|
|
| |
GESTIONE DELLA MEMORIA: PARTIZIONI VARIABILI MULTIPLE
In questa tecnica (ormai abbandonata; ad esempio dalla famiglia INTEL, che ora adotta la tecnica della paginazione) a ciascun processo viene associata una partizione, ovvero una 'fetta' di memoria a indirizzi consecutivi, la cui lunghezza è dimensionata in modo che vi possano essere contenuti il codice, lo stack e i dati del processo stesso. L'illustrazione seguente permette di comprendere come evolve la gestione di memoria usando questa tecnica.

|
400K |
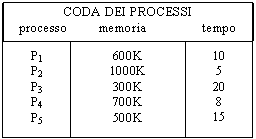
|
2560K |
Inizialmente in memoria c'è la parte 'vivente' del SO (cioè quella che è necessario che rimanga sempre residente in memoria) mentre risultano liberi i restanti 2160K. Devono essere caricati i 5 processi della tabella di destra; di consegue 151i85b nza, vengono allocate varie partizioni in modo dinamico. Il problema sorge nel momento in cui alcuni processi terminano liberando così il proprio spazio di memoria, o anche, qualora sia lecito, nel momento in cui alcuni processi già allocati richiedono una estensione della memoria ad esso assegnata. Nel primo caso si creano dei 'buchi' di memoria liberata; lo spazio libero non è più ad indirizzi consecutivi, ma la memoria risulta frammentariamente ripartita tra segmenti occupati e segmenti liberi. Naturalmente se due o più buchi di memoria sono adiacenti, è possibile collegarli per formare un unico buco più grande. Quando un nuovo processo deve essere allocato, occorre assegnargli uno fra i 'buchi di memoria' disponibili che sia idoneo a contenerlo. Vediamo come ci si comporta se sono disponibili uno o più buchi di memoria adatti. È necessario in tal caso individuare un criterio d'assegnazione; le strategia fra le quali è possibile scegliere sono tre: FIRST-FIT, BEST-FIT e WORST-FIT.
FIRST-FIT alloca il primo buco sufficientemente grande. La ricerca può cominciare dall'inizio dell'insieme di buchi, oppure dal punto in cui era terminata la ricerca precedente, e può essere fermata non appena viene individuato un buco libero di dimensioni sufficientemente grandi.
BEST-FIT alloca il più piccolo buco in grado di contenere il processo. La ricerca va effettuata su tutta la lista, a meno che questa sia ordinata per dimensione. Questa strategia produce le più piccole parti di buco inutilizzate.
WORST-FIT: alloca il buco più grande. Anche in questo caso è necessario esaminare tutta la lista, a meno che questa non sia ordinata per dimensione. Questa strategia produce le più grandi parti di buco inutilizzate, che possono essere più utili delle parti più piccole ottenute con la strategia best-fit.
Il primo criterio tende a far perdere meno tempo in quanto non sono effettuate ricerche. Il secondo tende a ridurre gli spazi vuoti, mentre l'ultimo tende a lasciare più spazio libero per altri eventuali processi. Non esiste un criterio ottimale per ciò che riguarda l'utilizzo di memoria, mentre si può affermare che firsi-fit è il più veloce. Tutte e tre le tecniche comunque presentano il problema della frammentazione esterna, ovvero della frantumazione dello spazio libero di memoria in piccole fette inutilizzabili. Può succedere cioè che non sia possibile allocare memoria ad un processo, dato che non c'è al momento un 'buco' abbastanza grande, nonostante il fatto che il totale della memoria libera ('somma' di tutti i buchi) sia sufficiente per le esigenze del processo in questione. È questo il motivo fondamentale per cui questa tecnica ha finito con il cedere il posto ad altre più idonee, in primis quella della paginazione.
Per risolvere la frammentazione esterna continuando a rimanere nel contesto delle partizioni multiple variabili si applica un intuitivo sistema di compattazione: lo spazio viene recuperato andando a ricompattare periodicamente la memoria, in pratica 'accorpando' lo spazio libero in un unico 'buco'. Questo si può fare però solo se il programma sia rilocabile, ovvero espresso mediante indirizzi relativi; in altre parole, è impossibile applicare la compattazione se l'allocazione del programma viene effettuata in fase di compilazione, assemblaggio o caricamento ed è quindi statica. Ad esempio nel sistema base + spiazzamento, la compattazione può essere realizzata facendo 'migrare' le partizioni occupate verso un'estremità della memoria e modificando il contenuto del registro di rilocazione (base) per i processi che sono stati spostati (esistono anche altre possibilità, sulle quali non ci soffermiamo). Tale swap non viene fatto direttamente all'interno della memoria, ma utilizzando un apposito canale, allo scopo di sollevare il processore da questo compito ed avere quindi un minore overhead.
Esiste poi una problematica di frammentazione interna, dovuta al fatto che un processo potrebbe andare ad occupare un buco che è di poco più grande rispetto al processo stesso, e lo spazio che rimane è troppo piccolo per essere gestito, in quanto la sua gestione (ovvero la registrazione della duplice informazione indirizzo di memoria - dimensione del buco, solitamente effettuata in un'apposita tabella) richiederebbe più spazio del buco stesso. Nella tecnica di gestione a partizioni multiple, il problema della frammentazione interna risulta trascurabile, mentre si fa sentire (talora pesantemente) quello della frammentazione esterna; nella tecnica della paginazione accade l'esatto contrario.
Un'alternativa alla compattazione consiste nel disporre di più registri base, in modo che uno stesso programma possa essere suddiviso in memoria in più parti, ad esempio allocando l'area programma, l'area stack e l'area dati in punti differenti della RAM (cioè ad indirizzi non consecutivi). In questo caso bisogna però fare uso anche di altri registri speciali, detti registri FENCE (= recinto, steccato) che servono a impedire la fuoriuscita degli indirizzi logici dalle aree assegnata al processo. Poiché occorre inibire l'invasione verso altre aree di memoria per ogni distinta sezione del processo, il numero dei registri fence deve aumentare con l'aumentare del numero dei registri di rilocazione.
Questa modifica fatta alla tecnica a partizioni variabili consente di introdurre il concetto di codice rientrante (ovvero di CODICE CONDIVISO) fra due processi. Ad esempio, consideriamo il caso di due utenti che lavorano su di un word processor scrivendo due lettere differenti. In pratica si tratta di due processi che lavorano sulla stessa area codice (il codice in LM del word processor) ma su aree stack e aree dati distinte (contenenti i testi delle due lettere). Ciò naturalmente è possibile solo se si hanno segmenti di memoria separati per istruzioni e dati.
GESTIONE DELLA MEMORIA: PAGINAZIONE
Questa tecnica consiste nel suddividere la memoria fisica in blocchi di dimensioni fisse, detti FRAME, e la memoria logica in blocchi di uguale dimensione chiamati appunto PAGINE. Quando un processo deve essere eseguito le sue pagine vengono caricate nei frame della memoria.
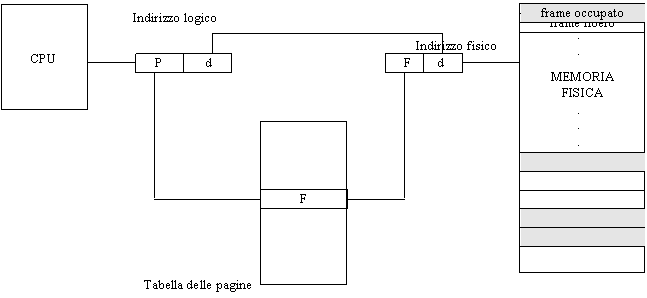
Ogni indirizzo generato dalla CPU è diviso in due parti: un numero di pagina (p), e un offset di pagina (d). Il primo serve da indice per la tabella delle pagine, che contiene l'indirizzo di ogni pagina nella memoria fisica. L'insieme di questo indirizzo e dell'offset di pagina permette di definire l'indirizzo dell'informazione desiderata nella memoria fisica, mediante il supporto hardware che viene schematizzato nella figura precedente. L'offset di pagina rappresenta lo spostamento rispetto alla prima locazione del frame che corrisponde a quella particolare pagina.
La dimensione di una pagina, uguale a quella di un frame, è definita dall'hardware (dato che essa coinvolge la memoria RAM) ed è in genere una potenza di 2. Il vantaggio di ciò è che in questo modo è immediato trarre a partire da un indirizzo logico l'insieme di un numero di pagina e di un offset. La parte di maggior peso dell'indirizzo logico rappresentano il numero di pagina, quella meno significativa rappresenta l'offset di pagina. Per facilitare le cose, facciamo un esempio con la base decimale: se l'indirizzo logico fosse 37273, e se ogni pagina logica fosse di 1000 K, allora l'indirizzo corrisponde alla pagina logica 37 e alla locazione di indice 273 (che è ad esempio una word) del corrispondente frame della memoria centrale (nel nostro esempio il frame di indirizzo 25).
Tabella
delle pagine
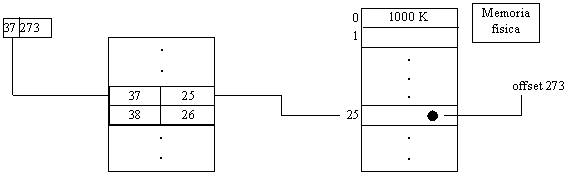
Il fatto che K sia piccolo o grande comporta, in riferimento alla gestione e alla frammentazione delle pagine, vantaggi e svantaggi, come vedremo in seguito. Si noti come per la presenza della doppia coordinata frame - offset lo spazio fisico in questo modello sia bidimensionale, mentre lo spazio logico è lineare.
Dal punto di vista pratico, il mapping viene eseguito a tempo di esecuzione (dinamicamente) mediante un dispositivo hardware simile a quello sopra descritto che considera i bit di maggior peso dell'indirizzo logico, sfruttandoli come entry per la tabella delle pagine, e ricava la pagina fisica corrispondente. L'indirizzo cosi ricavato non va sommato all'offset, ma giustapposto a quest'ultimo; nel nostro caso, si effettua dapprima una semplice sostituzione fisica di bit tra 25 (indirizzo frame) e 37 (indirizzo pagina logica); il numero 25 costituisce la parte alta dell'indirizzo che viene mandato sul bus che va verso la memoria, la parte bassa di tale indirizzo è 273.
Non è quindi necessario scomodare l'ALU per ricavare gli indirizzi di memoria e si evitano le conseguenti perdite di tempo. Questo però vale solo nell'ipotesi, che abbiamo fatto implicitamente, che le pagine fisiche siano disgiunte; diverso è ciò che avviene ad esempio nel processore INTEL 8086 che contempla invece la possibilità di sovrapporre le pagine fisiche, e quindi ad esempio di accedere ad uno stesso indirizzo fisico da due diverse pagine. Questa peculiarità, che indubbiamente complica non poco il mapping della memoria, fu realizzata dalla INTEL in previsione dei microprocessori più completi e veloci che sarebbero stati costruiti negli anni avvenire (famiglia 80X86).
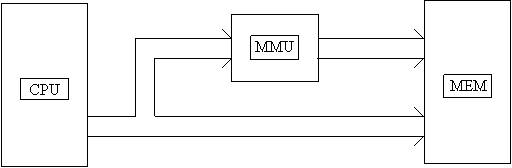
Il componente hardware incaricato di sostituire l'indice di pagina logica con l'indirizzo di pagina fisica può essere realizzato in vari modi. Nei sistemi meno recenti (anni '80) prendeva il nome di MMU ('Memory Management Unit'). Non è altro che una batteria di registri contenenti le corrispondenze fra pagine logiche e fisiche; naturalmente deve essere caricato con nuovi valori ad ogni context switch. I registri della batteria sono tanti quanto deve essere lunga la tabella delle pagine. Si osservi che L'MMU può essere collegato quale componente esterno a processori che non sono progettati internamente per gestire una memoria a pagine. Il discorso non è più fattibile se viene meno l'ipotesi di disgiunzione delle pagine fisiche: il problema va allora risolto all'interno della CPU e non esternamente ad essa.
Altra soluzione è quella in cui la tabella delle pagine è contenuta nella memoria stessa, e l'hardware è ridotto ad un solo registro speciale del processore (anziché un'intera batteria) che punta in memoria alla posizione di tale tabella. Per ottenere quindi l'indirizzo di un frame occorre sommare al contenuto di questo registro l'indirizzo della pagina richiesta (37 nell'esempio di cui sopra) e accedere in memoria all'indirizzo che ne consegue. Ogni processo possiede una propria tabella delle pagine, quindi al cambiare del processo running cambia dinamicamente il contenuto del registro, il quale punterà così ad un'altra tabella. Lo svantaggio evidente di questa alternativa sta nel suo richiedere degli accessi supplementari in memoria, la quale, come è noto, comporta tempi di accesso più lunghi rispetto ai registri hardware dedicati. D'altro canto si ha il vantaggio di eliminare ogni limite fisico per quanto riguarda il numero di pagine occupabili, eccetto ovviamente quello della dimensione fisica della memoria. Inoltre, i tempi di context switch diminuiscono sensibilmente.
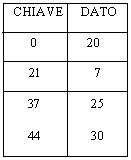
Una soluzione intermedia si ottiene con processori al cui interno non sono presenti né registri speciali né batterie di registri, ma che possiedono una MEMORIA ASSOCIATIVA: una memoria cioè nella quale l'accesso avviene per chiave e non per indirizzo.
Alla chiave 20 corrisponde la parola di
memoria 20
![]()
![]()
Quando ai registri associativi si presenta un elemento, esso viene confrontato contemporaneamente con tutte le chiavi. Evidentemente nella colonna 'chiave' figureranno le pagine logiche e nella colonna 'dato' quelle fisiche. La ricerca è estremamente veloce, ma il costo di realizzazione di un simile componente è elevato. Tuttavia la memoria associativa può essere utilizzata per contenere non l'intera tabella delle pagine, ma solo una sua porzione. Se si è 'fortunati' la chiave richiesta sarà presente in uno dei registri associativi e verrà immediatamente restituito l'indirizzo del corrispondente frame. In caso contrario non resta che rivolgersi alla tabella completa, che sarà registrata nella memoria centrale del sistema.
Il massimo della velocità media si ottiene costruendo un dispositivo hardware che prevede sia la memoria associativa sia il registro speciale che punta alla tabella completa delle pagine in memoria; l'accesso viene eseguito in parallelo: da un lato inviamo il numero 37 come chiave per la memoria associativa, dall'altro lato lo sommiamo all'indirizzo contenuto nel registro speciale per accedere alla giusta riga della tabella delle pagine residente in memoria. Si percorrono cioè entrambe le strade, quella veloce ma incerta della memoria associativa e quella sicura ma lenta della memoria RAM. Se la strada veloce ha successo, mandiamo un segnale di abort alla memoria RAM; in caso contrario lasciamo che l'operazione di accesso alla RAM prosegua, permettendoci di ottenere a tempo debito l'indirizzo della pagina fisica.
Posto t = tempo di accesso in memoria e t = tempo di accesso alla memoria associativa (si può porre ad esempio t = 0,1 * t), con questo marchingegno otteniamo un tempo medio di accesso che è (t + t) nella migliore delle ipotesi (l'indice di pagina fisica si trova nella memoria associativa, per cui occorre poi un solo accesso alla memoria centrale) e 2t nella peggiore (l'indice presentato si trova nella sola tabella delle pagine; per cui occorrono in totale due accessi alla memoria, uno per ricavare l'indirizzo del frame, l'altro per accedere alla locazione desiderata). Il tempo di accesso medio risulta essere:
(t + t) * p +2t * (1-p)
Dove p è la probabilità di avere successo con la memoria associativa. Dunque, il nocciolo della questione sta nel valore assunto da p. Se p è molto prossimo a 1 il tempo di accesso è dato da quello del caso migliore, t + t. Nella realtà si verifica che per la quasi totalità dei programmi risulta essere p ~ 0,8 ÷ 0,9, per cui il tempo di accesso T normalizzato su t vale all'incirca:
T ~ (t + 0,1 * t) * 0,9 + 2t * 0,1= 1,19t T / t ~ 1,19
Una probabilità p così alta di può realizzare nella maggior parte dei casi tenendo nella memoria associativa le pagine utilizzate più di recente. In tal caso il tempo di accesso medio risulta essere di poco superiore a t + t e in particolare uguale all'incirca a t + 0,2 * t.
La protezione della memoria è garantita dalla stessa logica del metodo utilizzato. Non è possibile che si verifichi un'invasione verso altre pagine, poiché avendo imposto che le dimensioni di pagina logica e fisica siano uguali non c'è modo di raggiungere indebite locazioni di memoria con l'insieme degli indirizzi frame e offset. L'unico registro fence di protezione occorrente è quello che impedisce all'indice di pagina logica di essere tanto grande da fuoriuscire dalla tabella delle pagine residente in memoria.
In più, questa tecnica non presenta alcun problema di frammentazione esterna ma può denunciare una forte situazione di frammentazione interna, in quanto mediamente l'ultima pagina di ogni processo è occupata solo per metà spazio. Si rifletta allora sul ruolo che riveste la dimensione K di una singola pagina: se K è piccolo diminuisce il tasso di frammentazione interna, ma la gestione diviene più onerosa, poiché aumenta il totale delle pagine da gestire.
LEZIONE N° 17 (DE CARLINI) - 17/4/97
Nella ultima lezione abbiamo visto la tecnica della paginazione, un'evoluzione della tecnica di gestione a partizione variabili, che presenta come proprietà fondamentale la non consecutività della spazio fisico (ovvero degli indirizzi fisici), mentre lo spazio logico che su di esso viene mappato continua ad essere ad indirizzi logici consecutivi. Lo spazio fisico viene ad essere costituito da blocchi o frame non necessariamente contigui in memoria, ma che possono essere dislocati a macchia di leopardo. Il meccanismo di mapping della memoria dello spazio logico su quello fisico funziona particolarmente bene nell'ipotesi che la lunghezza delle pagine sia una potenza di 2, e nell'ipotesi che non vi sia sovrapposizione di pagine fisiche, poiché in tale caso per effettuare il mapping non occorre nessuna elaborazione, se non una semplice sostituzione di parte dell'indirizzo logico con i corrispondenti bit esprimenti la pagina fisica.
Elemento fondamentale della paginazione è la tabella delle pagine, che fissa la corrispondenza pagina logica - frame. Un modo di implementarla è quello di conservare nella memoria centrale una tabella delle pagine per ogni processo, e di farla puntare da un apposito indirizzo memorizzato in uno dei campi del suo descrittore. Quando un processo diviene running, ovvero al verificarsi di un cambio di contesto, si copia il valore di quel puntatore dal descrittore di processi in un registro speciale. Tale operazione può essere fatta all'interno della CPU. In alternativa si potrebbe disporre di una batteria di registri speciali (MMU) in cui memorizzare la tabella [2]. La gestione migliore si realizza con l'insieme di una memoria associativa che contiene parte di quella tabella, e in parallelo un registro speciale che punta alla tabella delle pagine qualora la memoria associativa dia esito negativo. Si è trovato che mediamente sono sufficienti 16 registri associativi per avere una probabilità dell'80% di trovare il riferimento cercato. Tenendo la tabella in memoria si elude la limitazione costituita dal massimo numero di pagine che è obbligatorio imporre affidandosi al sistema della batteria di registri. D'altra parte, usando contemporaneamente una memoria a struttura associativa si riesce ad ottenere un tempo di accesso relativo abbastanza buono.
A queste informazioni, che dovrebbero essere già conosciute, aggiungiamo che il SO deve poter utilizzare un'altra struttura dati, denominata tabella dei frame, dimensionata questa volta non sul numero di pagine logiche ma sul numero di frame, che indica per ogni frame se è libero o in caso negativo a quale processo (o a quali processi) è allocato.
Vediamo ora di riassumere i vantaggi della tecnica della paginazione.
1) Qualora il codice di un processo sia separato dai dati, esso può essere condiviso con altri processi. Ciò, lo ripetiamo, è possibile solo se non ci sono pagine che contengono in parte codice e in parte dati. Invero, la tendenza ad accodare i dati al codice (o viceversa) in uno stesso frame è normalmente favorita, perché ha come effetto positivo quello di minimizzare la frammentazione interna. Se infatti con la paginazione mediamente mezza pagina per ogni processo risulta non utilizzata, separando codice e dati si perdono in media due mezze pagine e quindi una pagina intera. Da notare inoltre che il codice fra due processi può essere condiviso solo se è non rientrante, cioè se nessuna istruzione è in grado di modificarne un'altra, che essa vede come se fosse un dato.
2) La paginazione permette un efficace meccanismo di protezione. Non ci riferiamo al controllo della validità degli indirizzi, perché quello viene realizzato tramite il registro FENCE che evita di esorbitare dalla tabella delle pagine o, se si adottano una batteria di registri o una memoria associativa, tramite i bit di validità [3] ad esse collegati. Piuttosto, è possibile definire il genere di accesso consentito sulle pagine; ad esempio una pagina che contiene codice si può accedere solo in esecuzione (durante la fase FETCH dell'algoritmo fondamentale del processore), ad una pagina dati si può accedere solo in lettura (stavolta nella fase EXECUTE) o in scrittura (sempre durante la fase EXECUTE).
Il primo vantaggio menzionato comunque è presente anche nella tecnica delle partizioni variabili. Non così il secondo, che costituisce una peculiarità della paginazione.
Totalmente sballati apparivano i calcoli sugli appunti presi in classe: T t + 0,1 * t * 0,9 + 2t * 0,1 = 1,29 t (??) da cui T/t 1,29, e per di più c'era scritto che questo tempo di accesso medio poteva essere espresso come t + 3 t (ossia 4t che è ben maggiore di 2t, per cui questo 'marchingegno' dovrebbe essere certamente scartato!).
|
Privacy |
Articolo informazione
Commentare questo articolo:Non sei registratoDevi essere registrato per commentare ISCRIVITI |
Copiare il codice nella pagina web del tuo sito. |
Copyright InfTub.com 2024