modo che il DMA sappia quando interrompere la comunicazione.
Il DMA deve ricevere una richiesta (DMA request) da un dispositivo di I/O indicante che ha qualcosa da trasferire, e deve potergli fornire una risposta (DMA acknolewdge), per comunicargli che può iniziare il trasferimento.
Deve poter generare i segnali necessari per comandare il bus, e quindi l'AddressBus, il DataBus, il Mem read/write e l'I/O read/write (vedi fig.6).
MEM Read MEM Write

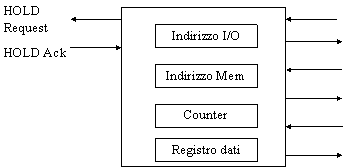
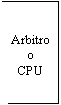

Figura : struttura di un DMA controller
Inoltre, deve essere in grado di sincronizzarsi con la CPU per il controllo del bus: deve poter segnalare alla CPU il desiderio di utilizzare il bus (Hold request) e ricevere da questa una risposta (Hold acknowledge). Infine, deve possedere un registro dati temporaneo in cui vengono memorizzati i dati in fase di trasferimento.
L'arbitro del bus deve informare il DMA e la CPU sul momento in cui possono connettersi al bus per prenderne il controllo. Entrambi i dispositivi sono collegati all'AddressBus, al DataBus e ai principali segnali di controllo, e questo significa che tali collegamenti sono fatti tramite tristate che permettano lo scollegamento di uno dei due master bus.
La sequenza di eventi che anticipa una trasferimento DMA è la seguente:
programmazione del DMA (all'avvio o cablata)
arrivo al DMA della richiesta da un device I/O (Dma request)
richiesta di controllo del bus da parte del DMA all'arbitro (Hold request)
arrivo dell'ack da parte dell'arbitro (Hold acknowledge); nota: la CPU può essere interrotta tra un ciclo di bus e un altro, quindi il DMA controller attende al più per un tempo pari ad un ciclo di bus
invio dell'ack al device I/O (DMA acknowledge)
Inizio trasferimento
Da questo momento la tempistica del bus è quella del DMA, attualmente molto più lento delle CPU di oggi. Se durante il trasferimento DMA, la CPU esegue istruzioni che non coinvolgono il bus (raro!) abbiamo parallelismo perfetto; normalmente invece la CPU si ferma e aspetta di tornare in possesso del bus.
Il DMA controller deve ottenere il bus entro un certo intervallo di tempo (latenza del DMA), altrimenti rischia di perdere il dato proveniente dall'I/O. D'altra parte, quando il DMA è attivo, la CPU è totalmente bloccata, non "sente" neanche gli interrupt (latenza della CPU).
Normalmente l'arbitro fa parte della CPU e questo spiega la presenza di segnali di arbitraggio che escono da tante CPU commerciali. Occorre notare che le richieste per l'utilizzo del bus possono arrivare anche da dispositivi diversi dal DMA controller, per esempio da un altro microprocessore, perché si tratta di un meccanismo generico per l'arbitraggio del bus. Per esempio, l'8086 ha 2 segnali, cioè 2 canali, di DMA bidirezionali, invece l'80x86 ha 2 segnali monodirezionali. L'8086, a differenza dei successori, presenta 2 segnali bidirezionali perché deve tener conto anche del coprocessore matematico, oltre che del DMA controller, e quindi sono 3 i soggetti che possono prendere il controllo del bus.
Ritorniamo alla fig. 5, dove sono raffigurati i due cicli di bus necessari per il trasferimento di byte da dispositivo di I/O alla memoria. I due cicli (prima lettura e poi scrittura) possono essere compattati in 1 solo, ma solo a certe condizioni. Notiamo che il DataBus potrebbe mantenere i dati durante tutte e due le fasi senza problemi; i segnali di controllo sono differenti nelle due fasi (I/O read e MEM write), quindi non c'è conflitto; l'unico problema è l'AddBus, che prima deve contenere l'indirizzo di lettura e nella seconda fase quello di scrittura. La soluzione consiste nell'indirizzare il dispositivo di I/O con un segnale diverso, in modo da occupare l'AddBus solo con l'indirizzo di memoria. In altre parole, dal DMA controller deve uscire un segnale che va a selezionare il dispositivo da cui si leggono i dati (il discorso è naturalmente invertibile: sul dispositivo di I/O si scrive e si legge dalla memoria).
In questo modo il registro temporaneo per i dati presente nel DMA controller non serve più: i dati da trasferire sono messi sul DataBus dal dispositivo di I/O e da qui la memoria li preleva. Vengono utilizzati solo più il registro contenente l'indirizzo di memoria verso il quale scrivere (o dal quale leggere) e il registro contenente il numero di cicli da effettuare. Questo implica un vantaggio: siccome il registro per i dati ha la capacità di un byte (ci riferiamo all'8237, DMA controller dell'INTEL che studieremo tra poco), senza questa soluzione si potrebbe trasferire solo un byte per ogni ciclo; invece utilizzando il DataBus come una sorta di registro temporaneo, il parallelismo di trasferimento che abbiamo è quello del DataBus stesso. In fig. 7 si vedono i due cicli di fig. 5 compattati in uno solo.
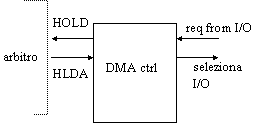
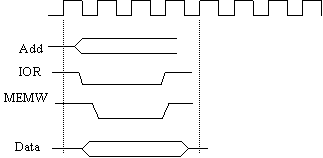
Figura : trasferimento in modalità "compattata"
Consideriamo un floppy drive e la sua interfaccia.
Poniamo che l'interfaccia presenti un nuovo byte ogni 10 microsecondi e che occorra 1 microsecondo per trasferire tale byte in memoria.
Durante i 9 microsecondi rimanenti, la CPU riprende il controllo del bus e prosegue con l'elaborazione:
![]()
Siccome la richiesta del DMA viene soddisfatta alla conclusione di un ciclo di CPU, il tempo di latenza può essere di 1 microsecondo oppure di diversi microsecondi, se il ciclo è particolarmente lungo. Se la latenza aumenta troppo, il byte che si presenta all'interfaccia del drive viene perso, e il meccanismo di DMA non funziona più. Se invece del drive abbiamo un dispositivo più veloce, il tempo di latenza è sottoposto a limiti ancora più severi.
Per ovviare a questo problema si può ricorrere alla bufferizzazione dell'I/O:

Per mezzo di un buffer i dati sono disponibili immediatamente, e i cicli di DMA possono susseguirsi uno dopo l'altro:
![]()
Poniamo che il buffer sia di 512 byte; questo significa che sono possibili 512 cicli di DMA consecutivi; siccome abbiamo supposto che un ciclo duri 1 microsecondo, il DMA detiene il controllo del bus per 0,5 ms. Durante questo intervallo di tempo la CPU è completamente inattiva e ciò significa che non sente nemmeno gli interrupt non mascherabili.
Occorre allora trovare un compromesso tra i due estremi, e dimensionare il buffer in modo da impedire la perdita dei dati, ma contemporaneamente non lasciare inattiva la CPU per troppo tempo.
In relazione alla fig.8, possiamo notare come la tempistica del bus cambi quando il DMA controller inizia il suo ciclo. Il segnale di select è quello che seleziona il dispositivo di I/O coinvolto nel trasferimento. Occorre sottolineare che tale segnale deve essere emesso sia dal DMA controller che dalla CPU, affinché quest'ultima abbia la possibilità di programmare il dispositivo (e per far questo deve selezionarlo e scrivere nei suoi registri).
Il ciclo del DMA è diverso dai 4 tipici cicli di bus (I/O read e write, Mem read e write) in cui un solo segnale di controllo è attivo: qui i segnali attivi contemporaneamente sono 2 (IO Read e MEM write), e per di più uno dei due soggetti del trasferimento è indirizzato in modo particolare.

Figura : confronto tra tempisitica della CPU e tempistica del DMA
Questo modo di indirizzare i dispositivi di I/O comporta la presenza di un certo numero di fili che escono o entrano dal DMA controller, in particolare:
m fili per l'AddBus (2m indirizzi)
n fili di select (n dispositivi di I/O)
n fili di richiesta dai dispositivi al DMA controller
Qui a sinistra è
raffigurato un DMA controller con 4 canali; ciascuno di essi è dotato di
registro di indirizzo, registro di dato (utile solo nel caso di
trasferimento memory-to-memory, come vedremo più avanti), di un registro di
numero di ciclo. Per ogni canale si hanno un segnale di richiesta dal
dispositivo di I/O e un segnale di selezione (o acknowledge). Nel DMA
controller è presente anche un sistema di arbitraggio a priorità per
gestire le eventuali richieste multiple da parte dei dispositivi di I/O.
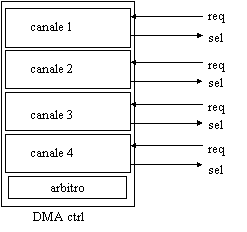
Figura : DMA controller a 4 canali
Esistono fondamentalmente due tipi di cicli di DMA:
trasferimento single byte : i cicli di DMA sono uniformemente distribuiti nel tempo. Per ogni byte avviene la richiesta del DMA, l'acquisizione del bus da parte del DMA, il trasferimento del byte e infine il rilascio del bus alla CPU.
trasferimento burst o block mode : il cicli di DMA sono raggruppati a blocchi. Ogni tanto il DMA acquisisce il bus e lo mantiene per un certo numero di cicli consecutivi. Tale numero può essere fissato a priori oppure può dipendere da un altro segnale (per esempio dal segnale di req del dispositivo di I/O interessato)
Questo significa che il
dispositivo di I/O genera un byte con una frequenza abbastanza bassa,
quindi il tempo di latenza del DMA non è critico.
Il
primo tipo di trasferimento è compatibile con dei dispositivi relativamente
lenti; poniamo che occorrano n cicli
per completare il trasferimento. Questi cicli sono "annegati" più o
meno uniformemente nei cicli di CPU:
Nel secondo caso,
invece, i cicli di DMA avvengono consecutivamente; il tempo di latenza del
DMA è mediamente minore ma se il dispositivo di I/O non è abbastanza veloce
molti cicli di DMA vanno sprecati: il DMA controller esegue il ciclo ma non
c'è nessun dato pronto da trasferire. DMA

![]()
![]()
Si utilizzano allora degli I/O bufferizzati per rendere compatibili le due velocità. Bisogna anche considerare che i trasferimenti burst allungano il tempo di latenza della CPU.
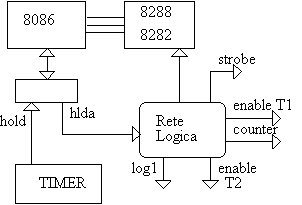
Immaginiamo di avere un display a 7 segmenti composto da 16 cifre, una buffer di 16 byte in cui sono scritti i 16 codici da mandare al display, un 8086, un 8282 e un 8288 . Davanti al display abbiamo una rete logica che si occupa di attivare il display in modo opportuno. Nostro scopo è quello di progettare un meccanismo di DMA per inviare i dati dalla memoria al display (vedi fig.10).
Siccome le prime 3 cifre dell'indirizzo sono costanti, mentre l'ultima varia da 0 a F, conviene generare l'indirizzo affiancando il numero CF0 (costante) ad un numero crescente ottenuto mediante contatore (vedi fig. 11).
Per scrivere il dato sul display è sufficiente collegare il Data Bus uscente dall' 8288 all'ingresso della rete logica del display.
Ora occorre progettare un ciclo di DMA in cui tutti i segnali necessari vengono attivati. Per quanto riguarda la tempistica, posso utilizzare un timer programmato in modo da attivare il segnale di Hold request (HOLD) ogni N microsecondi (vedi fig. 12).

Figura : architettura del sistema in esempio

Figura : generazione dell'indirizzo tramite counter
Dopo un certo tempo la CPU risponde attivando il segnale di Hold Acknowledge (HLDA), il quale entra in una rete logica; questa deve forzare l'8288 e l'8282 a scollegarsi dal bus, qualora non fossero già scollegati; in seguito deve aprire il tristate T1 collegato al counter; inoltre deve attivare il segnale di strobe del display e generare il segnale di controllo Mem Read (mediante i segnali Log1 e Enable T2).
|
Figura |
|
A questo punto, la CPU è scollegata, sull'Address bus è presente l'indirizzo di memoria da leggere, i segnali di controllo Strobe e Mem Read sono attivati, quindi avviene il trasferimento di dati dalla memoria al display.
Come ultima operazione, la rete logica segnala al counter di incrementarsi di un'unità.
Questo chip dell'INTEL ha 4 canali indipendenti, quindi è formato da 4 blocchetti base come già mostrato in fig. 9. Ogni canale ha una priorità : dal canale 0 con massima priorità al canale 3 con minima priorità.
Funziona a 5 Mhz e può arrivare ad un transfer rate di 1.6 Mb al secondo.
Il chip ha 4 modi operativi:
Single transfer: attiva un solo ciclo di DMA e poi restituisce il bus alla CPU
Block mode: attiva un numero di cicli continuativi pari a un numero preprogrammato
Demand mode: continuare a produrre cicli fintanto che il segnale di richiesta (DMA req) proveniente dal dispositivo rimane attivo
Memory-to-memory: permette il trasferimento di blocchi di memoria da un'area a un'altra aerea. Nota bene: in questo caso un solo ciclo non è sufficiente (come in fig. 7) perché ho due indirizzi di memoria differenti: occorrono due cicli; inoltre è necessario utilizzare il registro temporaneo per mantenere il valore letto tra il primo e il secondo ciclo: questo significa che per trasferire un dato composto da più di un byte, è necessario eseguire un trasferimento block mode
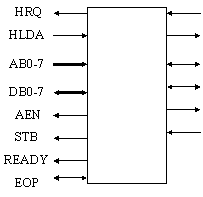
Segnali principali (vedi fig. 13):
DREQ0-DREQ3: Dma Request; sono utilizzati dai dispositivi esterni per richiedere all'8237 un servizio di DMA.
DACK0-DACK3: DMA Acknowledge; l'8237 notifica ai periferici esterni di aver ricevuto la richiesta DREQ e di essere in grado di svolgere il servizio di DMA
HRQ: Hold Request; l'8237 richiede il controllo del bus alla CPU
HLDA: Hold Acknolewedge; la CPU segnala di aver rilasciato il bus
IOR: IO Read bidirezionale munito di tri-state; la CPU legge lo stato dell'8237 oppure l'8237 legge da un dispositivo di I/O durante un trasferimento
IOW: IO Write bidirezionale munito di tri-state; la CPU modifica lo stato dell'8237 oppure l'8237 scrive in un dispositivo I/O durante un trasferimento
MEM/R: Mem Read munito di tri-state; l'8237 legge da una locazione di memoria durante un trasferimento
MEM/W: Mem Write munito di tri-state; l'8237 scrive in una locazione di memoria durante un trasferimento
DB0-7 : DataBus bidirezionale munito di tri-state; e' un canale a 8 bit collegato con il data bus del sistema
AB0-7: e' un canale monodirezionale a 8 bit collegato all'address bus del sistema. Per inviare un indirizzo a 16 bit si usano anche gli 8 pin del data bus (multiplexati), sui quali passano gli 8 bit più alti. Questo implica la presenza di latch esterni per memorizzare metà dell'indirizzo.
AEN: Address Enable; ordina agli altri dispositivi (oltre alla CPU) che si affacciano sul bus di staccarsi dal bus e abilita i latch per memorizzare gli 8 bit alti dell'indirizzo
ADS: Address Strobe; indica ai latch il momento in cui l'indirizzo è stabile
EOP (oppure TC, Terminal Count): End of Process bidirezionale; indica il completamento di un trasferimento di DMA (il contatore interno ha terminato il conteggio) su uno dei 4 canali; questo segnale viene mandato all'8259. Nota che è bidirezionale: un segnale in input su questo pin ordina la sospensione dei cicli di DMA attivi
READY: è utilizzato per allungare i cicli di Read e Write in memoria in modo da adattarsi alle memorie o ai dispositivi I/O lenti (per esempio si può collegare al pin READY della CPU)
NOTA: siccome il data bus è a 8 bit, il modo "memory-to-memory" diventa inefficiente in quei sistemi con parallelismo superiore agli 8-16 bit, perché occorrono più cicli per trasferire il singolo dato attraverso il registro interno del DMA Controller.
![]()
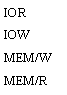
Figura : segnali dell'8237
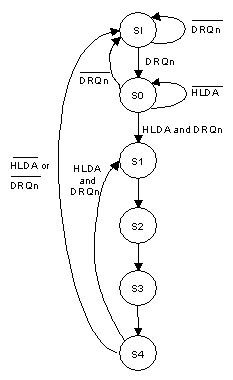
Studiando il diagramma a stati che segue, e sapendo che ogni stato dura in colpo di clock, si può dedurre che:
il trasferimento di un singolo byte dura 6 colpi di clock
il trasferimeno di n byte dura 6+(n 3 colpi di clock, cioè 6 colpi di clock per il primo byte e 3 colpi di clock per ogni successivo byte; bisogna però tener conto che ogni 256 trasferimenti gli 8 bit alti dell'indirizzo cambiano, e questo introduce una perdita di tempo pari a 4 colpi di clock
Nel caso di trasferimento da memoria a memoria:
il trasferimento di un singolo byte dura 10 colpi di clock
il trasferimeno di n byte dura 10+(n 6 colpi di clock, cioè 10 colpi di clock per il primo byte e 6 colpi di clock per ogni successivo byte; anche in questo caso si perdono 4 colpi di clock ogni 256 trasferimenti
Questo calcolo è valido trascurando i tempi di latenza e se non occorre introdurre cicli di wait tra uno stato e l'altro.
|
|
SI : Stato di IDLE Se nessun DMA Request è attivo, rimane in SI; se uno dei DMA Request si attiva, il controller attiva l'Hold Request e passa in S0 S0 : Se Hold Ack non è attivo, rimane in S0;se DMA Request si disattiva, ritorna in SI; se Arriva l'Hold Ack e DMA Request è ancora attivo, passa in S1. S1 : il controller si impadronisce del bus, manda l'indirizzo di memoria sull'Address Bus, attiva il filo di DMA Ack verso il dispositivo di IO. S2 e S3 : emette i segnali di IO e MEM S4 Disattiva il DMA Ack e testa i pin DRQn e HLDA. Se entrambi sono attivi, allora ritorna in S1, dando inizio a un nuovo ciclo di DMA. Se uno dei due non è attivo, ritorna nello stato di IDLE. NOTA : Ogni stato dura 1 colpo di clock |
|
|
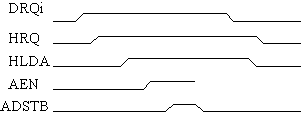
L'attivazione di DRQi provoca l'attivazione di HRQ. Quando la CPU risponde con HLDA, l'8237 alza AEN e ADSTB, che serve a registrare nel latch 8282 gli 8 bit alti dell'indirizzo. (Vedi anche Fig.8 su data sheet dell'8237.) |
Per ogni canale del DMA ci sono 6 registri:
1) Current Address Register : memorizza l'indirizzo corrente della cella di memoria alla quale accedere.
2) Current Word Register : contiene il numero di cicli ancora da svolgere o già svolti (in pratica è un contatore up/down).
3) Base Address e 4) Base Word : sono utili nella funzione di auto-inizializzazione del DMA. Qui vengono memorizzati l'indirizzo di partenza e il numero di cicli da compiere; se la funzione di auto-inizializzazione è attivata, al termine di un trasferimento i registri 1) e 2) vengono automaticamente caricati con i valori dei registri 3) e 4); in questo modo non si perde tempo nella riprogrammazione dei registri 1 e 2.
5) Command : memorizza la configurazione e la modalità operativa del controller
6) Request : il trasferimento memory-to-memory viene attivato settando un particolare bit all'interno di questo registro (un bit per ogni canale)
Inoltre è presente un registro di stato che indica quale canale ha generato l'EOP e alcuni registri di mascheramento per disabilitare i canali.
Nell'architettura AT abbiamo due DMA controller in cascata. Ciascuno ha 4 canali, di cui alcuni predefiniti e altri liberi. Siccome uno dei canali del primo DMA controller serve per il collegamento in cascata con il secondo DMA controller, ci sono 7 canali disponibili, di cui 3 sono prefigurati per modalità specifiche:
Ch 0 : attualmente libero (sugli XT era dedicato al refresh delle memorie dinamiche)
Ch 1 : SDLC : dedicato, sui PC IBM, alla gestione delle schede di comunicazione sincrona
Ch 2 : trasferimento da/verso Floppy Controller
Ch 3...7 : liberi
Il primo DMA controller ha un parallelismo ad 8 bit per compatibilità verso i controllori di floppy disk che sono a 8 bit. Invece il secondo ha un parallelismo a 16 bit.
Come abbiamo visto, all'interno del DMA controller sono presenti registri contenenti gli indirizzi per la scrittura o lettura di dati. Generalmente la dimensione di questi registri è inferiore a quella dell'Address Bus del sistema. Per fissare le idee, poniamo di avere un registro con dimensione di 16 bit, mentre l'Address Bus è composto da 20 fili. Questo significa che abbiamo una certa libertà nel mappare i 16 bit del registro sui 20 bit di indirizzo; se per esempio li facciamo corrispondere ai primi 16 bit di indirizzo, cioè A0-A15, avremo una granularità di un byte; se invece li facciamo corrispondere ai segnali da A1 a A16, avremo una granularità di una WORD. Nel primo caso avremo quindi un trasferimento a byte (incrementando l'indirizzo di 1 passiamo al byte successivo), nel secondo un trasferimento a WORD (incrementando l'indirizzo di 1 saltiamo un byte).
Abbiamo detto che, escludendo la modalità memory-to-memory, la dimensione del dato da trasferire è ininfluente per il DMA controller, ed è limitata solo dalla dimensione del Data Bus.
I bit più alti dell'indirizzo, cioè nel primo caso quelli che vanno da A16 a A19 e nel secondo caso quelli che vanno da A17 a A19, sono memorizzati in un registro apposito chiamato Page Register.
Es: N=20, M=16
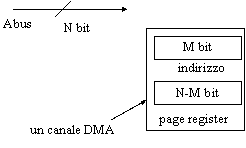
indirizzo: bit da 0 a 15 page register: bit da 16 a 19
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Figura : generazione degli indirizzi
In una memoria dinamica l'informazione è conservata in un condensatore che può trovarsi carico o scarico: a queste due condizioni si associano i due valori logici alto e basso. La carica nel condensatore permane solamente per un tempo limitato a causa delle inevitabili dispersioni e, quindi, se essa non è ripristinata al suo valore iniziale prima che assuma dei valori troppo piccoli, si ha la perdita dell'informazione associata a tale carica.
Attualmente le DRAM presentano delle celle costituite da un solo transistor MOS, oltre al condensatore, per la conservazione dell'informazione: questo ha permesso di raggiungere dei gradi di integrazione molto elevati. Questo implica altri due vantaggi: un basso costo e una limitata occupazione di spazio.
Nel disegno a sinistra
abbiamo lo schema semplificato di una cella di DRAM, composta da un
condensatore C e da un transistor MOS; la carica contenuta in C dipende
dall'informazione presente nella cella. Quando la riga viene selezionata si
apre il transistor e la carica del condensatore viene portata sulla linea
di dato (colonna).
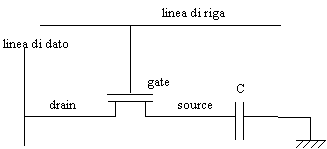
Figura : schema di una cella elementare di DRAM
Le celle di una DRAM, come quelle di qualunque altra memoria a semiconduttore, sono organizzate a matrice di m righe ed n colonne. In una memoria da 8 Kbit, per esempio, sono presenti 128 righe e 64 colonne. Ciascuna colonna presenta anche un sense amplifier dimensionato in modo tale che la tensione presente sulla linea di dato possa farlo commutare in uno dei due possibili stati di funzionamento. Nel momento in cui le celle di una riga vengono selezionate, ogni linea di dato assume una tensione pari a quella presente sul condensatore, tensione che sarà intermedia tra quella di riferimento, poniamo pari a 0 V, e quello massima, poniamo pari a 5 V. Ogni sense amplifier, scatenando una reazione positiva, si porterà in brevissimo tempo in uno dei due stati di funzionamento, forzando il valore di tensione sulla linea dati a 0 V o a 5 V, a seconda del valore di tensione iniziale, più vicino a 0 V o a 5 V. Di conseguenza anche il condensatore, che in quel momento è collegato direttamente alla linea di dato, assume la sua stessa tensione: si è quindi eseguita automaticamente un'operazione di rinfresco su tutte le celle della riga selezionata.
Nelle RAM dinamiche l'indirizzamento è eseguito in 2 passi: prima è selezionata la riga, poi occorre aspettare che il sense amplifier amplifichi il valore delle celle in quella riga, infine si seleziona la colonna. Questo significa che i bit di indirizzo non sono necessari tutti contemporaneamente: è possibile allora fornire in un primo tempo l'indirizzo relativo alla riga, che sarà opportunamente memorizzato, e successivamente quello relativo alla colonna. In particolare, se la DRAM presenta 2N celle, e quindi l'indirizzo ha un parallelismo N, sono sufficienti N/2 fili per selezionare prima una riga e poi una colona. Questo complica un po' l'hardware di gestione, ma riduce il numero di piedini necessari.
Ci sono due segnali di controllo importanti:
Row Address Strobe (RAS): indica alla DRAM che l'indirizzo di riga è valido (attivo basso)
Column Address Strobe (CAS): indica alla DRAM che l'indirizzo di colonna è valido (attivo basso); inoltre attiva i buffer dati di ingresso/uscita
Inoltre sono presenti i segnali di WRITE, che indica il tipo di operazione svolta, di DIN e DOUT, che portano il dato in scrittura o lettura.
Due buffer, uno in ingresso e l'altro in uscita, permettono il collegamento della memoria con i bus di sistema; in particolare il buffer di uscita può essere posto nello stato di alta impedenza.
Un ciclo di lettura inizia con l'invio dell'indirizzo di riga sull'Address Bus e con la successiva attivazione del segnale di RAS.
La DRAM memorizza l'indirizzo di riga e lo manda al decodificatore di riga, il quale individua la riga interessata e l'attiva.
A questo punto sono inviati i bit relativi all'indirizzo di colonna e viene attivato il segnale di CAS. Nota bene: i circuiti interni della DRAM prendono in considerazione tale segnale solo quando sono state svolte tutte le precedenti attività e non nel momento in cui viene attivato. Questo significa che il CAS può essere attivato con un certo grado di libertà.
Una volta che tale segnale è preso in considerazione dalla memoria, questa procede alla lettura della colonna selezionata, e il dato letto viene mandato sull'uscita e qui bufferizzato; nota bene: non viene posto immediatamente sul DataBus. Infatti, prima di poter eseguire una successiva operazione, il segnale di RAS deve rimane inattivo per un certo tempo non trascurabile, paragonabile circa al tempo in cui è stato attivo.
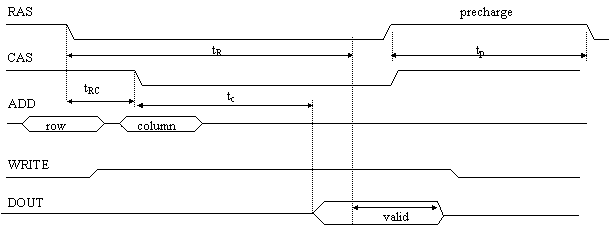
Figura ciclo di lettura
tR: tempo che intercorre tra il segnale di RAS e il momento in cui i dati sono validi.
tc: tempo che che intercorre tra il segnale di CAS e il momento in cui i dati sono disponibili.
tRC: tempo che che intercorre tra il segnale di RAS e quello di CAS
tp: tempo di precarica dei sense amplifier
Nota che i dati in uscita possono risultare disponibili prima che siano validi; anche se è passato un tempo pari a tRC+tC dalla discesa del RAS, i dati sono validi solo dopo che è passato un tempo pari a tR dalla discesa del RAS; in definitiva occorre considerare il più grande tra questi due tempi: questo sarà il tempo di accesso.
Inoltre il tempo di accesso è differente dal tempo di ciclo: il primo indica il tempo che intercorre tra l'attivazione del RAS e la validità dei dati validi sull'uscita, il secondo è il tempo che passa tra due cicli di memoria successivi. Siccome occorre aspettare la precarica del sense amplifier, il tempo di ciclo risulta essere circa il doppio del tempo di accesso. Per esempio, se abbiamo una memoria da 70 ns, possiamo accedervi ogni 140 ns circa.
Il dato letto rimane memorizzato in un buffer finché non è terminato il periodo di precarica; solo in quell'istante il dato viene posto sul DataBus, la CPU dunque lo legge e avvia un nuovo ciclo. Anche se la CPU potesse leggere il dato prima, comunque non potrebbe attivare un nuovo ciclo di memoria perché questa è inattiva.
Per capire meglio questo aspetto, consideriamo un processore 8086 interfacciato con una memoria DRAM senza interleaving. Sappiamo che l'8086 impiega 4 colpi di clock per ogni ciclo di bus; immaginiamo che un ciclo di memoria duri complessivamente 240 ns.
Durante questo ciclo la
CPU compie 4 colpi di clock, e questo significa che ogni colpo di clock
dura almeno 240:4=60 ns. Ciò equivale a dire che la CPU deve avere una
frequenza non superiore a 16 Mhz, se non vuole introdurre cicli di WAIT.
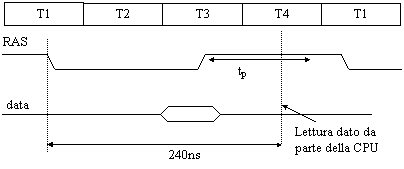
Figura : esempio di lettura
Al giorno d'oggi una DRAM media ha un tempo di ciclo di 140 ns (tempo di accesso di 70 ns), e questo significa che il nostro processore non dovrebbe avere una frequenza superiore a 30 Mhz, se non vuole introdurre cicli di WAIT. Bisogna considerare però che i processori dal 286 in poi impiegano 2 colpi di clock per ciclo, e questo implica che se vogliono comunicare con una RAM da 140 ns senza introdurre cicli di WAIT, devono avere una frequenza non superiore a 14 Mhz.
Invece i processori attuali hanno frequenze di gran lunga più grandi, quindi sono costretti a introdurre molti cicli di WAIT che abbassano parecchio le prestazioni.
Per evitare questo problema esistono varie strade, tra cui citiamo:
interleaving di banco, che consiste nel partizionare la memoria in banchi, in modo tale che l'accesso non avvenga quasi mai 2 volte successive sullo stesso banco
DRAM con funzionalità PAGE MODE
utilizzo di memoria CACHE
A differenza della lettura, l'operazione di scrittura può avvenire con modalità diverse a seconda della sequenza con cui sono forniti i segnali di controllo CAS e WRITE.
Anche questa operazione, comunque, inizia con l'attivazione del segnale RAS, il quale deve rimanere attivo per l'intera durata dell'operazione.
Il primo caso che vediamo è il ciclo EARLY WRITE, in cui il segnale WRITE è attivato prima del CAS.
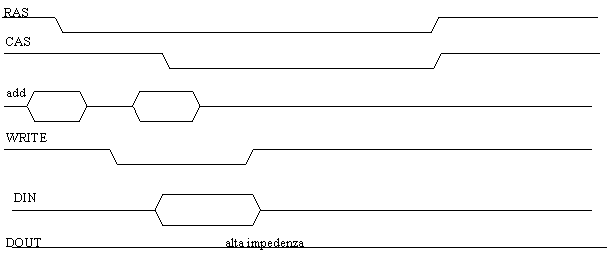
Figura : ciclo di scrittura Early Write
Dopo l'attivazione del RAS deve essere attivato il WRITE e successivamente il CAS, con il quale si seleziona la colonna interessata. Nel momento in cui il CAS scende, il dato presente sulla linea di ingresso DIN viene trasferito trasferito all'opportuna linea dati all'interno della memoria.
E' importante notare che in questo caso il buffer di uscita si trova sempre nello stato di alta impedenza e quindi, se si usa tale tipo di ciclo, è possibile collegare entrambe le linee DIN e DOUT ad un bus dati bidirezionale.
Comunque anche in questo ciclo è necessario un periodo di inattività del RAS prima di poter riprendere una qualsiasi operazione con la memoria.
E' anche possibile attivare il segnale di WRITE dopo che è stato attivato il CAS, essendo sempre attivo il RAS. Questo ciclo prende il nome di READ-MODIFY-WRITE (vedi fig.19).
Tale ciclo inizia in modo analogo ai precedenti: si attivano gli indirizzi di riga, si attiva il segnale di RAS e poi il CAS, lasciando inattivo il WRITE. In questa situazione ci si trova nelle stesse condizioni del ciclo di lettura: il contenuto della cella selezionata viene reso disponibile all'uscita DOUT.
Solo quando è attivo il segnale WRITE si procede alla scrittura del dato presente all'ingresso DIN nella cella selezionata.
Chiaramente, con questo tipo di ciclo, non si possono collegare entrambe le linee DIN e DOUT al Data Bus, perché si verrebbe a creare un corto circuito.
E' possibile, con un adatto hardware esterno, selezionare la cella, procedere alla lettura del dato, eventualmente eseguire delle modifiche, ed inviare il risultato all'ingresso DIN per riscriverlo nella stessa cella.
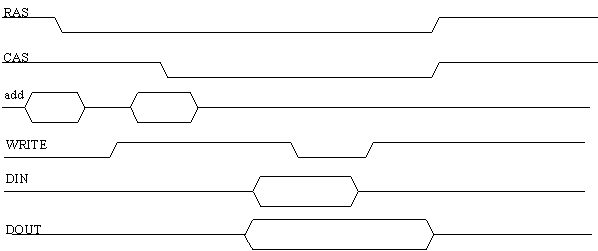
Figura : ciclo di scrittura Read_Modify_Write
La struttura a matrice e l'organizzazione interna delle memorie dinamiche permettono anche un altro modo di funzionamento, sia in fase di lettura che di scrittura, che prende il nome di funzionamento a pagine (PAGE MODE).
Come si è già visto, nelle DRAM, una volta selezionata una riga, i dati ad essa relativi sono tutti disponibili; questo significa che non occorre operare una nuova selezione della stessa riga per accedere a un altro dato di quella riga. In altre parole, dopo aver selezionato la riga interessata, si può attivare e disattivare più volte il CAS selezionando colonne differenti, e in tal modo accedendo a dati differenti senza dover aspettare un nuovo ciclo. Il segnale di RAS deve rimanere attivo durante tutta l'operazione a pagine; esiste però un limite superiore che riguarda il tempo in cui il RAS può permanere attivo, passato il quale deve forzatamente rimanere inattivo per un minimo periodo di tempo dato dalle specifiche della DRAM. Inoltre anche il segnale di CAS deve rispettare un piccolo tempo di inattività tra un'operazione e la successiva.
La possibilità di operare a pagine si rivela molto utile quando si deve fare un trasferimento di dati tra aree di memoria diverse, ad esempio utilizzando la tecnica del DMA. D'altro canto la gestione delle pagine complica parecchio il circuito.

Figura : ciclo in Page Mode
In figura 20 è rappresentato un ciclo di lettura in modalità a pagine.
La modalità a pagine ha delle varianti che tendono a migliorare le prestazioni del ciclo; una di queste è denominata ENHANCED PAGE MODE: il suo scopo è quello di contrarre il tempo di inattività del CAS, riducendo quindi i tempi morti e rendendo più veloce il ciclo; questo effetto lo si è ottenuto migliorando i microcircuiti che gestiscono questo segnale, e a fronte di un incremento di prestazioni di circa il 20%, si ha un prezzo maggiore.
Un altro tipo di soluzione è denominata STATIC COLUMN, in cui il segnale di CAS rimane attivo per tutta la durata del ciclo e dunque non esistono più i tempo morti; questo risultato si ottiene bufferizzando i dati di tutta una riga nel momento in cui il CAS si attiva; da quel momento fino alla fine del ciclo i dati della pagina sono accessibili con la stessa modalità delle memorie statiche, che non hanno bisogno di un segnale di strobe ad ogni variazione di indirizzo.
Un'ultima variante è il NIBBLE MODE, una sorta di page mode ridotto, in cui vengono letti/scritti 4 bit adiacenti; se per esempio abbiamo una DRAM da 256 Kb, immaginiamo di dividerla in 4 sottomatrici; quando arriva l'indirizzo di una riga, quella riga è selezionata contemporaneamente sulle 4 sottomatrici, mentre l'indirizzo di colonna seleziona una colonna su una sola delle 4 sottomatrici; commutando l'indirizzo di colonna otteniamo 4 indirizzi, e quindi possiamo leggere 4 bit differenti mantenendo sempre attivo il RAS, come nel page mode.
Le tecniche di page mode diventano efficienti quando è rispettato il principio di località, cioè i dati richiesti si trovano ad indirizzi adiacenti.
In una memoria dinamica occorre periodicamente procedere all'operazione di rinfresco, in caso contrario si ha la perdita dell'informazione immagazzinata. Sia nel ciclo di scrittura che di lettura, una volta selezionata la riga, è sufficiente mantenere a livello alto la linea della riga per avere automaticamente il ripristino della carica originale nei condensatori presenti su tutta la riga.
Per effettuare il rinfresco è quindi sufficiente fornire l'indirizzo della riga ed attivare il solo ingresso RAS. Questo tipo di ciclo prende il nome di RAS ONLY.

Figura : ciclo di rinfresco RAS ONLY
Ogni riga deve essere rinfrescata ogni n millisecondi, dove n in media ha un valore compreso tra 2 e 4. Siccome è sufficiente selezionare le righe, i cicli di rinfresco sono tanti quante sono le righe, e devono avvenire tutti in un tempo inferiore a, poniamo, 4 ms. Se la matrice è formata da 222 celle, quindi da 211 righe e 211 colonne, occorrono 2048 cicli di refresh in 4 ms, e quindi almeno un ciclo ogni 1953 nanosecondi (un ciclo RAS ONLY può durare circa 100 ns).
Siccome il refresh coinvolge solo il segnale RAS e non il CAS, il bus dati non prende assolutamente parte all'azione di rinfresco, e quindi è libero di svolgere altri compiti in parallelo. Tutte le tecniche di progetto per i sistemi che utilizzano DRAM devono rendere il più trasparente possibile l'operazione di rinfresco in modo che questa non influenzi troppo le prestazioni.
Per ottenere gli indirizzi di riga in successione è sufficiente utilizzare un contatore ciclico, con modulo pari al numero di righe della memoria.
Oltre al ciclo RAS ONLY, esistono altri due cicli per il rinfresco della memoria; il primo che vediamo è denominato HIDDEN: il ciclo di refresh viene inserito mentre la CPU sta decodificando un'istruzione, subito dopo averla prelevata dalla memoria. Concluso il normale ciclo di lettura dell'istruzione, il segnale di CAS non si disattiva come dovrebbe, ma rimane attivo, mentre il RAS si disattiva per segnalare la conclusione del ciclo di lettura. Successivamente, il segnale di RAS torna attivo e in quel momento si innesca un ciclo di refresh: viene generato un indirizzo di riga e lo si attiva, rinfrescandolo (vedi fig.22). Un contantore di riga viene incrementato e la riga corrispondente rinfrescata ogni volta che il RAS cambia stato, mentre il CAS è sempre attivo. Durante questo tempo, la DRAM ignora quello che succede sui bus esterni e i dati letti appena prima del refresh rimangono disponibili nei buffer di uscita per tutto il periodo di refresh.
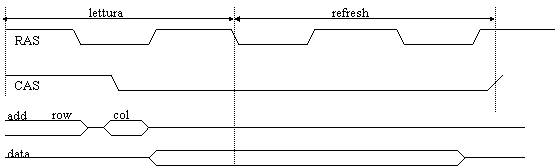
Figura : ciclo di rinfresco Hidden
Questo tipo di ciclo può essere utilizzato solo con CPU relativamente lente, per cui il tempo che intercorre tra il momento in cui si hanno i dati validi e il momento in cui la CPU ha finito di interpretarli è sufficientemente ampio per inserire cicli di refresh.
Un'altra possibilità è il ciclo denominato CAS-BEFORE-RAS. In questo caso il segnale di CAS si attiva (scende) in corrispondenza di un intervallo in cui il RAS è inattivo; successivamente, mentre il CAS è attivo, il RAS commuta, e con questo segnale la DRAM genera automaticamente e internamente un indirizzo di riga da rinfrescare.

Figura : ciclo di rinfresco CAS_Before_RAS
Durante il rinfresco, il segnale DOUT è in alta impedenza.
Il vantaggio di questi due metodi rispetto al RAS ONLY consiste nella maggiore velocità di esecuzione, ottenuta grazie alla generazione interna degli indirizzi, ma d'altro canto si ha una maggiore complessità circuitale e di controllo, perché si tratta di cicli anomali.
A fronte dei tipi di ciclo di rinfresco esaminati, è possibile fare un ulteriore classificazione, che riguarda la distribuzione di tali cicli nel tempo. Distinguiamo tra:
Burst refresh
Distributed refresh
Transparent (o hidden) refresh
Per capire meglio, immaginiamo di avere una DRAM da 1 Mbyte, quindi composta da 1024 righe e da 1024 colonne; supponiamo inoltre che ogni riga debba essere rinfrescata ogni 4 ms, e che il tempo necessario per rinfrescare una riga sia di 100 ns. Questo significa che per rinfrescare tutte le righe occorre un tempo complessivo di 100 ms, che è un intervallo di tempo più piccolo dei 4 ms massimi disponibili.
Allora esiste una certa libertà nella distribuzione dei cicli di rinfresco all'interno dei 4 ms. Una prima soluzione è il Burst Refresh, che consiste nell'eseguire il rinfresco di tutte le righe in un colpo solo.

Durante il rinfresco la DRAM non è disponibile, e questo significa che la CPU non è in grado di accedere alla memoria per un tempo relativamente lungo; d'altra parte questo meccanismo è particolarmente semplice: è sufficiente predisporre un contatore che ogni 4 ms attivi il Burst Refresh.
Un'altra soluzione è quella di distribuire il rinfresco lungo tutto l'intervallo di 4 ms, suddividendolo in piccole porzioni uguali: si ottiene il Distributed refresh.
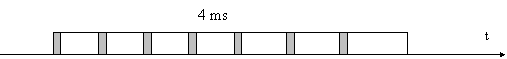
In questo modo non ci sono più i problemi di latenza della CPU, ma naturalmente la gestione è più complicata, soprattutto perché si tratta di arbitrare gli accessi alla memoria da parte della CPU e gli accessi per esigenze di rinfresco.
La parallelizzazione degli accessi in memoria da parte della CPU e del meccanismo di rinfresco, è la base per il Transparent refresh, in cui si cerca di incidere il meno possibile sulle prestazioni del sistema, eseguendo il rinfresco nei momenti in cui la DRAM non è richiesta dalla CPU.
Sono due le tecniche principali per ottenere questo risultato, tecniche che non sempre è possible applicare, perché dipendono fortemente dal tipo di sistema si cui si lavora.
La prima sfrutta i tempi in la CPU esegue operazioni interne, la seconda utilizza cicli di accesso ad altri banchi di memoria o a dispostivi di I/O.
La prima soluzione va bene solo se il processore è lento e non esegue prefetch; in questo caso infatti, il tempo necessario per l'interpretazione della corrente istruzione è sufficiente per eseguire un ciclo di refresh. Per esempio lo Z80, dopo ogni ciclo di fetch, preleva l'indirizzo della riga da rinfrescare da un suo contatore interno a 7 bit ed esegue il rinfresco, mentre la CPU interpreta l'istruzione.
Nelle CPU attuali non è possibile utilizzare questa tecnica perché le velocità sono aumentate molto e non sono più compatibili con le tempistiche delle DRAM; inoltre esiste il prefetching, quindi i cicli di bus in cui la CPU è IDLE sono molto rari.
La seconda soluzione consiste nell'eseguire il refresh di un banco di memoria in parallelo all'accesso a un altro banco. Immaginiamo, per esempio, di avere una memoria divisa in 2 banchi, uno di ROM che contiene il codice da eseguire, e uno di DRAM; supponiamo inoltre di essere sicuri che la frequenza di accesso alla ROM per eseguire i fetch sia sufficientemente alta. In questa situazione è possibile attivare un ciclo di refresh RAS ONLY (il quale non carica il bus) sulla DRAM ogni volta che avviene un accesso alla ROM.
La logica che si occupa di gestire e controllare gli accessi alla DRAM può essere contenuta in un chip apposito, e in questo caso abbiamo un DRAM controller, oppure realizzata in logica sparsa.
In linea di principio, lo schema che occorre realizzare è quello presentato in fig.24.
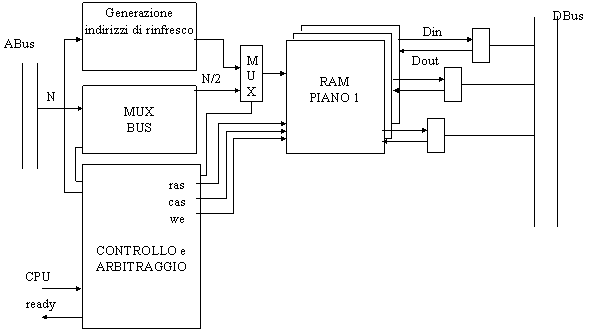
Figura : scema a blocchi di un DRAM controller
Per semplicità immaginiamo di avere un solo banco di DRAM contenente 2N celle, il quale è diviso in un numero di piani pari al parallelismo della memoria (per esempio 16 bit). L'indirizzo proveniente dall'Address Bus è quindi su N bit; tale indirizzo entra in un multiplexer comandato dall'unità di controllo, che seleziona prima N/2 bit per l'indirizzo di riga e successivamante N/2 bit per l'indirizzo di colonna. Questi N/2 bit entreranno in un decoder (interno alla DRAM) che selezionarà una ben precisa riga (e poi colonna). L'unità di controllo si occupa inoltre di attivare al momento opportuno i segnali RAS e CAS, oltre al segnale di lettura/scrittura WE; deve anche controllare i buffer, i quali ricevono il dato in uscita o in ingresso alla memoria, tramite segnali di strobe.
La logica di controllo deve però gestire anche il problema del rinfresco. Occorre quindi un contatore [0-N/2] che generi gli indirizzi di rinfresco, i quali devono andare alla memoria come quelli "normali"; quindi occorre un multiplexer controllato dall'unità di arbitraggio, la quale decide quando inserire cicli di rinfresco rispetto ai normali cicli. L'unità di arbitraggio, pertanto, riceve da una parte richieste dalla CPU per l'accesso alla DRAM, dall'altra ha un timer che indica quando è il momento di eseguire refresh; gestisce queste due richieste dando priorità al rinfresco, quindi abilita il contatore e genera un ciclo di rinfresco oppure genera un ciclo di lettura/scrittura.
Il segnale READY indica alla CPU che la memoria è disponibile oppure occupata in un ciclo di rinfresco; nel secondo caso la CPU può allungare il ciclo di bus in corso introducendo WAIT STATE.
Immaginiamo di avere 4 banchi da 256Kb per un totale di 1 Mb di DRAM; ogni banco è composto da 8 chip (piani) da 256Kx1 e ad ogni banco arrivano gli stessi segnali di controllo.




RAS3 CAS3 CAS2 RAS2 RAS0 RAS1
Ad ogni piano del banco 0 arrivano i segnali RAS0 e CAS0, ad ogni piano del banco 1 arrivano i segnali RAS1 e CAS1, e così via. Durante il ciclo di rinfresco conviene porre su tutti e 4 i fili di RAS lo stesso indirizzo e attivare tutti i banchi, in modo da rinfrescare in solo ciclo una riga di ogni banco. Questo comportamento è molto differente rispetto all'accesso normale alla memoria, quindi l'unità di controllo deve impostare in modo differente non solo la tempistica ma anche i segnali.
Generalmente si utilizza un solo filo di CAS per tutti i banchi, perché in effetti solo il banco che ha ricevuto il segnale di RAS reagisce (il RAS funge un po' da Chip Select).
L'accesso alla DRAM da parte della CPU (o altri dispositivi) e il meccanismo di rinfresco, sono due "processi" che si contendono un un'unica risorsa: la memoria. Occorre quindi arbitrare in qualche modo questi due processi, stabilendo certe priorità.
Nel rinfresco asincrono, i due processi sono totalmente svincolati e indipendenti: nel momento in cui un timer scatta, l'arbitro deve bloccare la CPU e attivare il ciclo di rinfresco entro un tempo che deve essere minore del periodo di rinfresco. Si ha quindi una latenza, cioè l'intervallo di tempo che passa dall'istante in cui il timer scatta e l'istante in cui inizia effettivamente il ciclo di rinfresco; questa latenza è critica: non rispettarla significa rischiare di perdere il contenuto della memoria.
Nel rinfresco sincrono, il processo di rinfresco viene schedulato dalla CPU (o più in generale dal bus master) come qualunque altro processo, ma possiede il più alto livello di priorità, quindi la sua schedulazione può interrompere altri processi in corso.
Questo controller è in grado di gestire tre tipi di refresh:
asincrono con generazione interna del segnale
asincrono con generazione esterna del segnale
sincrono
Nei primi due casi la temporizzazione delle richieste di refresh è indipendente da quello che sta facendo la CPU; quando è necessario eseguire il rinfresco (il segnale può essere generato dal controller stesso o provenire da altro dispositivo), il controller manda la richiesta all'arbitro, il quale comunica alla CPU di porsi in attesa, introducendo cicli di WAIT. Nel terzo caso, invece, il rinfresco è eseguito sincronizzandosi con l'attività della CPU, quindi avviene quando la CPU non accede al banco interessato dal rinfresco.
L'8202 deve controllare la memoria, e infatti possiamo notare nella figura seguente i segnali di RAS, CAS e WE generati dal controller, il quale è in grado di gestire 4 banchi di RAM da 16Kbyte ciascuno.
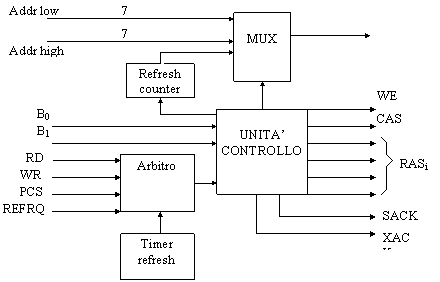
Figura : schema a blocchi dell'8202
Il multiplexer riceve il normale indirizzo della cella a cui la CPU vuole accedere (diviso in indirizzo alto per selezionare la riga e indirizzo basso per la colonna), oppure l'indirizzo della riga da rinfrescare, generato da un refresh counter. I segnali B0 e B1 fanno parte dell'indirizzo di memoria e servono per indirizzare uno dei 4 banchi; ogni banco riceve un segnale di RAS separato,che funge anche da "chip select", mentre il CAS è unico.
L'arbitro riceve i segnali di controllo che indicano la natura del ciclo (RD o WR), l'attivazione della memoria (PCS), e l'eventuale richiesta esterna di un ciclo di refresh asincrono (REFRQ). La richiesta può anche essere interna, generata da un timer refresh apposito.
L'unità di controllo genera i segnali SACK (System acknowledge) e XACK (Transfer acknowledge), con i quali il controller comunica alla CPU se la memoria è disponibile oppure occupata in un ciclo di rinfresco.
In particolare:
SACK: indica alla CPU l'inizio di un ciclo di memoria
XACK:indica il momento in cui i dati sono validi (lettura) o sono stati scritti in memoria (scrittura)
Se la CPU tenta di accedere alla memoria durante un ciclo di rinfresco, il segnale SACK è ritardato fino a che XACK non si attiva; in questo modo si comunica alla CPU che la memoria non è disponibile.
Come abbiamo visto, il rinfresco è un processo che accede alla memoria in parallelo alla CPU, con i relativi problemi di arbitraggio. L'idea "furba", soprattutto perché economica, è stata quella di sfruttare un elemento già presente nel PC, che è in grado di agire in sincronia con il lavoro della CPU: tale elemento è il DMA. Ricordiamo che durante il ciclo di DMA la CPU è totalmente scollegata dal bus, quindi non può accedere alla DRAM.
Lo schema implementato nei primi PC, contemplava l'uso del DMA controller 8237 e del timer 8253.
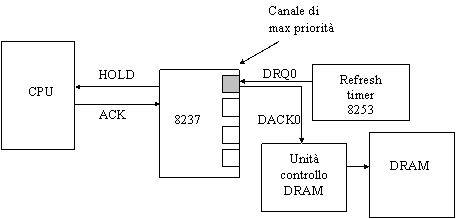
Figura : rinfresco realizzato mediante DMA
Si possono utilizzare i registri di indirizzo e il contatore interni dell'8237 per tener traccia delle righe rinfrescate (è sufficiente la parte alta del registro di indirizzo). Il refresh timer è implementato utilizzando il contatore 8253: il suo canale n.0 è utilizzato per richiedere al DMA, tramite il canale 0 a massima priorità, di attivare il ciclo di rinfresco. Nota che il segnale DRQ0 che collega il canale 0 del timer al canale 0 del DMA controller non va a finire sul bus, bensì è veicolato da un filo separato; al contrario il segnale DACK0 è uno dei segnali di controllo del bus, perché deve poter arrivare anche a schede di espansione di DRAM montate sulla scheda madre. Questo spiega perché nelle specifiche del bus XT compaiono 3 segnali DMA request e 4 DMA acknowledge.
Invece nel bus AT ci sono 4 segnali DMA request, ma si avverte che DRQ0 può essere utilizzato per implementare il rinfresco.
Ottenuto il controllo del bus, il DMA attiva il segnale DACK0 verso la DRAM, la quale può innescare un ciclo di refresh.
I PC attuali non utilizzano più il canale 0 del DMA controller, usano invece un DRAM controller apposito (8202 o 8203).
Le memorie sono soggette ad errori casuali dovuti ad una serie di fattori. Occorre distinguere tre tipi di errore:
errore non rilevato
errore rilevato e non corretto
errore rilevato e corretto
In generale, per poter rilevare ed eventualmente correggere gli errori, occorre aumentare la dimensione della memoria, inserendo dei bit di ridondanza, i quali contengono un'informazione sui bit di informazione. Immaginiamo che la memoria in esame sia organizzata in parole da K bit e che ciascuna parola possieda R bit di ridondanza:
![]()
N bit
![]()
Il valore di R dipende sia dalla tipologia di errori che vogliamo trattare (probabilità di errore singolo, doppio, ecc..), sia dal grado di parallelismo della memoria (e quindi da K).
Avendo N bit in totale, abbiamo 2N possibili combinazioni, ma di queste solo 2K sono corrette; le rimanenti 2R sono configurazioni errate: se si verificano, significa che c'è stato un errore.
Sia d la distanza di Hamming, cioè il numero di bit differenti tra due configurazioni corrette; chiamiamo e il numero di errori che si vogliono rilevare e c il numero di errori che si vogliono correggere. Valgono le seguenti relazioni:
![]()
![]()
Se per esempio vogliamo rilevare un errore singolo (e=1), la distanza di Hamming deve essere d 2; se vogliamo correggere errori singoli (c=1), abbiamo che deve essere d 3; se infine vogliamo correggere errori doppi (c=2), abbiamo che d
Il problema che vogliamo risolvere è quello di determinare il numero di bit di ridondanza necessari per la rilevazione e la correzione di una dato numero di errori. La relazione che ci permette di calcolare r è la seguente:
![]()
2r è il numero di possibili configurazioni degli r bit di ridondanza; queste configurazioni devono essere in numero sufficiente a fornirci l'informazione che desideriamo, relativa cioè agli errori riscontrati ed eventualmente al modo per correggerli.
Abbiamo bisogno sempre e comunque di una configurazione che indichi l'assenza di errori (questo spiega il primo 1 nel secondo membro della disequazione); inoltre abbiamo bisogno di una configurazione che ci indichi la presenza di un errore rilevato ma non corretto (questo spiega il simbolo 1r, che sta a indicare 1 se c'è un errore da rilevare ma non correggere, 0 altrimenti); infine ci occorrono nc configurazioni che ci permettano di individuare e correggere l'errore.
Per capire meglio, vediamo qualche esempio.
Rilevazione errore singolo (SED=single error detection)
![]()
![]()
In questo caso non vogliamo correggere errori, quindi nc=0; otteniamo che il numero minimo di bit necessari è 1; si tratta in effetti del controllo di parità implementato sulle memorie di molti PC.
Rilevazione e correzione errore singolo (SEC=single error correction)
![]()
![]()
In questo caso non ci sono errori solamente da rilevare, e quindi abbiamo 1r=0; invece, vogliamo rilevare e correggere gli errori singoli, quindi nc=k+r, perché dobbiamo individuare la posizione del bit errato (il bit errato può trovarsi anche negli r bit di ridondanza).
Rilevazione errore doppio e correzione errore singolo (SEC-DED)
![]()
![]()
In questo caso ci sono gli errori doppi solamente da rilevare, e quindi abbiamo 1r=1; inoltre, vogliamo rilevare e correggere gli errori singoli, quindi nc=k+r, perché dobbiamo individuare la posizione del bit errato.
Rilevazione errore triplo e correzione errore doppio
![]()
![]()
In questo caso ci sono gli errori tripli solamente da rilevare, e quindi
abbiamo 1r=1; inoltre, vogliamo rilevare e correggere gli errori
doppi, quindi ![]() , perché l'errore può essere singolo in una delle k+r posizioni, oppure
doppio, e quindi abbiamo k+r su 2 disposizioni possibili.
, perché l'errore può essere singolo in una delle k+r posizioni, oppure
doppio, e quindi abbiamo k+r su 2 disposizioni possibili.
Vediamo adesso alcuni esempi numerici.
|
K |
R |
|
e |
|
|
SEC |
SEC-DED |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Come si può notare, all'aumentare di k, l'efficienza del codice aumenta:
![]()
D'altra parte, all'aumentare dei bit che compongono una parola, aumenta la probabilità di riscontrare errori doppi e tripli, e quindi non è possibile allungare troppo le parole su cui si calcola la ridondanza. Generalmente la ridondanza è calcolata su 8 bit, anche se il parallelismo è maggiore.
![]()

Figura : schema per il controllo di parità
Il generatore di parità è sostanzialmente un albero di EXOR; nel circuito in fig. 27 ne compaiono due, ma in realtà si tratta sempre dello stesso circuito, il cui ingresso è multiplexato. In fase di scrittura del dato, viene calcolato il bit di parità e memorizzato nel 9° piano della memoria (abbiamo supposto di avere una memoria con parole di 8 bit); in fase di lettura, viene ricalcolato il bit di parità e confrontato con quello presente nel 9° piano; se coincidono, il dato è ritenuto corretto, altrimenti viene segnalato un errore.
Immaginiamo invece di avere un parallelismo di 16 bit, anziché 8. In questo caso lo schema di principio è differente: sono prelevati 16 bit dal DataBus, ma la parità viene calcolata sugli 8 bit alti e sugli 8 bassi separatamente (vedi fig.28).
Quale azione intraprendere quando viene rilevato un errore non correggibile? Sostanzialmente esistono 3 vie:
bloccare il sistema (adottato sui PC)
individuare il banco che ha segnalato l'errore, terminare i processi che girano su quel banco di memoria, escludere il banco tramite riconfigurazione della memoria
sostituire il banco guasto con un banco libero disponibile
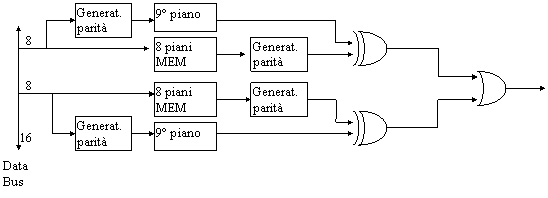
Figura : schema per in controllo di parità (parallelismo 16 bit)
I codici a blocco lineare trasformano parole di k bit di informazione in parole di k+r = n bit, mediante una applicazione lineare sui bit di informazione.
Chiamiano D il vettore di k elementi corrispondente alla parola di informazione, e T il vettore di n elementi corrispondente alla parola codificata.
![]()
Il vettore D subisce una trasformazione lineare che lo trasforma nel vettore T, cioè la parola di informazione di k bit subisce una codifica che la trasforma in una parola di codice di n bit comprendente r bit di ridondanza.
La trasformazione lineare avviene tramite una matrice G di k righe e n colonne, detta matrice generatrice:

![]()
|
|
|
|
|
k colonne n colonne
Nella parola T risultante, in generale, i bit di informazione sono mischiati ai bit di ridondanza. Per semplificare l'operazione di decodifica, conviene che i bit di informazione siano ben separati da quelli di ridondanza; in altre parole si vuole che il vettore T abbia una forma di questo tipo:
![]()
dove di sono i bit di informazione (coincidenti con quelli presenti in D), mentre pj sono i bit di parità. Un codice con questa caratteristica si chiama separabile o sistematico.
Per ottenere un vettore T con la forma descritta, occorre che la matrice G sia strutturata nel seguente modo.

G = k righe
![]()
La matrice G è composta da due sottomatrici:
la matrice identità I, di k righe e k colonne
la matrice di parità P, di k righe e r colonne
Moltiplicando il vettore D per la matrice G così strutturata, si ottiene il vettore T in cui compaiono per primi i k bit di informazione, seguiti dagli r bit di parità.
Come si determina la matrice P di parità?
Immaginiamo di voler rilevare e correggere gli errori singoli, su una parola di informazione di k=4 bit. Abbiamo già visto che per ottenere il numero r di bit di ridondanza occorre rifarsi alla seguente relazione:
![]()
Nel nostro caso 1r=0 e nc=k+r, cioè nc=4+r:
![]()
Quindi avremo la seguente situazione:
D G
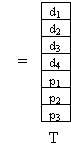

![]()
![]()
dove:

Ricorda: sommare bit singoli equivale a eseguire l'EXOR tra essi:
|
|
|
|
|
Importante: la matrice P deve avere rango pari a r; in altre parole, le r colonne che la formano devono essere linearmente indipendenti. Continuiamo l'esempio, inserendo dei numeri binari dentro la matrice P:
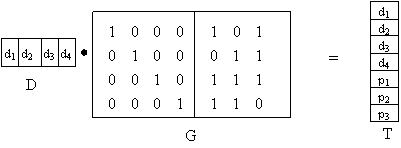
dove:
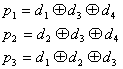
Con il metodo appena visto possiamo calcolare la codifica di una parola D di k bit in una parola T di n bit, in cui compaiono separati gli r bit di ridondanza. Ora vediamo come avviene il processo inverso, cioè la decodifica. Si tratta si applicare una trasformazione lineare al vettore T tramite una matrice H strutturata in questo modo:

P k righe
![]()
H = r righe

r colonne
La matrice H è composta da due sottomatrici:
la matrice identità I, di r righe e r colonne
la matrice P (la stessa di prima), di k righe e r colonne
Moltiplicando il vettore T per la matrice H così strutturata, si ottiene il vettore S detto Sindrome, composto da r elementi:
![]()
Con T* si è indicato il vettore di bit che dobbiamo decodificare, il quale può essere diverso dal vettore T calcolato con la codifica: infatti la parola contenuta in T può avere subito modifiche a causa di errori. Abbiamo allora due casi: se il vettore si è conservato immutato, cioè T=T*, il vettore S risulterà composto da elementi tutti nulli (è facile dimostrarlo matematicamente); se al contrario qualche bit si è modificato, allora il vettore S sarà diverso da zero.
ATTENZIONE: la sindrome potrebbe valere 0 anche quando si verificano errori tali che il nostro codice non è in grado di rilevarli! Se per esempio il nostro codice è in grado di rilevare gli errori doppi, un errore triplo passerà inosservato, e la sindorme sarà pari a zero.
Nel caso in cui la sindrome non sia pari a zero, possiamo ricavarne delle informazioni che ci aiutino a correggere l'errore. Abbiamo detto che T è il vettore corretto, mentre T* è il vettore errato. Allora possiamo scrivere la seguente relazione:
![]()
dove E è un vettore che ha degli "1" in certe posizioni, tali da soddisfare la relazione scritta. Per esempio, se abbiamo un errore singolo:
T= 101011
T*= 101111
quindi
E= 000100
Se abbiamo un errore doppio:
T= 101011
T*= 101101
quindi
E= 000110
Calcolando la sindrome otteniamo quindi:
![]()
dove 0r indica il vettore nullo di r elementi.
Nel caso di errore singolo, il vettore E contiene un solo bit a 1, corrispondente alla posizione dell'errore, e quindi S coincide con la riga di H corrispondente alla posizione dell'errore.
Da questo si deduce che, nel caso S non sia nullo, possiamo confrontare il contenuto di S con tutte le righe di H: la posizione della riga di H coincidente con S è la posizione del bit errato all'interno di T*.
Con questo metodo siamo quindi in grado di rilevare e correggere gli errori singoli.
Per assicurare la corretta identificazione del singolo bit errato, è necessario che:
le righe di H siano tutte diverse tra loro
nessuna riga di H sia nulla (ci sarebbe contraddizione con il fatto che sindrome nulla equivale ad assenza di errore)
Se vogliamo rilevare anche gli errori doppi, dobbiamo pensare al fatto che il vettore E contiene in questo caso due bit a 1, quindi la sindrome è pari alla somma (EXOR) di due righe di H. Questo significa che oltre alle due condizioni scritte sopra, se ne aggiunge una terza:
la somma (EXOR) di due righe di H non può essere nulla né deve coincidere con una terza riga della matrice
Sotto tali condizioni otteniamo un codice SEC-DED, e possiamo seguire il seguente algoritmo:
controllare se S è pari a zero. Se è così, si assume assenza di errore
se S non è pari a zero, si cerca una riga di H uguale a S
se S è uguale all'i-esima riga di H, l'i-esimo bit della parola è errato e possiamo correggerlo complementandolo
se S non è uguale ad alcuna riga di H, siamo in presenza di errore doppio (o superiore) non correggibile
Questo algoritmo, applicato a un codice SEC-DED, corregge qualsiasi errore singolo e rivela tutti gli errori doppi. Errori su un numero maggiore di bit possono essere rilevati o corretti in modo improprio.
Esistono diversi procedimenti per generare un codice SEC-DED. Uno di questi consiste nel ricavare un codice SEC-DED a partire dalla matrice H di un codice SEC.
Immaginiamo di aver costruito una matrice H in grado di correggere e rilevare errori singoli (SEC); se vogliamo trasformarla in una matrice SEC-DED, dobbiamo fare in modo che rispetti il terzo dei tre punti specificati nel paragrafo 4.4; in altre parole, una combinazione qualunque di due righe di H non deve essere uguale a nessuna delle righe di H.
Un metodo per ottenere questa proprietà consiste nell'aggiungere una riga composta di '0' tranne l'ultimo elemento, e una colonna composta interamente di '1'.
Con questa modifica non si violano le tre regole enumerate precedentemente:
le righe di H sono tutte diverse tra loro (nessuna riga poteva essere fatta di zeri nella matrice H originaria)
nessuna riga di H è nulla
la somma (EXOR) di due righe di H non è nulla né coincide con una terza riga della matrice, grazie al fatto che ogni riga termina con un 1
In fase di scrittura, i k bit di dato entrano in una rete di EXOR modellata sulla matrice P, e gli r bit di ridondanza calcolati vengono memorizzati nei piani di memoria appositi.
In fase di lettura (vedi fig.29), tramite i k bit di dato, sono ricalcolati gli r* bit di ridondanza e confrontati con gli r memorizzati nella fase di scrittura.

Figura : schema di rilevazione e correzione
Se le due sequenze di bit sono identiche, quindi se la sindrome S è composta di bit tutti nulli, significa che non si è riscontrato nessun errore. Se invece la sindrome è diversa da zero, questa viene inviata ad un comparatore in cui entrano anche le righe di H; il comparatore confronta ogni riga di H con la sindrome, e produce n bit con questa caratteristica: il bit i-esimo vale 1 se la riga i-esima di H è uguale alla sindrome, 0 viceversa. Se tutti gli n bit sono tutti nulli, significa che siamo in presenza di un errore doppio non correggibile; se invece il bit i-esimo è pari a 1, allora il bit i-esimo della parola memorizzata (su n bit) è sbagliato e bisogna complementarlo. La correzione viene fatta tramite un EXOR che inverte solo il bit errato.
L'esempio appena visto corregge i bit di dato e di ridondanza, ma possiamo pensare anche ad un circuito che corregge on the fly solo i bit di dato e pone il risultato direttamente sul bus; in questo caso nell'ultimo EXOR entrano solo k bit di dato invece di n.
Il primo approccio è circuitalmente più complesso e richiede tempi più lunghi; infatti la parola corretta non viene scritta direttamente sul bus, ma deve essere riscritta in memoria, quindi occorre un bus interno che riporti il risultato ai banchi di memoria. Per fare questo occorre utilizzare un ciclo di tipo READ-MODIFY-WRITE, oppure due cicli separati, uno di lettura e uno di scrittura.
Il secondo approccio è naturalmente più semplice, ma ha un grosso limite: non corregge il dato in memoria. Questo significa che un errore permane in memoria finché la parola che lo contiene non viene riscritta, con il rischio che col passare del tempo, da singolo diventi doppio.
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2024