|
|
| |
Università Degli Studi di Salerno
Facoltà di Scienze MM.FF.NN.
Corso di Laurea in Informatica

Intelligenza Artificiale:
Metodi e Tecniche
Metodi di Ricerca
I.A.M.T. METODI DI RICERCA
CAPITOLO 1
L'Intelligenza Artificiale costruisce sistemi intelligenti mirati anche alla risoluzione di un problema definito come obiettivo da raggiungere che non si sa come conseguire. Un agente risolutore di problemi può decidere cosa fare considerando il risultato di varie sequenze di azioni che potrebbe compiere per giungere a stati desiderati.
Ovviamente il compito di un agente si semplifica quando conosce l'obiettivo da raggiungere, mirando al suo soddisfacimento e alla massimizzazione delle prestazioni. Quindi il primo passo per la risoluzione del problema è formulare l'obiettivo, potendo considerare anche quelle decisioni che influiscono sul raggiungimento dell'obiettivo; da ciò si può considerare l'obiettivo come un insieme di stati. Mentre le azioni da compiere per il raggiungimento dell'obiettivo sono viste come transizioni tra stati del mondo reale. Quindi un problema è formalizzato identificando stati e azioni per il raggiungimento dell'obiettivo.
Un agente può esaminare prima tutte le possibili sequenze di azioni che portano a stati di esito positivo e tra queste selezionare la migliore.Questo processo è denotato come ricerca. Un algoritmo di ricerca prende in input un problema e restituisce in output la soluzione sotto forma di azioni da intraprendere. Una volta trovata la soluzione le azioni possono essere realizzate. Questa fase e denotata come esecuzione.
Esempio: Supponiamo che un agente alla fine di un viaggio turistico si trovi nella città di Arad (Romania), esso ha un biglietto aereo per partire da Bucarest per il giorno seguente che non può essere rimborsato e non ci sono posti liberi sulla linea Arad-Bucarest per sei settimane, in più sta per scadere il permesso di soggiorno in Romania quindi deve necessariamente lasciare il paese altrimenti sarà arrestato ed espulso. Siccome l'agente vuole imparare il rumeno non può essere espulso e vista la gravità della situazione deve adottare l'obiettivo di guidare fino a Bucarest (formulazione obiettivo).
Assumiamo che l'agente guidi (azione) da una grande città all'altra, ognuna delle quali è denotata come uno stato.
L'agente deve risolvere il primo problema di quale strada seguire visto che tra le due città ci sono tre strade (ricerca), ma nessuna di queste arriva direttamente all'obiettivo, quindi avrà bisogno di un aiuto oppure iniziare a caso la sua ricerca. Supponiamo che abbia una cartina che fornisca informazioni sugli stati e le azioni che deve intraprendere. Utilizzando queste informazioni può iniziare il viaggio che lo porterà a Bucarest (soluzione).
Il processo di formalizzazione di un problema può essere diviso in quattro tipi di categorie molto diverse:
Problemi a singolo stato
Problemi a stati multipli
Problemi di contingenza
Problemi di esplorazione
Per notare le differenze ci avvaliamo di un esempio:
Supponiamo di trovarci nel mondo degli aspirapolvere e che tale mondo contenga solo due posizioni (sporco o meno) e l'agente si trovi in una delle due posizioni (FIG.1)
Figura 1 - Gli otto stati del problema degli
aspirapolvere
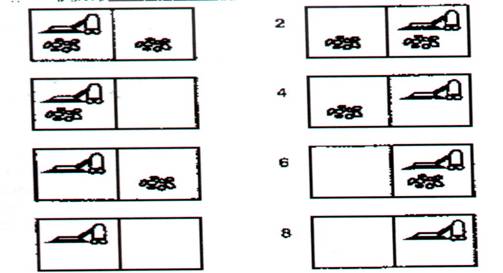
Ci sono otto possibili stati di questo mondo in cui l'agente può eseguire tre azioni:
Sinistra [sx]
Destra [dx]
Aspira (efficace al 100%) [asp]
L'obiettivo è di raccogliere tutta la sporcizia (stati )
Consideriamo i seguenti casi:
i sensori dell'agente gli forniscono informazioni inerenti a quale stato si trova (mondo accessibile) e che conosca il risultato di ogni singola azione.Da questo l'agente sa calcolare ogni singola sequenza di azioni. Per esempio se lo stato è 5 allora le azioni saranno [dx,asp] che porta all'obiettivo. Questo è il caso più semplice e cioè problema a stato singolo.
supponiamo che l'agente conosca l'effetto delle sue azioni ma non sappia in quale stato si trovi. Ad esempio può non avere sensori e quindi lo stato iniziale sarà che potrebbe sembrare senza soluzione; ma siccome l'agente conosce l'effetto delle sue azioni sa che effettuando un azione destra si troverà negli stati , ed inoltre potrà scoprire che effettuando la sequenza [dx,asp,sx,asp]garantirà il raggiungimento dell'obiettivo. Questo è il caso dei problemi a stati multipli.
supponiamo che l'agente sia nel mondo della legge di Murphy: "L'azione aspira deposita alcune volte sporcizia sul tappeto ma solo se è pulito" e che abbia un sensore per la posizione e uno locale per la sporcizia, ma non abbia nessun sensore per rilevare la sporcizia negli altri quadrati. Se ci troviamo in uno degli stati iniziali si potrebbe formulare la sequenza di azioni [asp,dx,asp], dove aspirando andremo in uno degli stati e andando a destra andremo in in cui nello stato 6 ci sarà un successo mentre nello stato 8 un fallimento! Quindi il problema non può essere risolto iniziando da uno degli stati in quanto la terza azione (aspira) dovrebbe essere compiuta solo se c'è sporcizia nel punto in cui ci siamo spostati. Tale problema può essere risolto effettuando un rilevamento durante la fase di esecuzione, in cui l'agente deve calcolare un intero albero di azioni invece che una singola sequenza. Un ramo dell'albero viene chiamato problema di contingenza. (gli altri due casi possono essere raggruppati in questi)
supponiamo che l'agente non abbia un piano garantito e che decidi di agire prima di considerare qualsiasi situazione contingente che potrebbe trovarsi nell'esecuzione, affrontando i problemi contingenti quando si presentano. Siamo nel caso di interlacciamento di ricerca ed esecuzione. Questa situazione si presenta quando l'agente non ha nessun tipo di informazione sull' effetto delle azioni allora deve improvvisare e le esperienze raccolte gli permetteranno di risolvere i problemi successivi (problema di esplorazione).
Un problema è una collezione di informazioni che l'agente userà per decidere cosa fare. Esso è formalizzato identificando stati e azioni, ma in generale avremo bisogno di:
uno stato iniziale in cui l'agente sa di trovarsi.
Un insieme di azioni possibili che sono disponibili all'agente. Con il termine operatore si vuole specificare che qualche stato sarà raggiungibile applicando una particolare azione ad un altro stato specifico. Alternativamente, data una funzione successore S ed un particolare stato x, S(x) restituisce l'insieme degli stati raggiungibili da x applicando una particolare azione.
Con questi due elementi possiamo definire lo spazio degli stati come l'insieme di tutti gli stati raggiungibili dallo stato iniziale. Un cammino nello spazio degli stati è semplicemente una sequenza di azioni che va da uno stato ad un altro. Successivamente dovremo verificare se uno stato raggiunto in un cammino soddisfa l'obiettivo. Quindi avremo bisogno di:
Un test obiettivo che l'agente può applicare alla descrizione del singolo stato per vedere se è finale. Talvolta c'è un insieme esplicito di stati finali quindi il test verifica solo se abbiamo raggiunto o meno uno di essi. Oppure l'obiettivo può essere rappresentato da una proprietà astratta descritta attraverso un insieme di stati esplicitamente elencati.
Una funzione costo dei cammini g che assegna un costo ad ogni cammino. In tutti i casi il costo di un cammino è la somma dei costi delle azioni individuali lungo un cammino.
Quindi, lo stato iniziale, l'insieme degli operatori, il test e la funzione costo definiscono un problema.
L'output di un algoritmo di ricerca è la soluzione, cioè il cammino che dallo stato iniziale porta in uno stato che soddisfa il test. In realtà si è considerato problemi a singoli stati anche se non ci sono modifiche sostanziali per problemi a stati multipli. In questo caso, un problema consiste in:
Un insieme di stati iniziali.
Un insieme di operatori che specificano l'insieme di stati raggiunti applicando un azione a qualsiasi stato considerato.
Un test obiettivo.
Una funzione costo camino.
Un cammino in questo caso collega un insieme di stati, ed una soluzione conduce ad un insieme di stati che sono tutti stati obiettivo. Lo spazio è costituito dallo spazio dell'insieme degli stati.
L'efficacia di un algoritmo di ricerca può essere misurata in tre modi:
Si riesce a trovare una soluzione?
Si tratta di una buona soluzione? (Inteso come basso costo di cammino)
Qual'è il costo di ricerca associato al tempo e alla memoria per trovare la soluzione?
Il costo totale di ricerca è dato dalla somma del punto 2 e 3. Per esempio per trovare la strada da Arad a Bucarest il costo di cammino potrebbe essere le miglia percorse mentre il costo di ricerca è relativo alla circostanza. In un ambiente statico è zero in quanto la ricerca non dipende dal tempo; nell'esempio si tratta di un ambiente semidinamico e il costo di ricerca varia con il costo di calcolo. Per calcolare il costo totale non si devono sommare secondi a miglia dato che sono incompatibili e non esiste nessun rapporto di cambio. In genere per problemi piccoli basta trovare una soluzione con costo di cammino più basso. Per problemi più complessi si cerca un compromesso dato che l'agente potrebbe trovare una soluzione ottima in tempi lunghi.
Diamo un esempio di indagine su un problema riaffrontando il problema dell'agente "in guida da Arad a Bucarest". (FIG2)
Uno spazio degli stati ha 20 stati ognuno dei quali rappresenta uno stato che specifica una città. Lo stato iniziale è Arad mentre il test è Bucarest e gli operatori corrispondono alla guida dell'agente tra le strade delle città.
Figura
2 - Il problema dell'agente
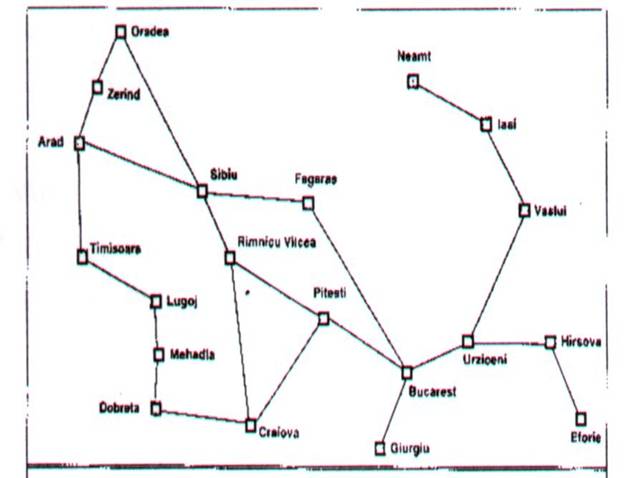
Una soluzione va da Arad a Sybiu a Rimnicu Vilcea a Potesti a Bucarest, ma ci sono altri percorsi attraverso Cracovia etc. Per calcolare qual è la soluzione migliore si deve sapere come è definita la funzione costo cammino: potrebbe essere il tempo di viaggio oppure le miglia percorse. Supponiamo di prendere in considerazione il numero di tappe. Si nota che il percorso attraverso Sibiu e Fagaras ha il numero minimo di tappe (3) e quindi è la soluzione migliore possibile.
Una cosa importante da considerare è cosa inserire nella descrizione degli stati e cosa trascurare . Nell'esempio non abbiamo considerato se l'agente accende la radio e poi la spegne. Il processo di eliminare dettagli si chiama astrazione. Possono essere astratte sia descrizione degli stati che delle azioni. Nell'esempio della gita ci sono vari effetti come il cambiamento di posto del veicolo e dei suoi occupanti mentre abbiamo considerato solo il cambiamento di posto. L'astrazione ci permette di semplificare il problema originale conservandone la validità e osservando che le funzioni astratte siano facili da realizzare.
 Il
rompicapo dell'otto consiste in una tabella tre per tre con otto tessere
numerate ed uno spazio vuoto. Lo stato iniziale è mostrato nella Fig.3 mentre
l'obiettivo è raggiungere la configurazione che si trova nella sua parte
destra.
Il
rompicapo dell'otto consiste in una tabella tre per tre con otto tessere
numerate ed uno spazio vuoto. Lo stato iniziale è mostrato nella Fig.3 mentre
l'obiettivo è raggiungere la configurazione che si trova nella sua parte
destra.
Figura 3 - Il rompicapo dell'otto
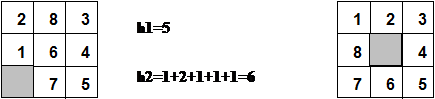
Tale problema porta la seguente formulazione:
Stati: una descrizione dello stato specifica la posizione di ognuna delle otto tessere in uno dei quadrati.
Operatori: lo spazio vuoto si sposta a destra or sinistra or sopra or sotto
Test obiettivo: lo stato rispecchia la configurazione obiettivo mostrata in figura.
Costo di cammino: ciascun passo costa uno, quindi il costo totale è pari alla lunghezza del cammino.
Tale problema appartiene alla famiglia dei rompicapi del blocco che scivola, che appartiene alla classe NP- completa.
Consiste nel posizionare otto regine su una scacchiera senza che una possa attaccare le altre. Esistono due tipi di formulazione:
La formulazione incrementale: le regine vengono posizionate una per volta.
La formulazione a stato completo: tutte le regine si trovano sulla scacchiera e vengono spostate.
Figura 4 - Il problema delle otto regine

In entrambi i casi il costo di cammino non ha nessun valore in quanto conta solo lo stato finale e gli algoritmi vengono confrontati sul costo di ricerca.
Avremo due formulazioni:
Formulazione incrementale:
Test obiettivo: otto regine sulla scacchiera (nessuna minaccia).
Costo cammino
Stati: qualsiasi configurazione da zero a otto regine sulla tastiera
Operatori: aggiungi una regina in qualsiasi quadrato
In questa formulazione si devono calcolare 648 sequenze possibili.
Una scelta migliore si basa sul fatto che collocare una regina in una posizione già minacciata non funzionerà nemmeno per scelte future.
Formulazione a stato completo:
Test obiettivo: otto regine sulla tastiera (nessuna minaccia)
Costo cammino
Stati: qualsiasi configurazione da zero a otto regine sulla scacchiera in cui nessuna viene attaccata.
Operatori: posiziona la regina nella colonna vuota più a sinistra in modo che non venga attaccata da nessun altra.
Le lettere rappresentano cifre e lo scopo è di trovare una sostituzione di lettere con cifre in modo tale che la somma risultante sia aritmeticamente corretta. La più semplice formulazione è la seguente:
Test obiettivo: il rompicapo contiene solo cifre e rappresenta una somma corretta
Costo di cammini: 0, tutte le soluzioni sono ugualmente valide.
Stati: un rompicapo di crittoaritmetica dove alcune lettere sono sostituite da numeri.
Operatori: sostituisce tutte le occorrenze di una lettera con una cifra che non compare già nel rompicapo.
F=2, O=9, R= 7 etc.
FORTY Solution: 29786+
+TEN 850+
![]() +TEN 850=
+TEN 850=
=SIXTY 31486
1.2.4 Il mondo dell'aspirapolvere
Assumiamo il caso di un sistema a stati singolo con informazioni complete, quindi che l'agente conosca la propria posizione, la posizione di tutte le parti di sporcizia e che l'aspirapolvere funziona ancora bene.
Una prima formulazione potrebbe essere:
Test obiettivo: non lasciare nessuna sporcizia nei quadrati.
Costo di cammino: ciascuna azione costa "uno".
Stati: uno degli otto stati della figura.
Operatori: spostati a sinistra, a destra, aspira.
Supponiamo adesso che l'agente non ha informazioni sulla sua posizione e quella della sporcizia. In tal caso il problema diventa a stati multipli:
Test obiettivo: tutti gli stati nell'insieme degli stati che non contengono sporcizia.
Costo di cammino: ciascuna azione costa "uno".
Insiemi di stati: sottoinsieme degli 1-8 stati in figura 5.
Operatori: spostati a sinistra, a destra, aspira.
Figura
5 - Il mondo dell'aspirapolvere
1.2.6 Missionari e cannibali
Supponiamo di avere tre missionari e tre cannibali sulle sponde di un fiume insieme ad una barca che può trasportare una o due persone. Lo scopo è di condurre tutti sull'altra sponda senza mai lasciare in un posto un numero di missionari minore del numero di cannibali. Escludiamo tutti i dettagli che non hanno peso nella soluzione tipo i coccodrilli.
Qualsiasi permutazione dei tre missionari o dei tre cannibali portano sempre alla stessa soluzione. Diamo la seguente definizione formale del problema:
Stati: uno stato consiste in una sequenza ordinata di tre numeri che rappresenta rispettivamente il numero di missionari, il numero di cannibali e il numero di barche. Per cui lo stato iniziale sarà 3,3,1.
Operatori: da ciascun stato gli operatori possibili devono portare in barca un missionario or un cannibale or due missionari or due cannibali or uno per ogni gruppo. Quindi avremo al più cinque operatori.
Test obiettivo: lo stato (0,0,0).
Costo cammino: numero di traversate.
1.3 Problemi del mondo reale
1.3.1 Ricerca di itinerario
Questi algoritmi di ricerca sono usati in varie applicazioni, come:
L'instradamento nelle reti di calcolatori
Nei sistemi automatici che consigliano viaggi
Nei sistemi di pianificazione di viaggi aerei
1.3.2 Problemi di viaggio e commesso viaggiatore
Sono simili al problema di ricerca dell'itinerario, infatti gli operatori corrispondono ancora a viaggi tra città adiacenti quindi lo spazio degli stati deve registrare più informazioni. Il problema del commesso viaggiatore è un problema NP-completo in cui ciascuna città deve essere visitata solo una volta, richiedendo di trovare l'itinerario più breve tra due città date.
1.3.3 Configurazione VLSI
Una piastrina VLSI può avere milioni di porte il cui posizionamento con le relative connessioni sono decisive per il funzionamento. Due dei compiti fondamentali sono la configurazione delle celle e l'instradamento dei canali che vengono fissati dopo che le componenti e le connessioni del circuito sono state fissate. L'obiettivo è di configurare il circuito in modo da minimizzare l'area e la lunghezza di connessione massimizzando così la velocità.
1.3.4 Navigazione dei robot
È una generalizzazione del problema dell'itinerario nel quale invece di avere un insieme discreto di itinerari si possono avere un insieme infinito di stati. Un robot semplice si muove su una superficie piatta per cui lo spazio è bidimensionale, mentre se il robot ha anche le braccia e le gambe lo spazio è a più dimensioni. In realtà il problema è abbastanza complesso dato che i robot reali devono occuparsi degli errori di lettura dei loro sensori e del controllo dei motori.
1.4 Cercare soluzioni
Le soluzioni vengono cercate attraverso una ricerca nello spazio degli eventi. L'idea è di mantenere ed estendere un insieme di sequenze di soluzioni parziali.
Per risolvere il problema di ricerca dell'itinerario si inizia dallo stato iniziale verificando se è uno stato obiettivo, dato che non lo sarà si considerano gli altri stati. Per fare ciò si procede secondo il processo di espansione, cioè si applicano gli operatori allo stato corrente, determinando la generazione di un nuovo insieme di stati. Si procede fino a quando non si trova qualche soluzione oppure non ci sono più stati da espandere. La scelta di quale stato espandere per primo dipende dalla strategia di ricerca adottata. Si può pensare al processo di ricerca come la costruzione di un albero di ricerca sovrapposto alo spazio degli stati in cui la radice è un nodo di ricerca che corrisponde allo stato iniziale e i nodi foglia a stati che non hanno successori nell'albero. Ad ogni passo l'algoritmo sceglie un nodo foglia da espandere. La struttura dati associata a ciascun nodo è la seguente:
Lo stato nello spazio degli stati a cui il nodo corrisponde;
Il nodo padre ( il nodo nell'albero che lo ha generato);
L'operatore che è stato applicato per generare il nodo;
Profondità del nodo (# di nodi nel cammino dalla radice al nodo);
Il costo di cammino dallo stato iniziale al nodo;
Da ricordare che un nodo è una struttura dati usata per rappresentare l'albero di ricerca di una particolare istanza del problema mente uno stato è una rappresentazione del mondo reale. Per questo i nodi appartengono ad un cammino particolare definito dai puntatori Nodo-Padre. Si devono tenere presente anche i nodi che attendono di essere espansi (confine o frontiera). Un ottima strategia di rappresentazione di questa collezione di nodi è realizzata tramite coda sulla quale sono permesse le seguenti operazioni:
Costruisci_coda(elemento): crea una coda con l'elemento dato;
Vuota(coda): restituisce vero se la coda risulta priva di elementi;
Rimuovi_testa(coda): rimuove l'elemento di testa della coda e lo restituisce;
Fn_in_coda(elementi, coda): inserisce un insieme di elementi nella coda.
CAPITOLO 2
STRATEGIE DI RICERCA
Nell'ambito della ricerca la cosa più importante è stata di trovare la giusta strategia di ricerca per un problema. Valuteremo le strategie in termini di quattro criteri:
Completezza: garantisce di trovare una soluzione quando ne esiste una.
Complessità temporale: quanto tempo ci vuole per trovare una soluzione?
Complessità spaziale: quanta memoria occorre per effettuare la ricerca?
Ottimalità: la strategia trova la soluzione di qualità massima quando ci sono varie soluzioni differenti.
Ora vediamo sei strategie di ricerca che sono catalogate con il nome di ricerca non informata; cioè che non si ha alcuna informazione sul numero di passi o sul costo di cammino dallo stato attuale all'obiettivo.
In questa strategia, si espande prima il nodo radice, successivamente tutti i nodi generati dal nodo radice, poi i loro successori e cosi via. In generale tutti i nodi di profondità d nell'albero di ricerca, si espandono prima dei nodi di profondità d+1.
Figura 6 - Ricerca in ampiezza

Per vedere perché non è sempre la strategia da scegliere, dobbiamo considerare la quantità di memoria e di tempo che occorre per completare una ricerca. Cosi consideriamo uno spazio degli stati ipotetico in cui ogni stato possa essere espanso producendo b nuovi stati. Diciamo che il fattore di ramificazione di questi stati è b. La radice dell'albero di ricerca genera b nodi al primo livello, ciascuno dei quali genera altri b nodi, per un totale di b2 nodi al secondo livello. Ciascuno di questi genera altri b nodi, producendo b3 nodi al terzo livello e cosi via.
Supponiamo ora che la soluzione sia individuata da un cammino di lunghezza d. Nel caso peggiore, espanderemo tutti i nodi tranne l'ultimo al livello d. Il numero massimo nodi espansi è:
1+b+b2 +b3 +.+bd-1 =O(bd)
La soluzione però potrebbe essere trovata a qualsiasi punto del livello d. Nel caso migliore il numero sarà inferiore.
Questa ricerca modifica la strategia in ampiezza espandendo sempre il nodo foglia con costo minore (misurato attraverso il costo del cammino g(n)).
Figura 7 - Il problema della ricerca
dell'itinerario
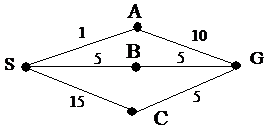
Il problema è di arrivare da S a G ed è stato indicato il costo di ciascun operatore. La strategia espande prima lo stato iniziale, producendo cammini verso A, B e C. Poiché il cammino fino ad A è il più economico, questo viene successivamente espanso, generando il cammino SAG, che è in effetti una soluzione, perché ha costo 11 e perciò è relegato nella coda dopo il cammino SB, che ha costo 5. Poi si espande SB, generando SBG, che adesso è il cammino più conveniente rimasto nella coda, perciò viene verificato rispetto all'obiettivo e restituito come soluzione. La complessità temporale e spaziale è la stessa della ricerca in ampiezza.
La ricerca in profondità espande sempre uno dei nodi a livello più profondo dell'albero. Poi torna indietro ed espande nodi ai livelli più superficiali solo quando trova un vicolo cieco (un nodo non obiettivo, senza alcuna espansione).
Figura 8 - Ricerca in profondità
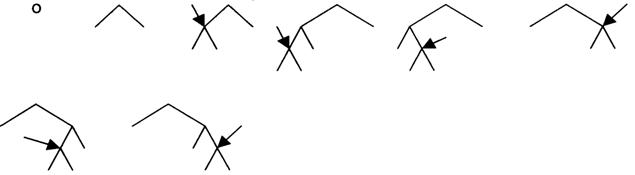
L'occupazione di memoria in questa ricerca è molto modesta. Come mostra la figura precedente (figura 8) si deve memorizzare solo un cammino dalla radice al nodo foglia, insieme ai nodi fratelli di ciascun nodo del cammino che rimangono non espansi.
Per uno spazio degli stati con fattore di ramificazione b e profondità massima m, la ricerca richiede la memorizzazione di solo b*m nodi, a differenza di bd nodi che richiede la ricerca in ampiezza nel caso di profondità d.
La complessità temporale è O(bm). La ricerca in profondità è preferita alla ricerca in ampiezza, in casi in cui un problema ha più soluzioni. Questo perché la prima trova una soluzione dopo aver esplorato solo una piccola porzione dell'intero spazio, mentre la seconda dovrebbe guardare tutti i cammini di lunghezza d-1 prima di considerare uno di lunghezza d.
Nel caso peggiore la ricerca in profondità è O(bm). L'inconveniente è che può rimanere bloccata nel seguire un cammino sbagliato.
La ricerca a profondità limitata evita i tranelli della ricerca in profondità imponendo un taglio alla profondità massima di un cammino. L'algoritmo riceve questo limite di profondità come parametro e opera esattamente come la ricerca in profondità, tranne che per i nodi al limite di profondità, i quali non vengono espansi. Se nono viene trovata alcuna soluzione, l'algoritmo restituisce uno speciale valore, taglio, nel caso in cui alcuni nodi non fossero espansi a causa del limite di profondità; altrimenti restituisce fallimento. La complessità spaziale e temporale è simile alla ricerca in profondità. Impiega O(bl) tempo e uno spazio (b*l), dove l è il limite di profondità.
2.5 Ricerca al approfondimento iterativo
La parte difficile della ricerca a profondità limitata è scegliere un buon limite. La ricerca ad approfondimento iterativo evita la questione di scegliere il miglior limite di profondità, provando tutti i possibili limiti di profondità: prima la profondità 0, poi la1, la 2 e cosi via. Questo algoritmo è ottimale e completo come la ricerca in ampiezza, ma ha la stessa occupazione di memoria modesta della ricerca in profondità.
La complessità temporale è O(bd) e quella spaziale è O(b*d). Questo metodo è preferito quando c'è un grande spazio di ricerca e non si conosce la profondità della soluzione.
L'idea di questa ricerca è di cercare simultaneamente sia in avanti, dallo stato iniziale, che all'indietro, dall'obiettivo, fermandosi quando le due ricerche si incontrano nel centro(fig. 9) .
Figura 9 - Ricerca bidirezionale
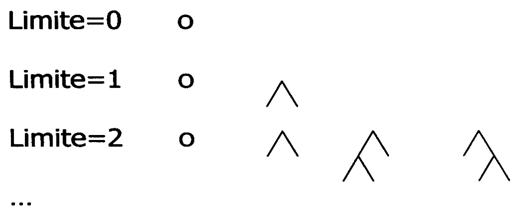
Per i problemi in cui il fattore di ramificazione è b in entrambe le direzioni, la ricerca bidirezionale può comportare vantaggi significativi.
Assumiamo che c'è una soluzione di profondità d. La soluzione verrà trovata in O(2*bd/2) = O(bd/2) passi, perché ciascuna delle ricerche in avanti e indietro deve fare solo metà cammino.
2.7 Evitare ripetizioni di stati
Una delle più importanti complicazioni del processo di ricerca è la possibilità di perdere tempo ad espandere stati che sono già stati espansi prima in qualche altro cammino. Ci sono problemi in cui ogni stato può essere raggiunto in un solo modo e tale possibilità non si presenta mai; per altri le ripetizioni di stati sono inevitabili.
Evitando la ripetizione degli stati si può ridurre l'albero di ricerca ad una misura finita, generando solo la porzione di albero che ricopre il grafo dello spazio degli stati. Esistono tre metodi per occuparsi degli stati ripetuti, in ordine crescente di efficacia e di costo computazionale aggiuntivo:
Non ritornare sullo stato da cui si proviene,
Non creare cammini che abbiano cicli,
Non generare alcuno stato già generato prima(cioè ogni stato generato deve essere tenuto in memoria).
CAPITOLO 3
METODI DI RICERCA CON FUNZIONI EURISTICHE
3.1 Introduzione
La parola "euristica" deriva dal verbo greco heuriskein, che significa "trovare"o "scoprire". Il significato tecnico di "euristica" ha subito diversi mutamenti nella storia dell'Intelligenza Artificiale. Alcune persone utilizzarono il termine "euristico" per riferirsi allo studio di metodi per scoprire ed inventare tecniche di risoluzione di problemi( in particolare di determinare dimostrazioni matematiche) mentre altri usano il termine euristica come l'opposto di algoritmo in quanto non c'è alcuna garanzia riguardo a quanto tempo impiegherà la ricerca e, in alcuni casi, non è neppure garantita la qualità della soluzione .
Le tecniche euristiche hanno dominato le prime applicazioni dell'Intelligenza Artificiale. Il primo laboratorio di "sistemi esperti" all' Università di Stanford, venne chiamato Heuristic Programming Project (HPP) dove le euristiche erano viste come "regole empiriche" che gli esperti del dominio potevano usare per generare buone soluzioni senza ricercare esaustivamente, dando così vita ai primi sistemi basati su regole.
Il rompicapo dell'8 fu uno dei primi problemi di ricerca euristica. Come si osserva in figura, lo scopo del gioco è spostare le tessere orizzontalmente o verticalmente nello spazio vuoto fino a che la configurazione rispecchi la configurazione obiettivo. Una soluzione tipica è di circa 20 passi, anche se ciò dipende dallo stato iniziale. Il fattore di ramificazione è circa 3 = 3.5 x 10
(quando la tessera vuota è nel centro, ci sono quattro mosse possibili; quando è in un angolo ce ne sono due; quando è vicino al bordo ce ne sono tre). Un'ipotetica soluzione di ricerca esaustiva di profondità 20 considererebbe circa 3 possibili stati mentre tenendo conto delle ripetizioni di stati potremmo considerare solo 9!(=362880) possibili collocazioni differenti di 9 quadrati.
|
|
|
|
H1 = 5 H2 = 1 + 1 + 0 + 0 + 0 + 1 + 1 + 2 = 6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Figura 10 - Il rompicapo dell'otto
Tuttavia, sono numeri troppo elevati; occorre quindi cercare di tagliare di molto la ricerca con delle buone euristiche.
. Due funzioni candidate sono :
H1 considera il numero di tessere che sono nella posizione sbagliata. In figura, sette delle otto tessere sono fuori posto, quindi lo stato iniziale avrà H1 = 7. Essa risulta essere un'euristica ammissibile in quanto è chiaro che qualsiasi tessera fuori posto deve essere spostata almeno una volta.
H2 considera la somma delle distanze delle tessere dalle posizioni che assumono nella configurazione obiettivo. Anche questa risulta essere un'euristica ammissibile in quanto qualsiasi mossa può avvicinare una tessera in una posizione più vicina all'obiettivo. Nel nostro esempio le tessere risultano essere in uno stato iniziale di
H2 = 1+1+0+2+2+1+1+2=10
Un modo per caratterizzare la qualità di un'euristica è il fattore di ramificazione effettivo b*. Se il numero totali di nodi espansi da A* per un problema particolare è N e la profondità della soluzione è d, allora b* è il fattore di ramificazione che un albero uniforme di profondità d dovrebbe avere per contenere N+1 nodi. Quindi,
Per esempio se A* trova una soluzione alla profondità 5 usando 52 nodi, allora il fattore di ramificazione effettivo è 1,92. Di solito tale fattore è abbastanza costante su un vasto insieme di istanze di problemi e quindi delle misurazioni sperimentali di b* su un piccolo insieme di problemi possono fornire una buona guida sull'utilità generale dell'euristica.
Un'euristica ben progettata dovrebbe avere un fattore di ramificazione vicino ad 1 consentendo di risolvere problemi abbastanza grandi. Ci si potrebbe chiedere se H2 è sempre migliore di H1. La risposta è si perché per qualsiasi nodo si ha che
H2(n) > H1(n)
Diciamo, in questo caso, che H2 domina H1. La dominanza si traduce direttamente in efficienza: quando A* usa H2 espanderà, in media, un minor numeri di nodi rispetto a quando userà H1. Quindi, è sempre meglio usare una funzione euristica con valori più alti, a condizione che non siano sopravvalutati.
Abbiamo visto che H1 e H2 risultano essere euristiche abbastanza buone per il rompicapo dell'8. Nascono spontanee due questioni :
Sappiamo come inventare una funzione euristica ?
E' possibile che un computer inventi meccanicamente tale euristica?
Nel nostro caso, H1 e H2 sono delle stime della lunghezza del cammino che rimane nel rompicapo dell'8, ma possono anche essere viste come lunghezze del cammino perfettamente accurate per versioni del gioco "leggermente" semplificato. Un problema con meno restrizioni sugli operatori è detto problema rilassato. Spesso il costo di una soluzione esatta per un problema rilassato è una buona euristica per il problema originale. Utilizzando questa tecnica di generazione di euristiche su problemi rilassati, recentemente è stato scritto un programma chiamato ABSOLVER che può generare euristiche automaticamente dalle definizioni del problema.
Un problema che però si incontra nelle generazioni di euristiche è che spesso non si riesce ad ottenere un'euristica "chiaramente migliore". Se per un problema è disponibile una collezione ammissibile di H1..Hm e nessuna di queste domina le altre risulta essere difficile scegliere un' euristica. Si preferisce pensare di scegliere la soluzione più accurata , definendo
H(n) = max (H1(n),.,Hm(n)).
Essa è un'euristica ammissibile in quanto le euristiche che la compongono sono ammissibili e domina le euristiche individuali di cui è composta.
Un altro metodo per inventare le euristiche consiste nell'utilizzare informazioni statistiche. Queste possono essere ottenute eseguendo una ricerca su un numero di problemi di addestramento, come le 100 configurazioni scelte a caso nel rompicapo dell'8, elaborando poi delle statistiche. Per esempio, potremmo scoprire che quando H2(n)=14, risulta che il 90% delle volte la distanza reale dall'obiettivo è pari a 18. Quindi, quando affrontiamo il problema reale, possiamo usare 18 come valore ogni volta che H2(n) vale 14.
3.3 Strategie informate
"L'intelligenza di un sistema non è misurabile in termini di capacità di ricerca, ma nella capacità di utilizzare conoscenza sul problema per eliminare il pericolo dell'esplosione combinatoria.Se il sistema avesse un qualche controllo sull'ordine nel quale vengono generate le possibili soluzioni, sarebbe allora utile disporre questo ordine in modo che le soluzioni vere e proprie abbiano un'alta possibilità di comparire prima. L'intelligenza, per un sistema con capacità di elaborazione limitata consiste nella saggia scelta di cosa fare dopo.....".
Newell-Simon:
"I metodi di ricerca precedenti in uno spazio di profondità d e fattore di ramificazione b risultano di complessità proporzionale a b d per trovare una soluzione in una delle foglie."
I "metodi di ricerca informata" permettono di applicare la conoscenza al processo di formulazione di un problema in termini di stati ed operatori. La conoscenza, generalmente, viene fornita da una funzione di valutazione che restituisce un numero che intende descrivere la desiderabilità (o la non desiderabilità) relativa all'espansione del nodo. Quando i nodi risultano essere ordinati in modo che venga espanso prima quello con valutazione migliore, la strategia risultante è detta ricerca best-first.
Function RICERCA-BEST-FIRST(problema,FN-VAL) returns una sequenza di soluzioni
Inputs: problema
Fn-val, una funzione di valutazione
Fn-In-Coda<- una funzione che ordina i nodi usando FN-VAL
Return RICERCA-GENERALE(problema,FN-IN-CODA
Una delle strategie più semplici di ricerca best-first è minimizzare il costo minimo per raggiungere l'obiettivo, ossia il nodo il cui stato è giudicato il più vicino all'obiettivo viene sempre espanso per primo. Il costo per raggiungere l'obiettivo da uno stato particolare può essere stimato ma non può essere determinato esattamente. Una funzione euristica che calcola tali stime di costo è di solito indicata con la lettera H.
H(n) = costo stimato del cammino più conveniente dallo stato del nodo n allo stato Obiettivo.
Una ricerca best-first che usa H per selezionare il nodo successivo da espandere è detta ricerca "golosa". Formalmente, H può essere una qualsiasi funzione, ma è richiesto che H(n)=0 se n è un nodo obiettivo.
La ricerca golosa preferisce seguire un singolo cammino fino all'obiettivo, ma tornerà indietro quando si imbatte in un vicolo cieco. Essa risulta essere non ottimale ed incompleta in quanto può cominciare su un cammino infinito senza mai tornare a tentare altre possibilità. La complessità temporale nel caso peggiore per la ricerca golosa è O(bm) dove m è la profondità massima del nostro spazio di ricerca. Inoltre, siccome mantiene in memoria tutti i nodi, la sua complessità spaziale è uguale a quella temporale.
3.5 Algoritmi con miglioramenti iterativi
Esistono problemi di difficile soluzione come ad esempio quello delle 8 regine, infatti si prenda una scacchiera [un quadrato da gioco di 8 caselle per 8, bianche e nere alternate] e si prendano otto Regine. Le Regine nel gioco degli scacchi possono catturare un pezzo muovendosi sulla scacchiera di un numero qualunque di caselle in ogni direzione: orizzontale, verticale, diagonale; posizionandosi indistintamente su caselle bianche o nere [negli scacchi quando un pezzo viene catturato il pezzo che lo cattura prende il suo posto e non come a dama dove avviene un salto]. Prese dunque 8 Regine, queste si possono disporre su una scacchiera in modo da non catturarsi a vicenda!
Figura 11 - Una possibile soluzione al problema
delle 8 regine

Per ottenere soluzioni a problemi come questo si possono applicare i cosiddetti algoritmi con miglioramenti iterativi, la cui idea di base è quella di partire con una configurazione completa ed apportare delle modifiche per migliorarne la qualità.
Questo tipo di algoritmi si dividono principalmente in due classi:
1) A SALITA PIU' RAPIDA oppure DISCESA DEL GRADIENTE;
2) SIMULATED ANNEALING
L'algoritmo a salita più rapida ad ogni passo si sposta in uno stato con funzione di valutazione maggiore, cioè si muove continuamente nella direzione del valore crescente. Infatti, se supponiamo che uno stato del problema possa essere rappresentato da un nodo, l'algoritmo è costituito in modo tale da controllare attraverso un ciclo se il valore del nodo successivo è maggiore del valore del nodo attuale, se la condizione è vera allora si muove nella direzione del valore più alto.
La struttura di dato "nodo" registra solo lo stato attuale e la sua valutazione. Per tale motivo questo tipo di algoritmo ha il problema di potersi trovare in una cosiddetta posizione di massimo locale, cioè una sommità che è più bassa del punto più alto nello spazio degli stati. In questo caso, l'algoritmo e fatto in modo da fermarsi a tale sommità con la conseguenza di aver raggiunto una soluzione non soddisfacente.
Se si verifica questo caso e l'algoritmo non fa progressi, allora si può provare a far ripartire l'algoritmo da un differente punto di partenza, l'algoritmo con tale modifica viene chiamato "algoritmo a salita più rapida con riavvio casuale".
Per evitare di trovarsi in una posizione di massimo locale si può applicare l'algoritmo di Simulated annealing che effettua alcuni passi in discesa per evitare tale massimo locale. Questo algoritmo invece di scegliere la mossa migliore sceglie una mossa a caso, se tale mossa migliora effettivamente la situazione, allora verrà eseguita con probabilità 1, altrimenti verrà eseguita con probabilità minore di 1, e di conseguenza la probabilità decresce esponenzialmente con la qualità della mossa. Per effettuare tali valutazioni vengono utilizzati due parametri, cioè tE che misura la quantità della mossa e T che determina la probabilità con cui la mossa viene eseguita.
Le quantità tE e T non sono state scelte a caso, infatti, l'algoritmo è stato sviluppato da un'analogia esplicita con la tempra o annealing, cioè il processo di raffreddamento di un liquido, fino alla solidificazione.
Il valore della funzione di valutazione in ogni stato corrisponde all'energia totale degli atomi del liquido. T corrisponde alla temperatura del liquido ed è funzione del tasso di abbassamento della temperatura. Se il tasso di raffreddamento è sufficientemente basso, il liquido raggiunge una configurazione a minima energia, questo corrisponde alla possibilità che l'algoritmo trovi una soluzione ottimale se il parametro T decresce con sufficiente lentezza.
L'algoritmo simulated annealing è stato applicato ampiamente nello scheduling delle fabbriche ed in altri compiti di ottimizzazione su larga scala.
La strategia di generazione e verifica è l'approccio più semplice tra quelli discussi: consiste dei passi descritti di seguito.
|
Algoritmo: Generazione e Verifica |
|
Si produce una soluzione candidata. Per alcuni problemi, ciò significa produrre un particolare punto all'interno dello spazio del problema, per altri significa produrre un cammino a partire da uno stato iniziale. Si verifica se questa è davvero una soluzione confrontando il punto selezionato o il punto d'arrivo del cammino selezionato con l'insieme degli stati finali accettabili. Se si è trovata una soluzione, si termina. Altrimenti si ritorna al passo 1. |
La Generazione e Verifica si effettua con la Produzione di una soluzione "Candidata"che può essere Sistematica oppure Casuale:
La soluzione sistematica produce una ricerca esaustiva nello spazio di ricerca che assicura la risoluzione del problema. La ricerca esaustiva nello spazio di ricerca può avere un costo molto alto.
La produzione di una soluzione "candidata" ci dà una soluzione effettiva al problema oppure una soluzione non valida al problema che fa ripetere la produzione .
In pratica, la Generazione e Verifica si può applicare insieme ad altri metodi che restringono lo spazio di ricerca.
3.7 Ricerca in salita
Il metodo di Ricerca in Salita è una variante del metodo di Generazione e Verifica, in cui il generatore di soluzione utilizza feedback proveniente dal processo di verifica al fine di decidere in quale direzione spostarsi all'interno dello spazio di ricerca.
|
Algoritmo: Ricerca in Salita - Versione Semplice |
|
Si valuta lo stato iniziale: se è una soluzione si termina; altrimenti si prosegue ponendo tale stato come lo stato corrente. Si intraprende il seguente ciclo finché o si trova una soluzione o non si può applicare nessuna operazione per generare un nuovo stato: a. Si seleziona un'operazione che non è ancora stata applicata allo stato corrente e la si applica producendo un nuovo stato. b. Si valuta il nuovo stato i. Se è una soluzione si termina. ii. Se non è una soluzione, ma è migliore dello stato corrente, esso diventa il nuovo stato corrente. iii. Se non è migliore dello stato corrente, si continua il ciclo. |
La Ricerca in Salita è un metodo locale quindi non ha una visione globale del problema. Questo metodo evita un'esplosione del problema, ma non assicura la soluzione del problema stesso.
La Ricerca in Salita si basa sull'applicazione di operazioni per passare da uno stato attuale nella risoluzione del problema ad uno stato migliore, oppure ad un migliore stato tra quelli adiacenti avendo in questo caso Ricerca in salita più ripida che si usa per valutare se un insieme di stati ha un basso costo.
Lo Stato Migliore è valutato tramite una funzione euristica che fornisce una stima di quanto lo stato è vicino alla soluzione.
Questo metodo ci porta o alla risoluzione del problema o ad uno stato da cui non è possibile passare ad uno stato migliore.
Lo stato da cui non è possibile passare ad uno migliore può essere il Massimo locale oppure un Pianoro:
Il Massimo locale è lo stato migliore dei suoi vicini ma peggiore di altri che provo a superare tornando allo stato precedente. Un caso particolare è il Crinale
Il Pianoro è un insieme di stati aventi la stessa stima che provo a superare applicando un insieme di operazioni senza fare la stima.
L'algoritmo porta ad uno di questi stati a causa del Metodo locale e/o di una funzione euristica non adatta.

Grafico di un Massimo Locale

Grafico di un Pianoro
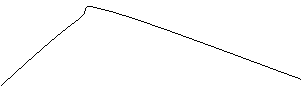
Grafico di un Crinale
3.8 Simulated annealing
Il simulated annealing (tempra simulata) è ispirato al processo di tempra di sostanze fisiche quali i metalli. L'obiettivo di tale procedimento è di raggiungere uno stato finale ad energia minima e, quindi, può essere descritto come processo di ricerca in discesa in cui la funzione obiettivo è costituita dal livello di energia.
Il metodo Simulated annealing è una variante della ricerca in salita e si basa quindi sul passaggio da uno stato nella risoluzione del problema ad uno migliore, ma a volte si ha il passaggio da uno stato ad uno peggiore valutato con una funzione euristica che fornisce la stima di quanto lo stato è vicino alla soluzione.
Tutto ciò accade con probabilità pari a P=e(-D E/T) dove:
DE = valore funzione stato corrente - valore funzione stato successivo. E' poco probabile il passaggio tra due stati con una grande differenza.
T si basa su una Tabella di annealing che :
fornisce il valore iniziale per T e un criterio per la sua variazione.
dipende dal problema.
Solitamente si ha che T è definito in modo che P sia alto solo all'inizio quindi i passaggi a stati peggiori avvengono all'inizio.
3.9 Ricerca lungo il cammino migliore
La ricerca lungo il cammino migliore sfrutta i vantaggi sia della ricerca in profondità sia della ricerca in ampiezza. In particolare, della prima sfrutta il vantaggio di poter cercare una soluzione senza andare ad esplorare tutti i cammini, mentre della seconda sfrutta il vantaggio di non rischiare di rimanere intrappolati in vicoli ciechi. Essa, infatti, combina questi due tipi di ricerca percorrendo un ramo alla volta con la possibilità di cambiare ramo quando si scopre che un cammino alternativo è più promettente di quello corrente.
La ricerca lungo il cammino migliore, in particolare, è molto simile al metodo della salita più rapida, con le differenze che le mosse alternative vengono riesaminate e, inoltre, non termina nel caso in cui il valore dello stato corrente è migliore di quelli di tutti gli stati successivi.
Questo tipo di ricerca può essere effettuata mediante Alberi, Grafi OR o Agende.
Gli Alberi esaminano più volte cammini che si ripetono. Essi, in particolare, operano, ad ogni passo, una selezione del nodo più promettente tra quelli generati fino a quel punto utilizzando una funzione euristica. La scelta si espande generando i successori del nodo attraverso una serie di regole a disposizione.
A questo punto, se uno dei successori generati è la soluzione, il processo termina, altrimenti, i nuovi nodi vengono aggiunti all'insieme dei nodi generati fino a quel punto e viene riapplicata la funzione euristica ripetendo il processo.
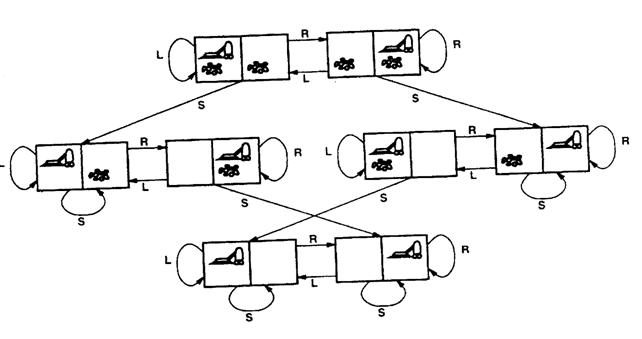
Esempio: Nella figura della pagina seguente (figura 12) si mostra la parte iniziale di una ricerca lungo il cammino migliore: inizialmente vi è un solo nodo, che viene quindi espanso generando tre nuovo nodi. Ad ognuno di essi si applica la funzione euristiche che, in questo esempio, è una stima del costo per raggiungere una soluzione a partire da un dato nodo. Essendo il nodo D quello più promettente, lo si espande generando due nuovi nodi, E ed F. Applicando ora la funzione euristica si scopre che un altro ramo, quello che passa attraverso B, è quello più promettente e, quindi, si espande B nei due nodi G ed H. Di nuovo, la valutazione di questi nodi fa sì che essi siano meno promettenti di un altro cammino, così da riportare la ricerca sul cammino che passa da D e porta ad E. L'espansione di E genera i nodi I e J e al passo successivo J viene espanso essendo il nodo più promettente. Il procedimento continua in questo modo fino a che non si raggiunge una soluzione.
Figura 12 - Ricerca lungo il cammino migliore

3.8.2 GRAFI OR
I Grafi OR valutano indipendentemente cammini multipli verso lo stesso nodo. Lo scopo di questi grafi è di trovare un singolo cammino verso una soluzione, utilizzando un particolare algoritmo (ALGORITMO 1).
|
Algoritmo 1: Ricerca lungo il cammino migliore |
|
Si inizia con la lista aperta che contiene il solo nodo iniziale. Si intraprende il ciclo seguente finché o si trova una soluzione o la lista aperta non contiene alcun nodo: Si seleziona il nodo migliore tra gli elementi della lista aperta; Si generano i successori del nodo prescelto; Per ognuno dei successori si effettuano i seguenti passi: i. Se non è stato generato in precedenza, lo si valuta, lo si aggiunge alla lista aperta e si memorizza il nodo che lo ha generato; |
|
ii. Se è stato generato in precedenza, se ne modifica il legame al genitore se il nuovo cammino è migliore del precedente. In questo caso si aggiorna il costo per raggiungere tale nodo e tutti i nodi successori che tale nodo ha generato. |
Tale algoritmo, però, fornisce una soluzione in maniera più lenta, per cui viene solitamente migliorato (ALGORITMO 2).
|
Algoritmo 2: Algoritmo A* |
|
si
inizia con la lista APERTA che
contiene il solo nodo iniziale. Si pone 0 il valore g per questo nodo, il valore di si
ripete la procedura che segue finché non si raggiunge una soluzione: se la
lista APERTA è vuota si termina con
un fallimento. Altrimenti si seleziona il nodo in APERTA con il valore più
basso di a) si introduce il legame tra SUCCESSORE ed il suo genitore NODO_MIGLIORE. Questi legami consentiranno una volta trovata una soluzione di ricostruire tutto il cammino. b) Si calcola g(SUCCESSORE) = g(NODO_MIGLIORE) + il costo per raggiungere SUCCESSORE da NODO_MIGLIORE. c) Si
controlla se SUCCESSORE coincide con un nodo nella lista APERTA (cioè è già
stato generato in precedenza ma non ancora esaminato). In caso affermativo si
associa tale nodo al nome VECCHIO. Poiché il nodo già esiste nel grafo,
possiamo ignorare SUCCESSORE e inserire VECCHIO nella lista dei succesori di
NODO_MIGLIORE. Dobbiamo però decidere se modificare il legame tra VECCHIO e il suo genitore, facendo diventare un
legame al NODO_MIGLIORE: ciò deve avvenire se il cammino attuale è meno
costoso del cammino migliore associato fino a questo punto a VECCHIO (dal
momento che VECCHIO e SUCCESSORE sono
in realtà lo stesso nodo). Dunque si controlla se è meno costoso raggiungere
VECCHIO passando attraverso il suo attuale genitore, o raggiungere SUCCESSORE
passando per NODO_MIGLIORE, confrontando i corrispondenti valori della
funzione g. se il valore associato
a VECCHIO risulta migliore non si deve fare nient'altro. Se invece è migliore
il valore associato a SUCCESSORE, NODO_MIGLIORE diviene il nuovo genitore di
VECCHIO, il costo del nuovo cammino trovato viene memorizzato in g(VECCHIO) e infine viene modificato d) Se
il SUCCESSORE no è in APERTA, si controlla se coincide con un elemento di
CHIUSA. In caso affermativo si associa quest'ultimo al nome VECCHIO e si
inserisce VECCHIO nella lista dei successori di NODO_MIGLIORE. Quindi si
verifica quale tra il cammino vecchio e quello nuovo è il meno costoso come
nel passo 2(c), e si memorizzano opportunamente il puntatore al genitore così
come i valori di g e e) Se
SUCCESSORE non fa parte ne di APERTA ne di CHIUSA, lo si inserisce in APERTA
e lo si aggiunge alla lista dei nodi successori di NODO_MIGLIORE; si calcola
infine |
L'algoritmo 2, in particolare, fornisce un cammino dei dati a costo minimo ed, inoltre, la soluzione viene fornita in maniera più rapida. Oltretutto, l'algoritmo 2 è ottimo, dato che genera il minor numero di nodi possibile nella ricerca di una soluzione al problema.
I Grafi OR, a differenza degli Alberi, non esaminano più volte cammini che si ripetono. Per fare ciò, viene utilizzato un algoritmo che opera su un grafo diretto in cui:
I nodi rappresentano punti nello spazio del problema e conterranno:
o una indicazione di quanto possa essere promettente quel cammino;
o un puntatore al nodo genitore che consente di ricostruire il cammino che ha portato alla soluzione;
o una lista dei nodi da essi generati che consente di propagare il miglioramento ai successori.
Ogni ramo rappresenta un cammino alternativo.
I Grafi OR, inoltre, richiedono:
Una lista di nodi. Tale lista si divide in due sottoliste:
o una lista aperta, che contiene i nodi già esaminati
o una lista chiusa, che contiene quei nodi che sono stati generati ed ai quali è stata applicata la funzione euristica ma non sono stati ancora esaminati.
Una funzione euristica f' = g + h' che associa una stima di merito ad ogni nodo generato in modo tale che la ricerca prosegua esplorando per primi i cammini più promettenti. In particolare, in tale funzione, si ha:
o g è uguale alla somma dei costi di applicazione delle regole utilizzate lungo il cammino migliore che porta al nodo e, quindi, non è una stima.
o h' è una stima del costo aggiuntivo necessario per raggiungere una soluzione a partire dal nodo corrente.
3.8.3 Miglioramenti all'algoritmo A*
Ricerca con approfondimento iterativo A* (IDA*)
|
Profondità |
Nodi |
Tempo |
Memoria |
|
|
|
millisecondi |
100 byte |
|
|
|
0,1 secondi |
11 kilobyte |
|
|
|
11 secondi |
1 megabyte |
|
|
|
18 minuti |
111 megabyte |
|
|
|
31 ore |
11 gigabyte |
|
|
|
128 giorni |
I terabyte |
|
|
|
35 anni |
111 terabyte |
Coloro che fanno analisi di complessità si preoccupano ogni volta che vedono una limitazione di complessità di tipo esponenziale O(bd). Osservando la tabella, si evidenzia il perché di tale preoccupazione dovuta ad un esosa richiesta di tempo e di memoria per una ricerca in ampiezza con fattore di ramificazione b=10 e per vari valori del fattore profondità d. Essa evidenzia inoltre che possono essere espansi 1000 nodi al secondo con un richiesta per ogni nodo di circa 100 byte di memoria. Si tenta quindi di trasformare la ricerca A* attraverso un approfondimento iterativo in una ricerca IDA* con una notevole riduzione dei requisiti di memoria. In questo algoritmo, ciascuna iterazione è una ricerca in profondità proprio come nel normale approfondimento iterativo. La stessa ricerca, però, è modificata per utilizzare un limite di costo f invece di un limite di profondità. Perciò. Ciascuna iterazione espande tutti i nodi dentro la frontiera che ha costo corrente f, dando un'occhiata per scoprire dove sia la frontiera successiva. Una volta completata la ricerca all'interno di una determinata frontiera, viene cominciata una nuova iterazione usando un nuovo costo f per la frontiera successiva. IDA* è completo e ottimale, ma poiché è un algoritmo in profondità, richiede solo uno spazio proporzionale al percorso più lungo che esplora. Sfortunatamente, IDA* mostra delle difficoltà in domini più complessi come nel caso del problema del commesso viaggiatore dove all'espansione di N nodi, l'algoritmo eseguirà N iterazioni e quindi espanderà 1+2+3+.+N=O(N2) nodi.
|
Function IDA*(problema) returns una sequenza di soluzione Inputs problema, un probelma Local variablesflimite, il limitef-costo corrente Radice, un nodo Radice<- Costruisci-Nodo (Stato Iniziale[problemal) flimite*-fCosto[radicel Ioop do soluzione,flimite<-DFS-Frontiera(radice, flimite) if soluzione non è null then return soluzione iff limite =a~ then return fallimento; end |
Le difficoltà di IDA* in certi spazi di problemi possono essere ricondotte all'uso di una memoria troppo piccola. Tra le iterazioni, viene memorizzato solo u singolo numero, il limite del costo corrente f. Poiché non può ricordare la sua storia, IDA* è destinato a ripeterlo. Esso, però, può essere modificato per verificare la ripetizione di stati nel cammino corrente, ma non è in grado di evitare la ripetizione di stati generati da percorsi alternativi. Questa modifica è realizzata nell'algoritmo SMA*(Simplified Memory Bonded A*) che può far uso di tutta la memoria disponibile per realizzare la ricerca. Usare più memoria può solo determinare un miglioramento dell'efficienza della ricerca cercando di ricordare un nodo piuttosto che doverlo rigenerare quando è necessario. SMA* ha le seguenti proprietà :
Utilizza tutta la memoria che gli viene resa disponibile
Evita di ripetere gli stati per quanto gli consenta la sua memoria
E' completo se la memoria disponibile è sufficiente a memorizzare il cammino di soluzione più superficiale
E' ottimale se è disponibile memoria sufficiente a memorizzare il cammino di soluzione ottimale più superficiale altrimenti restituisce la soluzione migliore che possa essere raggiunta con la memoria disponibile.
Quando è disponibile abbastanza memoria per l'intero albero di ricerca, la ricerca è ottimamente efficiente.
Il progetto SMA* è semplice: quando deve generare un successore e non c'è memoria disponibile, si elimina un nodo dalla coda. I nodi che vengono eliminati sono detti nodi dimenticati e si preferisce eliminare nodi che sono poco promettenti avendo un alto costo f. Per evitare di esplorare nuovamente i sottoalberi che ha eliminato dalla memoria, memorizza nei nodi antenati delle informazioni sulla qualità del cammino nel sottoalbero dimenticato. In questo modo, rigenera il sottoalbero solo quando si dimostra che tutti glia altri cammini sembrano peggiori. Data una quantità di memoria ragionevole SMA* può risolvere problemi più difficili di A* senza causare costi addizionali in termini di nodi aggiuntivi generati. Tuttavia in problemi molto difficili accade spesso che SMA* venga forzato a spostarsi continuamente avanti e indietro tra un insieme di cammini e di soluzione candidate. Quindi il tempo aggiuntivo richiesto per rigenerazioni ripetute degli stessi nodi implica che problemi che sarebbero praticamente risolvibili da A* diventano intrattabili per SMA*.
3.8.4 Ricerca basata su agenda
Algoritmo per la ricerca basata su agenda |
|
Si esegue il seguente ciclo finché o si trovata una soluzione o l'agenda è vuota: a) Si sceglie nell'agenda il problema più promettente. Si noti che un problema può essere rappresentato nella forma più opportuna: può essere pensato come una definizione esplicita del prossimo passo da compiere o semplicemente come il prossimo nodo da espandere. b) Si esegue quanto indicato nel problema prescelto attribuendo ad esso la quantità di risorse determinata della sua rilevanza: le risorse importanti sono lo spazio e il tempo. L'esecuzione del problema genera molto probabilmente altri problemi (nodi successori), per ognuno dei quali si opera come segue: i. Se è già nell'agenda si controlla se la sua lista di giustificazioni contiene la nuova ragione d'interesse. In caso affermativo quest'ultima viene semplicemente ignorata, altrimenti la si aggiunge alla lista. Se invece non è già presente nell'agenda lo si inserisce in quest'ultima. ii. Si calcola il nuovo valore di significatività del problema, combinando opportunamente i pesi di tutte le sue giustificazioni. Non tutte le giustificazioni hanno necessariamente lo stesso peso: è spesso utile associare ad ognuna una misura di quanto è forte la corrispondente ragione per quel problema . sono proprio queste misure che vengono combinate in questo passo per determinare la valutazione complessiva del problema. |
Un'agenda è una lista dei possibili problemi che il sistema può affrontare, cui sono associate solitamente due cose: una lista delle ragioni che hanno contribuito ad individuarli (spesso chiamate giustificazioni) ed una valutazione della significatività complessiva del problema.
Le agende si usano quando non esiste una sola semplice funzione euristica che misura la distanza tra un nodo e una soluzione, inoltre sono utili per realizzare sistemi monotoni.
Un'ulteriore utilità di tali strutture è di fornire un ottimo meccanismo per integrare informazioni provenienti da svariate fonti in uno stesso programma, dato che ogni fonte aggiunge semplicemente problemi e loro giustificazioni all'agenda.
Quando opera con le agende, il sistema seleziona ad ogni ciclo il problema più significativo, lo analizza e, eventualmente, genera da esso nuovi problemi. Tale meccanismo corrisponde alla selezione del nodo più promettente nella ricerca lungo il cammino migliore.
E' importante, durante questo procedimento, mantenere l'agenda ordinata in base al peso e inserire i nuovi problemi al posto giusto. Quando le giustificazioni di un problema cambiano, bisogna ricalcolare il peso complessivo e spostare il problema nella giusta posizione della lista. Questo metodo, tuttavia, fa sì che una grande quantità di tempo venga utilizzato per mantenere ordinata l'agenda, anche se buona parte di questo tempo è sprecato dal momento che non è necessario mantenere l'agenda perfettamente ordinata: è infatti sufficiente conoscere il primo elemento.
Finora abbiamo visto strategie di ricerca per grafi OR sui quali vogliamo trovare un singolo cammino verso la soluzione. Queste strutture rappresentano il fatto che saremo in grado di giungere ad una soluzione a partire da un dato nodo se scopriremo come farlo seguendo uno qualunque dei rami che partono da quel nodo.
I grafi AND - OR sono strutture, utilizzate dai metodi di ricerca, che si applicano a problemi scomponibili in sottoproblemi, che dovranno poi essere tutti risolti; generalmente sono costituiti da nodi e archi.
I nodi rappresentano i sottoproblemi, ad ognuno di essi è associata una funzione euristica, che ne determina il costo. Inoltre possono essere etichettati come risolto o intrattabile.
L'etichetta "risolto" si ha se il suo costo è nullo oppure se è padre di nodi risolti.
L'etichetta "intrattabile" si ha se il suo costo è maggiore del costo limite della soluzione.
Gli archi si dividono in: archi semplici o archi AND. I primi rappresentano una scelta alternativa nel ricercare la soluzione del problema. Gli archi AND, invece, puntano ad un insieme di nodi successori che devono essere tutti risolti per essere parte della soluzione del problema.
In generale la soluzione del problema si ottiene tramite un algoritmo di ricerca. Tale algoritmo, che solitamente è una variante di AO*, deve trovare il cammino migliore che parte da un nodo iniziale e arriva ad un insieme di nodi che rappresentano gli stati soluzione. La sequenza di nodi che formano il cammino migliore viene scelta tramite un criterio, che valuta il costo del nodo e l'appartenenza del nodo al cammino migliore.
Algoritmo AO* |
|
L'algoritmo si articola nei seguenti passi: Inizialmente GRAFO è costituito dal solo nodo di partenza, che viene chiamato INIZ. Si calcola il valore h'(INIZ). Si ripete il seguente ciclo finché o INIZ è etichettato come RISOLTO o il suo valore h' non supera il COSTO-LIMITE; (a) si seguono a partire da INIZ gli archi marcati e si seleziona in tale cammino un nodo non ancora espanso, sia esso NODO; (b) si generano i nodi successori di NODO: se non esistono si assegna a NODO il valore di COSTO-LIMITE, indicando così che è intrattabile. Altrimenti per ogni nodo successore , sia esso SUCCESSORE, si opera come segue: i. si aggiunge SUCCESSORE a GRAFO; ii. se SUCCESSORE è un nodo terminale lo si etichetta come RISOLTO e si pone a 0 il corrispondente valore di h'; iii. se SUCCESSORE non è un nodo terminale si calcola il suo valore di h'. (c) si propaga all'indietro la nuova informazione come segue: sia S l'insieme dei nodi etichettati come RISOLTI o il cui valore di h' è stato modificato. S viene inizializzato a NODO e si ripetono le seguenti operazioni finché S non è vuoto: i. si seleziona in S, se possibile, un nodo tale che nessuno dei suoi discendenti in GRAFO è contenuto in S ; se tale nodo non esiste, si seleziona un nodo qualunque di S. Il nodo selezionato viene indicato con CORRENTE, e viene rimosso da S; ii. si calcola il costo di tutti gli archi uscenti da CORRENTE: per ognuno di essi il costo si ottiene sommando i valori di h' dei nodi all'estremità dell'arco più il costo dell'arco stesso. Tra i costi così calcolati il minimo viene assegnato a CORRENTE; iii. si marca l'arco che ha generato il costo minimo come migliore uscente da CORRENTE; iv. se tutti i nodo all'estremità dell'arco appena marcato hanno etichetta RISOLTO, si etichetta CORRENTE come risolto; v. se CORRENTE è etichettato RISOLTO od il suo costo è stato modificato, è necessario propagare il suo nuovo stato all'indietro nel grafo, aggiungendo ad S tutti i predecessori di CORRENTE; |
L'algoritmo utilizza una struttura GRAFO, che rappresenta la porzione dello spazio di ricerca generato. Ad ogni nodo viene associato un valore h' che rappresenta la stima del costo di un cammino da quel nodo ad un insieme di nodi soluzione .
Durante l'espansione del cammino migliore vengono presi in considerazione i nodi che appartengono all'attuale cammino migliore.
Figura 13 - Esempio di applicazione dell'algoritmo
AO*
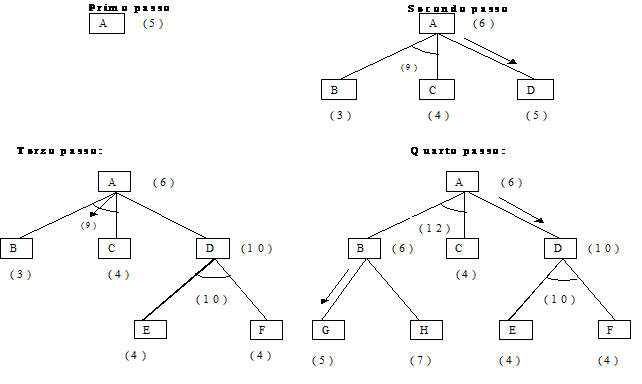
Al primo passo A è l'unico
nodo, e quindi rappresenta l'ultimo nodo del cammino migliore corrente. Al
secondo passo il nodo viene espanso, dando origine ai nodi B,C e D: l'arco D
viene marcato come più promettente poiché il cammino che porta a questo nodo è quello di costo minimo. I costi
sono considerati uniformi, in questo modo il costo associato ad un arco è uno,
e per gli archi AND il costo è dato dalla somma delle diramazioni uscenti dal
nodo. Al terzo passo viene espanso il nodo D, generando così il nodo AND di
costo 10, questo ci costringe ha rivalutare il costo associato al nodo D , ed
ai suoi predecessori. A questo punto l'arco B-C , il cui costo è 9
(7+2),diventa migliore dell'arco D, il cui costo è diventato 11 (10+1). La
successiva espansione porta a generare gli archi G e H. Propagando i valori di
costo all'indietro l'arco D torna ad essere di nuovo quello più promettente in
quanto il costo associato a B-C diventa 12 contro i 10 dell'arco D. Il
procedimento continua in questo modo finché o si trova una soluzione o si
scopre che tutti i cammini sono dei vicoli ciechi.
CAPITOLO 4
SODDISFACIMENTO DEI VINCOLI
4.1 Introduzione
Un problema con soddisfacimento di vincoli (CSP) è un particolare tipo di problema che soddisfa alcune proprietà strutturali aggiuntive oltre ai requisiti fondamentali dei problemi in generale.In una CS, gli stati sono definiti dai valori di un insieme di variabili e il test obiettivo specifica un insieme di vincoli a cui i valori devono obbedire.Una soluzione di un CSP specifica i valori per tutte le variabili in modo tale che i vincoli siano soddisfati.Ci sono diverse tipologie di vincoli. I vincoli unari riguardano il valore di una singola variabile, i vincoli binari mettono in relazione coppie di variabili.Infine i vincoli possono essere assoluti, la cui violazione esclude una soluzione potenziale, o vincoli di preferenza che dicono quali soluzioni si preferiscono.
Ogni variabile Vi in un CSP ha un dominio D, cioè un insieme di valori possibili che la variabile può assumere. Il dominio può essere continuo o discreto. Nella progettazione di una macchina, per esempio, le variabili potrebbero includere i pesi delle componenti (continui) e i fabbricati delle componenti (discreti).
Un vincolo unario specifica il sottoinsieme ammissibile del dominio ed un vincolo binario tra due variabili specifica il sottoinsieme ammissibile del prodotto cartesiano dei due domini.
Come si può applicare un algoritmo di ricerca generale ad un CSP?
Lo stato iniziale è lo stato in cui nono è assegnata nessuna variabile.Gli operatori assegneranno ad una variabile un valore scelto dall'insieme dei valori possibili. Il test obbiettivo verificherà se tute le variabili sono assegnate e se tutti i vincoli sono soddisfati.si noti che la profondità massima dell'albero di ricerca è fissata ad n,il numero di variabili, e che tutte le soluzioni sono a profondità n.
Nella realizzazione più semplice, in un dato stato può essere attribuito un valore a qualsiasi variabile non assegnata da un operatore,nel quel caso il fattore di ramificazione sarà la sommatoria dei Di per ogni i.
Poiché i CSP possono anche includere problemi NP-completi, avranno nel caso peggiore complessità esponenziale.La ricerca in profondità in un CSP è una perdita di tempo quando i vincoli sono già stati violati.Un operatore non può mai riconsiderare un vincolo che sia già stato violato.Il nostro primo miglioramento è di inserire un test prima del passo di generazione del successore per controllare se qualsiasi vincolo sia stato violato dalle variabili assegnate fino a questo punto. L'algoritmo risultante, chiamato ricerca con backtracking, torna allora indietro cercando qualcos'altro.
Cerchiamo di analizzare gli stessi problemi, considerando euristiche per selezionare una variabile da istanziare e per scegliere un valore per la variabile. L'idea intuitiva per la risoluzione di un CSP è quella di tener conto di quali valori sono ancora permessi per ciascuna variabile considerando le scelte fatte fino a quel momento. In ciascun punto della ricerca viene scelta la variabile con il minor numero di valori possibili per assegnarle un valore. Questa euristica prende il nome di variabile più vincolata che ci permette di risolvere problemi senza alcuna ricerca.
Un'altra euristica ammissibile è detta del valore meno vincolante che sceglie un valore che escluda il minor numero di valori per le variabili connesse da vincoli alla variabile corrente.
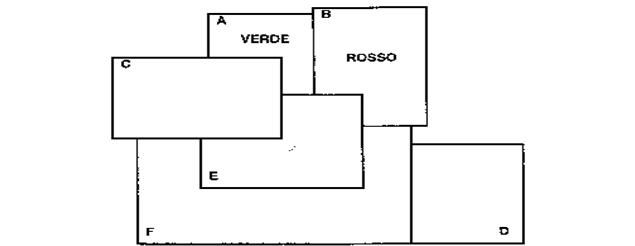
Esempio: Problema della colorazione di una mappa
Vincolo : Si vuole evitare la colorazione di regioni con lo stesso colore
Figura 14 - Problema di colorazione di una mappa
4.3 Algoritmo per il soddisfacimento dei vincoli
Molti problemi di IA possono essere visti come problemi di soddisfacimento dei vincoli, in cui cioè l'obiettivo è individuare uno stato del problema che soddisfi un dato insieme di vincoli, in modo da ridurre in maniera sostanziale il carico di ricerca da effettuare.
Una procedura di ricerca basata sul soddisfacimento dei vincoli opera in uno spazio formato da un insieme di vincoli: lo stato iniziale contiene i vincoli dati originariamente nella descrizione del problema. Uno stato obiettivo è uno che è stato "sufficientemente" vincolato, dove il significato di "sufficientemente" deve essere determinato a seconda del particolare problema.
Il soddisfacimento dei vincoli si divide in due passi. Il primo passo individua e propaga i vincoli il più possibile all'interno del sistema. La propagazione può terminare in tre casi, quando si giunge: alla soluzione del problema, ad una contraddizione o al limite della propagazione. Quando si raggiunge una contraddizione, il problema non ha soluzione. Se, invece, si raggiunge il limite della propagazione si riavvia la ricerca, andando al secondo passo. Il secondo passo effettua nuove ipotesi per rafforzare i vincoli, riprendendo la propagazione; questa può portare alla soluzione del problema oppure ad una contraddizione a causa di ipotesi errate. In quest'ultimo caso torno all'inizio del secondo passo e lo eseguo di nuovo.
Algoritmo: soddisfacimento dei vincoli |
|
Si propagano i vincoli disponibili. A tal fine, si inizializza APERTO all'insieme degli oggetti cui, in una soluzione completa, deve essere assegnato un valore. Quindi si ripetono le seguenti operazioni finché o si individua una contraddizione o APERTO è vuoto: a. Si seleziona un oggetto OB da APERTO e si rafforza il più possibile l'insieme dei vincoli che si possono applicare ad OB. b. Se tale insieme è diverso da quello assegnato ad OB l'ultima volta che è stato esaminato o se è la prima volta che si esamina OB, si aggiungono all'insieme APERTO tutti gli oggetti che condividono vincoli con OB. c. Si rimuove OB da APERTO. Se l'unione dei vincoli individuati al passo 1 costituisce una soluzione, si termina riportando tale soluzione. Se l'unione dei vincoli individuati al passo 1 determina una contraddizione, si termina riportando un fallimento. In tutti gli altri casi bisogna fare un qualche tentativo per procedere: a questo scopo si intraprende il seguente ciclo finché o si trova una soluzione o tutte le possibili soluzioni sono state scartate: a. Si seleziona un oggetto il cui valore non è ancora stato determinato e si individua un modo per rafforzare i vincoli che hanno a che fare con tale oggetto. b. Si invoca ricorsivamente il processo di soddisfacimento di vincoli sull'insieme corrente di vincoli aumentato con i vincoli rafforzati appena determinati. |
L'applicazione dell'algoritmo ad un problema specifico richiede l'utilizzo di due tipi di regole: regole che definiscono come si possano propagare correttamente i vincoli e regole che suggeriscano dei tentativi quando necessario. E' tuttavia importante sottolineare che per alcuni problemi specifici può non essere necessario effettuare dei tentativi. In generale possiamo dire che più sono potenti le regole per la propagazione dei vincoli, meno bisogno c'è di effettuare dei tentativi.
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2024